







禹晓博+ 原创作品转载请注明出处 + 欢迎加入《Linux内核分析》MOOC网易云课堂学习
一、Linux中的进程简析
进程是任何多道程序设计的操作系统额基本概念,就像我们经常看到的关于进程的定义就是程序执行的一个实例,也是系统资源调度的最小单位。如何同一个程序被多个用户同时运行,那么这个程序就有多个相对独立的进程,与此同时他们又共享相同的执行代码。在Linux系统中进程的概念类似于任务或者线程(task & threads)。
实际上我们说进程是一个程序运行时候的一个实例实际上说的是它就是一个一个可以充分描述程序以达到了其可以运行状态的的一个数据和代码集合。一个进程会被产生并会复制出自己的子代,类似细胞分裂一样。从系统的角度来看进程的任务实际上就是担当承载系统资源的单位,系统在调度和分配资源的时候也会以他们作为基本单位开始进行分配。(系统中的资源很多例如CPU的时间片、内存堆栈等等)
当我们创建一个进程的时候,实际上系统就是在复制他的父进程,什么是他的父进程?我们知道程序或者进程执行的时候有的时候就会需要创建新的实例这个时候A如果新创建了B那么A就是B的父进程。实际上就是复制了几乎所有父进程的信息包括代码。子进程接收父进程地址空间的一个逻辑拷贝,(实际上就是可以理解为面向对象中的类创建实例的过程或者继承父类的这种关系,实际上他们看起来域属性是一样的但是又不会完全一样,所以我们说这里面是逻辑上的一个复制,后面会详细分析~)然后,这个子进程会从创建进程那个系统调用服务代码之后的下一条指令开始执行(ret_from_fork),执行代码与父进程是相同的。但是我们要知道实际上虽然AB都是指向相同的代码部分,但是正如我们知道的程序需要指令和数据,所以他们的数据拷贝是不同的,因此进程对一个内存单元的修改在AB之间是不可见的。以上是早期的时候情况,现代的系统实际上可能并不是这样的。在支持多线程应用的系统中很多拥有相对独立执行路径的用户程序共享应用程序的大部分数据结构。那么这样的话一个进程就是由几个用户线程组成,而且每一个执行线路就是一个线程。
那么进程在系统中的数据结构又是什么样子的呢?首先最应该知道就是系统如何管理这些进程,那么系统一定要有相应的数据结构去标识每一个进程以及他们的扩展数据结构(这里可以想象一下进程标识可能不会涵盖具体的执行代码和数据集合可能它仅仅是包含指向这些代码段和数据段的入口地址或者说是指针,事实上也是这样)大体上想想可以知道实际上这个结构就是我们在操作系统中所说的PCB(Process Control Block)在Linux中这个数据结构我们叫做task_struct,我们想想它实际上至少应该包括以下信息,比如优先级,它的运行状态,他所在的内存空间,它的文件访问权限等等,下面我们看一个教科书上的图片:
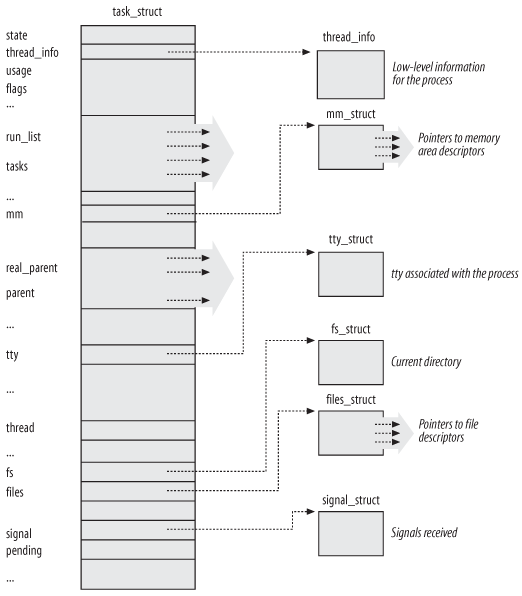
实际上我们看到他的结构还是很冗长的,不仅仅包含了很多进程信息的标识字段,同时又有很多的指针指向很多附件的数据结构。图中列出来的包括进程的基本信息thread_info、内存区域描述mm_struct、与进程相关的tty tty_struct、当前的目录fs_struct 、文件描述符files_struct、所接受的信号singal_struct等等。
1.1进程的状态
进程执行时,它会根据具体情况改变状态 。进程状态是调度和对换的依据。Linux中的进程主要有如下状态(上面图中的那个state字段)

