







语言模型技术广泛应用于语音识别、OCR、机器翻译、输入法等产品上。语言模型建模过程中,包括词典、语料、模型选择,对产品的性能有至关重要的影响。语言模型的建模需要利用复杂的模型公式进行模拟计算,是人工智能领域的关键技术之一。
曹立新,2011年7月毕业于哈尔滨工业大学计算机科学与技术专业,曾任百度语音资深研发工程师。负责百度超大语言模型训练,语音交互技术研发以及语音搜索、语音输入法、语音助手等产品的语音识别优化。
现在地平线负责语音识别、自然语言处理等相关技术算法研究。
语言模型的背景
语言模型是针对某种语言建立的概率模型,目的是建立一个能够描述给定词序列在语言中的出现的概率的分布。给定下边两句话:
“定义机器人时代的大脑引擎,让生活更便捷、更有趣、更安全”。
“代时人机器定义引擎的大脑,生活让更便捷,有趣更,安更全”。
语言模型会告诉你,第一句话的概率更高,更像一句”人话”。
语言模型技术广泛应用于语音识别、OCR、机器翻译、输入法等产品上。语言模型建模过程中,包括词典、语料、模型选择,对产品的性能有至关重要的影响。Ngram模型是最常用的建模技术,采用了马尔科夫假设,目前广泛地应用于工业界。
语言模型的技术难点
语言模型的性能,很大程度上取决于语料的质量和体量。和特定任务匹配的大语料,永远是最重要的。但是实际应用中,这样的语料往往可遇不可求。
传统的Ngram建模技术,对长距离的依赖处理的欠佳。如工业界常用的四元模型,即当前词的概率,只依赖三个历史词。因此,更远距离的历史词在建模中,没有对当前词概率产生影响。
此外,Ngram模型建模的参数空间过于庞大。同样以四元模型为例,词典大小为V,参数空间就是V4。实际应用中V大小为几万到几百万,可想而知,参数空间有多大。在这样的参数规模下,多大的数据显得都有些稀疏。
近年来提出的神经网络语言模型技术,一定程度上解决了参数空间大,长距离依赖的问题。而且对于相似的词,概率估计上自带一定程度的平滑,从另一个角度解决了数据稀疏的问题。但是神经网络语言模型的缺点是训练时间长,实际应用中查询速度较慢,需要结合硬件做加速。
Ngram语言模型
如上所说,Ngram语言模型是应用最常见的语言模型。它采用了n元依赖假设,即当前词的概率,只依赖于前n-1个词。即:
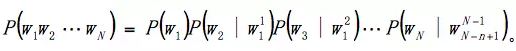
不考虑平滑,模型概率估计使用最大似然概率:
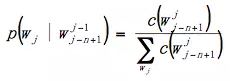
这种估计理解起来比较简单,即当前历史词下出现当前词,占当前历史词下出现所有可能词的比重。然而这种估计方法,会遇到我们上述提到的参数空间过大的问题。语料中不可能覆盖Vn个估计场景,肯定会有很多零点,如果使用最大似然,最后很多句子的概率都会是0,这会导致Ngram基本不可用。
平滑技术
