









HashMap的问题
HashMap是不支持并发操作的,多线程情况下HashMap可能会导致死循环的发生,导致CPU占用率达到100%。
Hash表的数据结构
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个
HashMap的源码
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
//计算Hash值
int hash = hash(key);
int i = indexFor(hash, table.length);
//如果存在值,替换旧值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//增加节点
addEntry(hash, key, value, i);
return null;
}上面代码是HashMap进行put一个元素时候的源码。
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果大小大于现在的threshold时候,需要resize
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}在增加节点时候会判断是否需要rehash操作。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//新建一个Hash Table
Entry[] newTable = new Entry[newCapacity];
//吧旧oldtable 迁移到新的newTable上
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}resize源码会新建个更大的hash表
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}迁移源代码
正常ReHash过程
就像代码中一样,新建一个新的table容量比oldtale要大,然后将oldtable中元素迁移到newtable中,在单线程下这样没什么问题。
并发下的Rehash
假设有两个线程,当第一个线程执行到
Entry<K, V> next = e.next;时候被挂起。
假设有三个值, <3,a>,<7,b>,<5,c>,HashMap的初始大小是2
______
|__0___| e next
______ _______ _______ _______
|__1___| ---> |_<3,a>_| -----> |_<7,b>_| -----> |_<5,c>_|那么现在线程1如下:
______
|__0___|
|__1___|
|__2___|
|__3___|那么线程2开始rehash:
______
|__0___| _______
|__1___| ----------> |_<5,c>_| ---------> null
|__2___| _______ _______
|__3___| ---> |_<7,b>_| -----> |_<3,a>_| ----> null
next e那么如果现在线程1被调度开始执行:
newTable[i] = e;
e = next;- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
______
|__0___| _______
|__1___| ----------> |_<5,c>_| ---------> null
|__2___| _______ _______
|__3___| ---> |_<7,b>_| -----> |_<3,a>_| ----> null
e next这样就会导致
线程1
______
|__0___| __________________
|__1___| | |
|__2___| ___|___ ____|__
|__3___| ---> |_<3,a>_| -----> |_<7,b>_| ----> null
产生循环链表,导致死循环。
concurrentHashMap原理
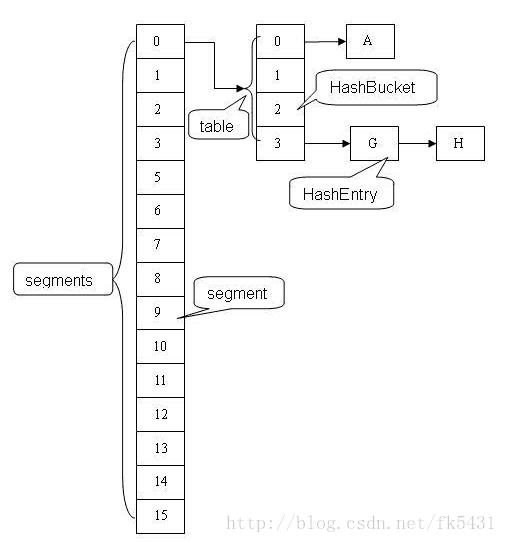
concurrentHashMap采用锁分段技术:假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
HashEntry源码:
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;volatile关键字保证了多线程读取的时候一定是最新值。
ConcurrentHashMap包含一个Segment数组,每个Segment包含一个HashEntry数组,当修改HashEntry数组采用开链法处理冲突,所以它的每个HashEntry元素又是链表结构的元素。
基本操作源码分析
构造方法:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS; //1
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1; //2
}
this.segmentShift = 32 - sshift; //3
this.segmentMask = ssize - 1; //4
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);//5
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; //6
UNSAFE.putOrderedObject(ss, SBASE, s0);
this.segments = ss;
}整个初始化是通过参数initialCapacity(初始容量),loadFactor(增长因子)和concurrencyLevel(并发等级)来初始化segmentShift(段偏移量)、segmentMask(段掩码)和segment数组。
注释1: 最大的并发等级不能超过MAX_SEGMENTS 1<<16(也就是1的二进制向左移16位,65535)
注释2: 如果你传入的是15 就是向上取2的4次方倍 也就是16.
注释3和4: segmentShift和segmentMask在定位segment使用,segmentShift = 32 - ssize向左移位的次数,segmentMask = ssize - 1。ssize的最大长度是65536,对应的 segmentShift最大值为16,segmentMask最大值是65535,对应的二进制16位全为1;
注释5和6: 初始化segment
初始化每个segment的HashEntry长度;
创建segment数组和segment[0]。
HashEntry长度cap同样也是2的N次方,默认情况,ssize = 16,initialCapacity = 16,loadFactor = 0.75f,那么cap = 1,threshold = (int) cap * loadFactor = 0。
get操作
public V get(Object key) {
Segment<K,V> s;
HashEntry<K,V>[] tab;
int h = hash(key); //1
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && //2
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}注释1: 根据key计算hash值
注释2: 根据计算出的hash值定位segment 如果segment不为null segment.table也不为null 跳转进里面的循环
里面的一大段东西 大致讲的就是通过hash值定位segment中对应的HashEntry 遍历HashEntry,如果key存在,返回key对应的value 如果不存在则返回null
put操作
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
return s.put(key, hash, value, false);
}判断值是否为null
计算hash值
定位segment 如果不存在,则创建
调用segment的put方法
还有一个putifAbsent的方法 ,唯一的不同就是最后的false变为了true
再来看看Segment的put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value); //1
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index); //2
for (HashEntry<K,V> e = first;;) { //3
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}注释1: 获取锁 ,保证线程安全
注释2:定位到具体的HashEntry
注释3: 遍历HashEntry链表,如果key已存在 再判断传入的onlyIfAbsent的值 ,再决定是否覆盖旧值.
最后释放锁,返回旧值.
再说明一下put 和 putifAbsent的用法
这两个方法本身是线程安全的,但是要看你的用法是否恰当
例子:
private static ConcurrentHashMap<String,AtomicInteger> map = new ConcurrentHashMap<>();
public static void putInTo(String key) {
AtomicInteger obj = map.get(key);
if(obj == null){
map.put(key, new AtomicInteger(0));
}else{
obj.incrementAndGet();
map.put(key, obj);
}
}这段代码可以用最开始提供的测试代码进行测试,会发现如果多个线程调用putInTo方法 最后值会确定不了,每一次都是不一样。 就算是保证原子性的AtomicInteger 也会有误差,可能误差比较小罢了。这个误差的出现就会出现在前几次的操作。
原因: 多个线程同时进入putInTo 比如线程1已经把不存在的键值对存入,而线程2还没完成操作 再继续存入key相同的键值对,从而覆盖了前面存入的数据,导致数据丢失。
这段代码就能保证线程安全 而不用通过synchronized关键字来锁定方法
private static ConcurrentMap<String, AtomicLong> wordCounts = newConcurrentHashMap<>();
public static long increase(String word) {
AtomicLong number = wordCounts.get(word);
if(number == null) {
AtomicLong newNumber = newAtomicLong(0);
number = wordCounts.putIfAbsent(word, newNumber);
if(number == null) {
number = newNumber;
}
}
return number.incrementAndGet();
}获取size
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow;
long sum;
long last = 0L;
int retries = -1;
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) { //1
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock();
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount; //2
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}注释1 : RETRIES_BEFORE_LOCK为不变常量2 尝试两次不锁住Segment的方式来统计每个Segment的大小,如果在统计的过程中Segment的count发生变化,这时候再加锁统计Segment的count














 6257
6257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









