







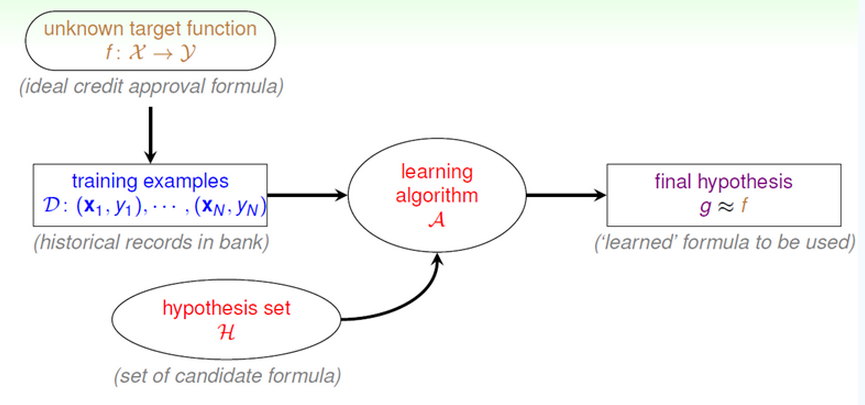
机器学习中,我们从样本数据出发,最后推断出接近真实规律的g(x)。
那么由样本数据推断出的g(x)可以接近真实规律的理论依据是什么呢?我们可以从概率的角度去解决这个问题。
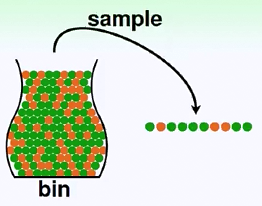
假设一个罐子(总体,bin)里面装满了两种不同颜色(orange,green)的小球。
假设P(orange) = u, P(green) = 1 - u
我们不知道bin里究竟有多少个球,各个球是多少,但我们可以随机抓一把小球,抽取一个样本(sample)
在这个样本中,通过数小球的具体数目(N),可以算出orange在样本中的概率v,green在样本中的概率1-v
根据Hoeffding's Inequality,
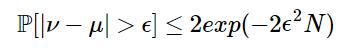
其中,ϵ是容忍度,N是样本数目,其中右边上限由ϵ以及N控制。当ϵ或N增大时,右边上限都会变小。
当右边很小时,我们就说v-u>ϵ的可能性很小,也即是v与u相差很大的可能性很小,也就是v与u差不多(PAC, probably approximately correct)
由此说明了从样本推断总体是可行的。
相应的,把它用于机器学习之中。
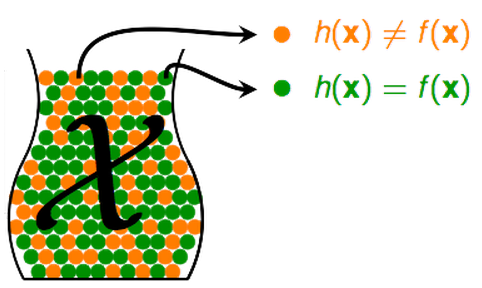
对于第n条数据,如果机器学习预测的结果与真实不一致,即h(xn)!=f(xn),则把它记为一个橘色小球。
如果一致,则把它记为一个绿色小球。
那么,我们用样本训练集中,h(x)预测的错误率(h(x)!=f(x)的比例),就可以推出 h(x)在总体中的错误率。
我们把样本中出现的错误率记为Ein(in sample error )
把总体中出现的错误率记为Eout(out of sample error)
对于任何一个固定的h(x),有如下关系
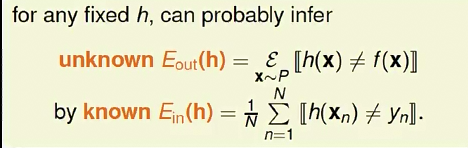
把Ein和Eout替换Hoeffding's Inequality中的v和u,有
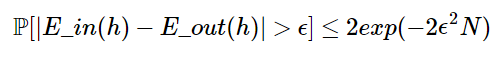
因此,当右边的上限足够小时,倘若Ein也足够小,则说明我们的机器学习确实学习到了东西。
注意到上面是对于一个固定的h(x)来说的,倘若hypothesis set中只有一个h1(x),则不能让学习算法A自由地挑选让Ein降低的h(x),这样机器学习是无意义的。
但是上面可以作为验证流程,假若算法A已经挑选了一个h(x),我们可以用上述方法来验证g(x)是否和真实的f(x)差不多。
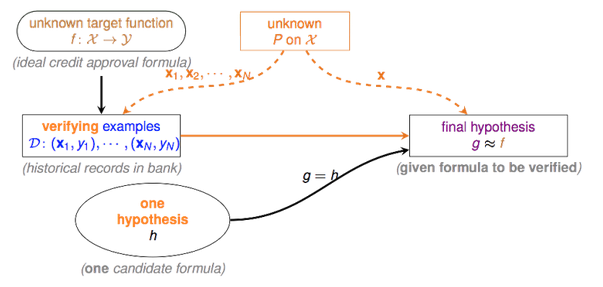
然而到了这里,还有尚解决的问题,抽样偏差。我们再次从概率的角度出发,考虑以下场景。
抛硬币,记录第i次抛硬币出现的正反面情况。
假设我们的抽样中,连续5次硬币出现的都是正面的情况(概率虽然小,但还是有可能发生),那么我们会作出抛出正面的概率是100%的结论。但是我们知道,实际上抛出正面的概率是50%。这种样本,我们称之为bad sample。
在机器学习中,我们同样会遇到这种情况,我们把这些不好的数据称之为bad data。机器学习需要在hypothesis set中选择一个最好的h(x), 但只要任意的h(x)遇上bad data,都有可能对选择带来影响。例如h1本来不是个好的选择,然而因为bad data,恰好导致Ein(h1)很小,导致A选择了它。
那么,bad data出现的概率是多少呢?
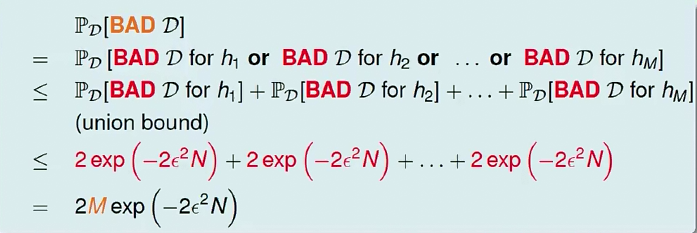
由此可知,遇上bad data是有界的。当M(hypothesis set中可选择的个数)有限,且N足够大时,遇上bad data的概率会很低。
总结:
当Ein与Eout足够接近,且Ein很小时,我们就能说机器学习确实学到了东西。而Ein低与否,与A在hypothesis set中的选择密切相关。当hypothesis set中的可选h(x) 越多,
就越有可能找到一个让Ein很小的h(x),然而M太多,却又会导致出现bad data的概率增大,从而在验证流程中可能又会发现Ein其实不是那么小。这些问题将在后面解决。














 4957
4957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