平滑技术,可以说是ngram得以应用的重要原因,它很好地解决了参数空间大,数据稀疏的问题。工业应用中,最常用的是Katz平滑和KN平滑技术。
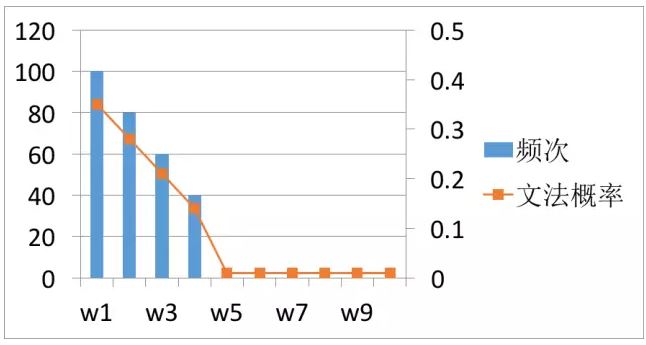
平滑理解起来很简单,就是把概率高的文法进行折扣,折扣出来的概率分给低概率的文法,即“劫富济贫”。以下图为例,即将w1到w4的概率,分给w5到w10。
加一平滑是最简单的平滑算法,可以帮助我们理解平滑的本质。所有的文法的频次都加1,这样就不存在概率为0的文法了。反之,高频词文法的概率得到了一定程度的降低。
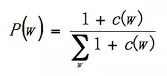
语言模型的评价指标
交叉熵和困惑度是用来评估语言模型最重要的两个指标。
交叉熵(crossentropy)的定义来自预测概率与压缩算法的关系,给定语言模型下可以得到一个压缩算法,对一个概率为p(s)的句子,用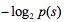
交叉熵一般用下面的公式计算,m为概率p的模型:
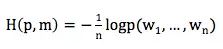
2H这个值即为困惑度(ppl)。从直觉上,我们可以把困惑度理解为在随机实验中选择随机变量的加权平均数。越小的困惑度对应一个越好的语言模型,语言模型的预测能力越强。
此外,实际产品中的性能,如语音识别中的字错误率,输入法中的句准确率等,也是衡量模型好坏的标准。
语言模型技术的最新进展
语言模型的最新进展,主要集中在神经网络的应用上。Bengio最早提出nnlm,将几个历史词拼在一起作为输入,将当前词放在输出层作为目标。为了解决词典的高维数问题,nnlm利用了映射层,对输入进行降维。Nnlm属于连续型模型,自带平滑,对相同的词历史有一定的聚类功能,一定程度上增加了模型的鲁棒性。如果和ngram模型进行融合,实验中会获得进一步的提升。
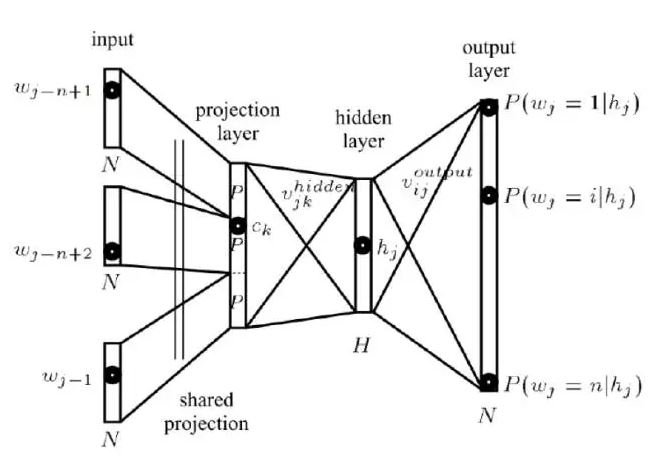
因Rnn在序列建模上有很大的优势,Mikolov在nnlm上的基础上,提出了rnnlm。Rnnlm将词历史抽象成一个state,降低了输入维数。此外,为了解决输出维数,将输出层的词进行聚类,通过因式分解,降低了计算复杂度。
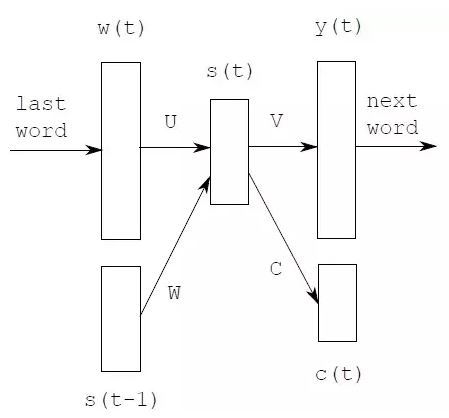
Mikolov的rnnlm之后,lstm、cnn在语言模型上也有研究陆续在跟进。此外,在输入层,引入语义特征,也会带来性能的提升。语言模型作为语音识别、OCR、输入法等产品中的重要模型,未来如何融合语义和产品、提升用户体验,我们充满期待。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









