







上一节讲述了真实数据(csv表格数据)的查看以及如何正确的分开训练测试集。今天接着往下进行实战操作,会用到之前的数据和代码,如果有问题请查看上一节。
三、开始实战(处理CSV表格数据)
5、查看训练集的特征图像信息以及特征之间的相关性
上一节粗略地查看了数据的统计信息,接下来需要从训练样本中得到更多的信息,从而对数据进行一些处理。
查看训练集的特征图像信息
为了防止误操作在查看的时候修改了训练集,所以先复制一份进行操作。对longitude和latitude(经纬度)以散点(scatter)的形式输出,看数据的地区分布。
train_housing = strat_train_set.copy()
train_housing.plot(kind="scatter", x="longitude", y="latitude")
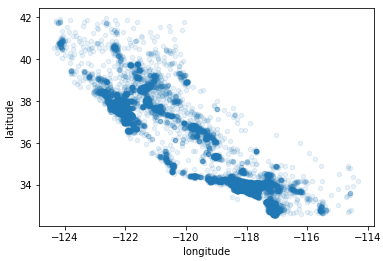
若加上参数alpha=0.1可以看到数据高密度的区域,若alpha设为1,则和上面一样,alpha越靠近0则只加深越高密度的地方。
train_housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
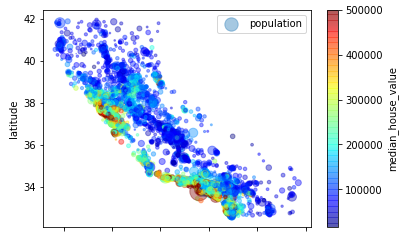
为了查看目标median_house_value的在各个地区的分布情况,所以可以增加参数c(用于对某参数显示颜色),参数s(表示某参数圆的半径),cmap表示一个colormap,jet为一个蓝到红的颜色,colorbar为右侧颜色条
train_housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
)
plt.legend()
查看特征之间的相关性
查看median_house_value与其他变量的线性相关性,并排序输出,数据越靠近1则越相关,靠近-1则越负相关,接近0为不相关。
corr_matrix = train_housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)

可以看到除了与自己最相关以外,和median_income线性相关性很强。
然而上面只是计算了线性相关性,而特征之间可能是非线性的关系,因此需要画出图来看一下变量之间是否相关。(代码中只取其中的几个来看)
from pandas.tools.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", &# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









