







序
本文我实现的是一个CSDN博文爬虫,将我的csdn博客http://blog.csdn.net/fly_yr/article/list/1 中的全部博文基本信息抓取下来,每一页保存到一个文件中。
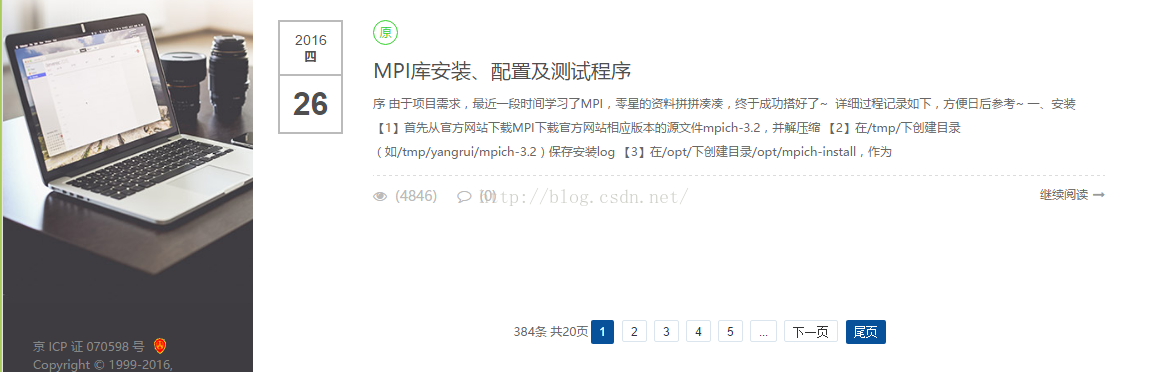
先来看一下我的博客页面(与选择的主题有关系哦,不同主题网页样式与源码是不同的~):
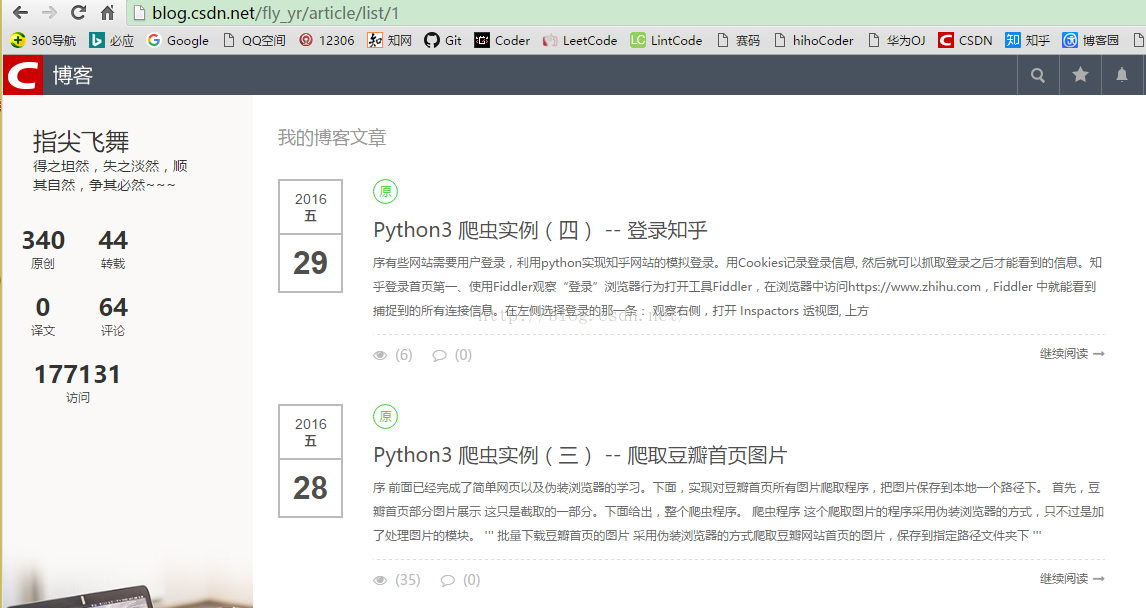
确定要提取的信息:
- 发表日期
- 是否原创标记
- 博文标题
- 博文链接
- 浏览量
- 评论量
从上第二个图中可以看出,我的博文目前有20页共384条数据,我们要把所有的博文都爬取下来,就要先获取总页数。
1. 确认URL
首先,我们确认好要爬取页面的url="http://blog.csdn.net/fly_yr/article/list/1";
然后,利用Fiddler工具查看访问csdn网站所需的报头:
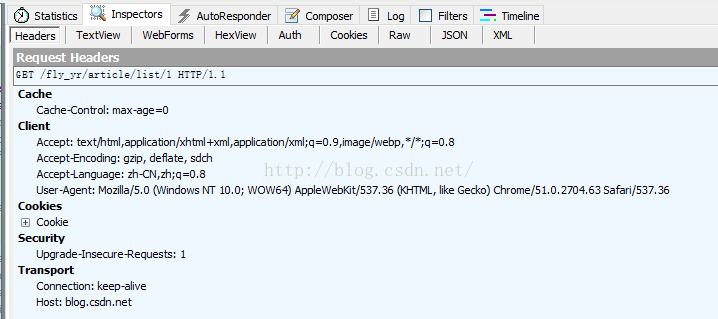
即:
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8",
"Host": "blog.csdn. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









