






下载压缩解压后得到如下目录结构的文件夹:
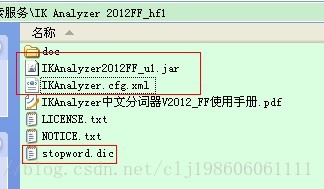
我们把IKAnalyzer2012FF_u1.jar拷贝到solr服务的solr\WEB-INF\lib下面。
我们把IKAnalyzer.cfg.xml、stopword.dic拷贝到solrhome需要使用分词器的core的conf下面,和core的schema.xml文件一个目录。
修改core的schema.xml,在<types></types>配置项间加一段如下配置:
- <fieldType name="text_ik" class="solr.TextField">
- <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
- </fieldType>
我们在这个core的schema.xml里面配置field类型的时候就可以使用text_ik了。
- <field name="name" type="text_ik" indexed="true" stored="true" multiValued="false" />
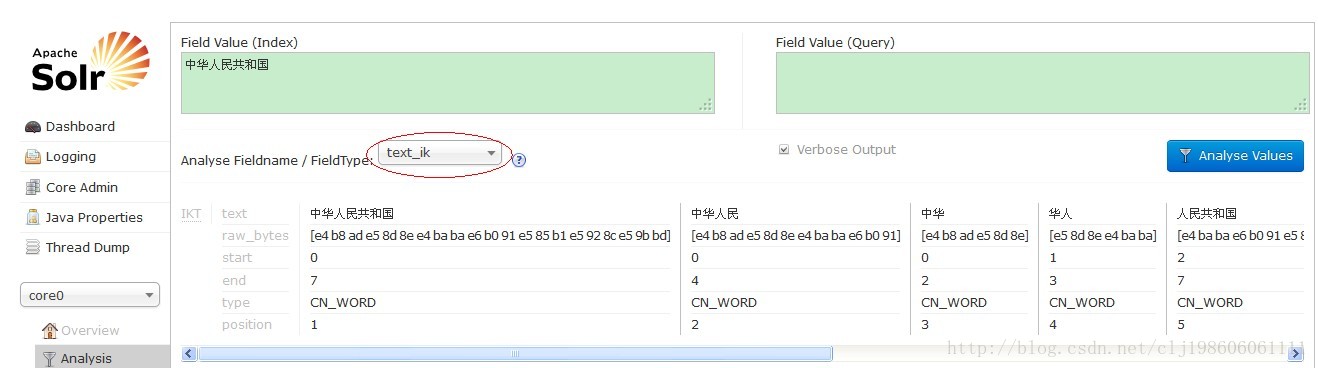
三、中文分词测试














 9995
9995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