(1)可运行状态
基于linux简洁优雅的性质,系统这里面不区分执行和ready两个状态,只要进程处于资源充足状态,就可以运行或者随时可以准备执行。而准备运行的进程只要得到CPU就可以立即投入运行,CPU是这些进程唯一等待的系统资源。
(2)可中断的等待状态
进程被挂起,直到等到一个可以唤醒他的东西,例如一个硬件中断、某项系统资源、或一个信号量。当它等到这些唤醒条件的之后就会进入可运行状态。
(3)不可中断的等待状态
实际上我们要理解为什么是不可中断的,一种常见的状态就是这个进程正在访问一个独占的临界资源,这种时候处于一种不可抢占的状态。通常当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或 SIGTTOU信号后就处于这种状态。例如,正接受调试的进程就处于这种状态。
(4)跟踪状态
没什么说的,就是一个进程正在被另一个进程监视,比如我们在调试的时候。
(5)僵死状态
进程虽然已经终止,但由于某种原因,父进程还没有执行wait()系统调用,终止进程的信息也还没有回收。顾名思义,处于该状态的进程就是死进程,这种进程实际上是系统中的垃圾,必须进行相应处理以释放其占用的资源。
我们在设置这些状态的时候是可以直接用语句进行的比如:p—>state = TASK_RUNNING。同时内核也会使用set_task_state和set_current_state。
1.2关于thread_info
进程是一个动态的东西,所以系统也是希望很有效率的进行管理。从这个方面去看thread_info结构与内核的堆栈放在一起(8k的一个页中)可以有一个很方便的好处就是系统很容易从esp寄存器找到这写CPU中正在执行的进程的thread_info的首地址。实际上就像我们猜到的一样他们既然总是在一个8k的页中,所以基于Linux简洁优雅的特性这些信息的地址分配肯定也是基于8K对齐的(什么叫对齐,嗯就是他们的起始地址都是8k整数倍)我们来再看一张教科书上的图( 哎呀怎么这么多教科书上图~恩恩笔者自己画的图都是会打码~不,啃啃打水印的哟
哎呀怎么这么多教科书上图~恩恩笔者自己画的图都是会打码~不,啃啃打水印的哟 ~后面就会有的呢)
~后面就会有的呢)
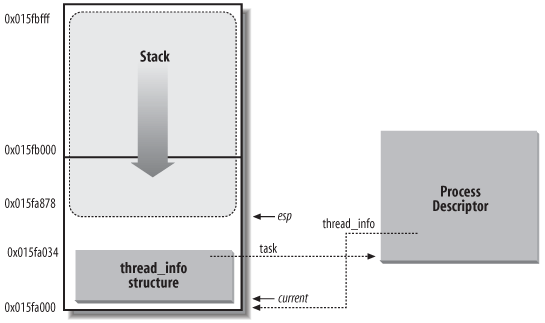
那么我们一看上面的图,嗯怎么都是0x015什么的开头的呢?没有错,对齐也是这种意思的呢,实际上我们知道如果地址只有2位的话就只能表示4个内存单元,如果有10位就是1024个内存单元就是1k的空间。那么8k呢就是13位地址空间。那么重点来了如何通过esp快速找到这些info呢?既然是8k的整数倍那么后13位就是一样的呢。我们可以先屏蔽低13位然后加上thread_info的页偏移量就可以了。嗯linux简洁优雅的性质又来了(额,这个词出现这么多!还整成红色简直是“干sang得xin漂bing亮kuang”,接下来不用了嗯),没有偏移量~有木有。所以我们只要屏蔽esp低13位就可以了。比如我们在源码中可以看到这样的一段指令:
movl $0xffffe000, %ecxandl %esp, %ecx
movl %ecx, p
1.3进程的创建
说了这么多大体上应该知道了一些关于进程的东西,接下来我们看看进程是如何创建的呢?我们实际上使用的是fork这个命令。╮(╯▽╰)╭为什么fork呢?因为进程的穿件就是想细菌复制一样,画一个一个分成两个,然后用复制自己创建新的,这样看起来就像个叉子一样,估计所以就叫fork了。我们首先来看一下从整体上看它的过程是这样的。

看着就眼熟吧,实际上我们看到了他就是一个系统调用的过程,参见我们上两个文章我们看到实际上他们的过程都差不多。具体代码的的执行过程示意图是这样的。

我们都知道,对于父进程 fork 返回子进程号,对于子进程 fork 返回 0 ,这也是执行路径如此的原因所在。但是, fork 的返回不同值的原因又是什么,这就得看 fork 的实现了。fork 先是调用 find_empty_process 为子进程找到一个空闲的任务号,然后调用 copy_process 复制进程, fork 返回 copy_process 的返回值 last_pid ,也就是子进程号。从上面的实现看来, fork 的返回值不会是 0 , last_pid 从 1 开始,父进程执行 if 外面的部分,上面的逻辑正是父进程的执行逻辑。
对于子进程,先看子进程的初始状态, copy_process 中创造了子进程的上下文执行环境,这个上下文环境正是父进程 fork 系统调用时的环境,其中, p->tss.eip 正是被赋值为 fork 之后下一条指令地址,这就是子进程和父进程都返回到 fork 下一条指令处的原因。同时,需要注意的是, p->tss.eax 被赋了值 0 ,当调度到子进程开始执行时,首先加载其上下文环境, eip 被加载为 fork 之后下一条指令, eax 就被加载为 0 ,所以,对于子进程来说,和父进程唯一的区别就是返回值( eax )为 0 ,子进程执行 if 里面的部分。

