







在性能测试过程中,经常会遇到因重复提交或重复生成导致事务失败的问题,下面以下单重复的问题为例,对此类问题的定位和解决思路做一些总结。
一、问题现象
性能测试场景为下单,性能测试过程中,事务失败率过高,接近3:1;TPS曲线上下波动较大。
1. 下单失败的报错均为订单重复问题:此订单已经存在,请不要重复提交
2. TPS出现有规律的上下波动,如图:
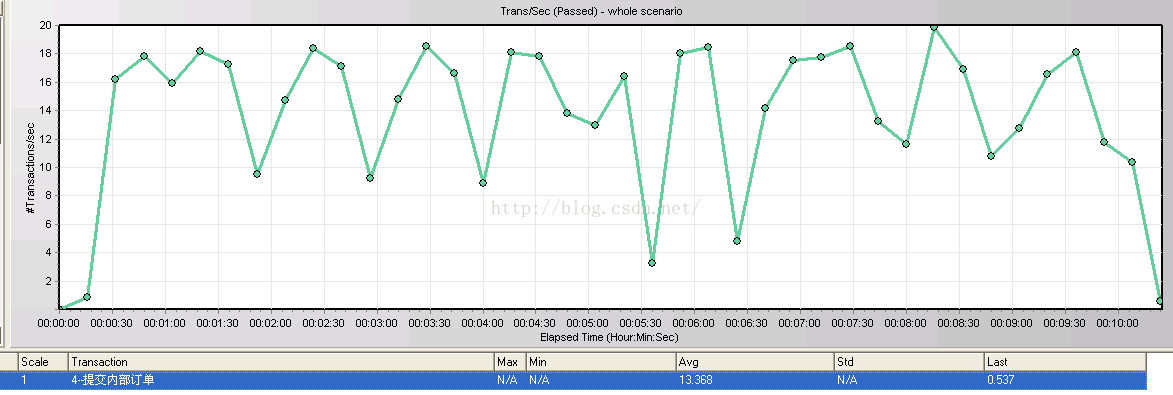
二、问题定位
1. 检查系统日志查看报错原因:在日志中找到因重复提交导致的定单号,通过检查数据库,发现此订单已成功插入数据库,因此重复提交必然会报错。
2. 检查性能测试脚本中是否有涉及订单号生成的参数,是否会有因参数设置导致生成重复的问题:经检查脚本中没有与订单号相关的参数,订单号由系统自动生成。
3. 检查系统订单生成规则,是否会存在大量提交的时候系统生成订单重复的问题:经检查,系统订单生成规则为2位固定前缀+yymmddhhmm+3位长度seq数值。
很明显,问题就出在订单生成规则这里,同一分钟内
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









