







上章我们提到了当Ein与Eout足够接近,且Ein很小时,我们就能说机器学习确实学到了东西。而Ein低与否,与A在hypothesis set中的选择密切相关。当hypothesis set中的可选h(x) 越多,就越有可能找到一个让Ein很小的h(x),然而M太多,却又会导致出现bad data的概率增大,导致|Ein-Eout|>ϵ
还记得我们用了一个不等式来衡量bad data出现的概率:
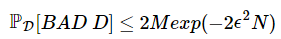
用一个不等式来衡量Ein和Eout是否接近
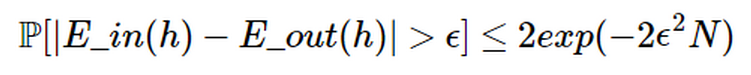
上述问题可以表示为:
1.我们是否可以确保Ein和Eout足够接近(hypothesis set中可选择的个数M有限,且N足够大)
2.我们是否可以把Ein弄得足够小(hypothesis set中可选择的个数M足够大)
而这两个问题中,M的数目是矛盾的。因此陷入了两难。
我们注意到,当M趋向于无限大时,bad data发生的概率会不断增大,因此我们不能处理M无限大的情况。为什么会这样呢,我们回想一下M是如何得出来的。
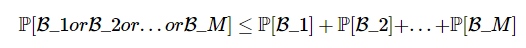
实际上,这里假
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6107
6107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