二、实验过程
首先我们要将新的menuOS放入我们的实验楼系统中,如下图所示:

然后我们看到我们把新的文件test_fork替换了之前的test.c文件因为里面我们加入了新的命令就是fork用于我们之后的运行调试,然后我们 make rootfs 制作很文件系统。然后我们就可以调试了。

然后们开始设置一些主要的断点如下图:

这里面我们看到我们设置了do_fork copy_process这样的断点,n是next的意思我们可以一条条执行这些代码。

继续执行我们看到这里面会用一些条件判断和赋值的东西,比如将当先任务的thread_info是专为防止多处理器并发而引入的一种锁指向运行的那个模块之后将P指向的进程标识设为相应状态之后会设置一个自旋锁,这里面为什么要设置自旋锁呢?是专为防止多处理器并发而引入的一种锁,这里面涉及了IO操作我们看到所以就必须设置这种锁,之后的文章应该会讲到恩恩这里面不细细说。

文章前面说过了穿件一个进程实际上就是复制的过程,在ret_from_kernel_thread之前我们开袋实际上紫禁城的数据端被复制成用户数据段(实际上Linux只有四个段,分别是内核和用户态下的数据段和代码段)上图中从哪个内核态返回就是我们之前第三幅图中看到的它从内核返回到用户了。

然后继续调试我们可以看到就进入了汇编指令部分,包括它需要得到thread_info,重新设置标示符之类的。然后我们看到了之后还会执行调度函数将现在的执行的task赋值到task_struct中。
三、总结
可以看出,fork()中,内核并不立刻为新进程分配代码和数据物理内存页,新进程与父进程共同使用父进程已有的代码和数据物理内存页面。只有当以后执行过程中由一个进程一写方式访问内存时候被访问的内存页面才会在写操作之前被复制到新申请的内存页面中。另外在fork的最后是将任务设置成了就绪状态,由于fork()是一个系统调用,在系统调用部分system_call.s,可以看到在系统函数返回后,会调用调度函数schedule(),在schedule()中,就会检测到新进程的就绪状态,并用switch_to()切换到新进程进行执行。
具体过程是:首先在内存中申请一页内存存放进程控制块task_struct,并返回进程号nr,并在task数组的nr处存放task_struct的指针,还要将task的当前指针current指到nr处;然后将父进程的task_struct的内容复制到新进程的task_struct中作为模版;之后我们对task_struct中的信息进行修改,主要进行一下工作:设置父进程、清除信号位图、时间片、运行时间、根据当前环境设置tss(内核态指针esp0指向task_struct所在页的顶端)、设置LDT的选择子等(根据nr指向GDT中相应的ldt描述符)。 在之后我们要设置新进程的代码段、数据段的基地址和段长:更新task_struct中的代码开始地址:更新task_struct中局部描述符表中的代码段和数据段描述符。然后再复制父进程的页表目录项和页表:在页目录表中,复制父进程的页表目录项,目的地址由新进程的线性地址计算出来;对每个对应的页表目录项申请一个空闲页,并用页表地址更新页表目录项,最后将父进程页表中各项复制到新进程对应的页表中,也就是说,这个时候,子进程与父进程共享物理内存。并且更新task_struct中的文件信息:文件打开次数加1,父进程的当前目录引用数加1。还要设置TSS和LDT描述符项:在全局描述符表(GDT)中设置新任务的TSS描述符项和LDT段的描述符项,使TSS描述符项和LDT描述符项分别指向task_struct的TSS结构和LDT结构。最后我们将任务设置为就绪状态,向当前进程(父进程)返回新进程号。
最后总结一下,Linux进程的创建过程就是内存中进程相关资源产生的过程,就是clone的过程。例如task _struct、内核态堆栈、线型地址到物理地址的映射表、全局描述表(GDT)中的任务状态段,局部描述符表、代码段、堆、栈、参数全局变量等数据区什么的。上面提到的这几类资源中,很多都与task_struct有关,所以我想说一下task_struct。它是Linux的进程控制块,驻留在内存中,描述进程的基本信息,所以它是进程操作依据的重要数据结构。Linux中一般进程都是由现有的一个进程创建的,也就是我们所说的父进程,子进程。具体的创建是通过fork()实现的。
借鉴参考:
http://soft.chinabyte.com/os/51/12324551.shtml
DLUBRUCE ZHANG's Blog http://blog.csdn.net/dlutbrucezhang















 3785
3785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









