




上一节讲述了真实数据(csv表格数据)训练集的查看与预处理以及Pineline的基本架构。今天接着往下进行实战操作,会用到之前的数据和代码,如果有问题请查看上一节。
三、开始实战
7、选择及训练模型
首先尝试训练一个线性回归模型(LinearRegression)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(train_housing_prepared, train_housing_labels)训练完成,然后评估模型,计算训练集中的均方根误差(RMSE)
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(train_housing_prepared)
lin_mse = mean_squared_error(train_housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse
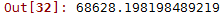
可以看到线性回归模型的训练集均方误差为68626
再试试看更强大的模型,决策树模型(DecisionTreeRegressor)
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor()
tree_reg.fit(train_housing_prepared, train_housing_labels)
housing_predictions = tree_reg.predict(train_housing_prepared)
tree_mse = mean_squared_error(train_housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
tree_rmse

可以看到决策树回归模型的的训练集均方误差竟然为0。比线性回归模型的的训练集均方误差小太多太多。
但这是否说明了决策树回归模型比线性回归模型在此问题上好很多,当然不是,训练误差小的模型并不代表为好模型,这是因为模型可能过度地学习了训练集的数据,只是在训练集上的表现好(即过拟合),一旦测试新的数据表现就会很差。
因此在训练的时候需要将部分的训练数据提取出来作为验证集,验证该模型是否对此问题适用。其中比较常用的就是交叉验证法。
交叉验证法
交叉验证的基本思想是将训练数据集分为k份,每次用k-1份训练模型,用剩余
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









