







序
有些网站需要用户登录,利用python实现知乎网站的模拟登录。用Cookies记录登录信息, 然后就可以抓取登录之后才能看到的信息。
知乎登录首页
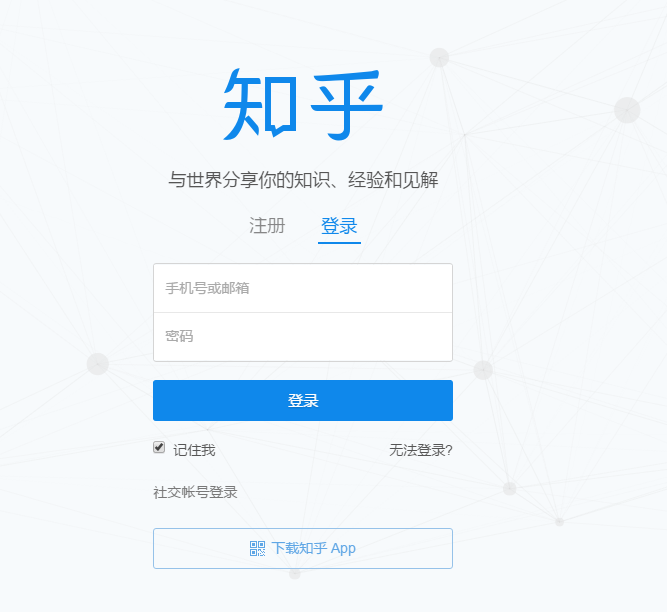
第一、使用Fiddler观察“登录”浏览器行为
打开工具Fiddler,在浏览器中访问https://www.zhihu.com,Fiddler 中就能看到捕捉到的所有连接信息。在左侧选择登录的那一条:
观察右侧,打开 Inspactors 透视图, 上方是该条连接的请求报文信息, 下方是响应报文信息:
1.1 请求header信息

1.2 用户登录信息
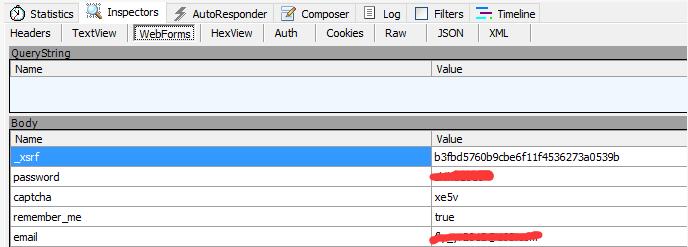
1.3 Raw显示请求报头原文

1.4下方:回应报文

第二、Python实现
2.1 抓取知乎首页
简单的写一个 GET 程序, 把知乎首页 GET 下来, 然后 decode() 一下解码, 结果报错. 仔细一看, 发现知乎网传给我们的是经过 gzip 压缩之后的数据. 这样我们就需要先对数据解压. Python 进行 gzip 解压很方便, 因为内置有库可以用. 代码片段如下:
import gzip
def ungzip(data):
try:  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6898
6898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









