







MapReduce准确来说分为两个阶段,分别是map阶段与reduce阶段,map阶段负责抽取源数据文件,并向各个reduce task分发任务,机制是将相同key的数据,组成<key,value>对整合在一起输出到reduce阶段。reduce阶段则进行具体的处理过程,处理过程由一个或多个reduce task进行,其处理过后就是数据最终的处理结果。与平常的数据处理方式相比,mapreduce的好处在于“分而食之”,一个庞大的数据量对于普通数据处理方式而言无比困难,因为作为一个主机而言,处理如此庞大的一个数据对其硬件是有严格要求的,mapreduce则是以“宽度”换取“长度”,将大量数据分为多份数据,分发给各个reduce task并行处理,再将最后输出结果汇总,大量地节省了时间。
两个阶段如图所示:
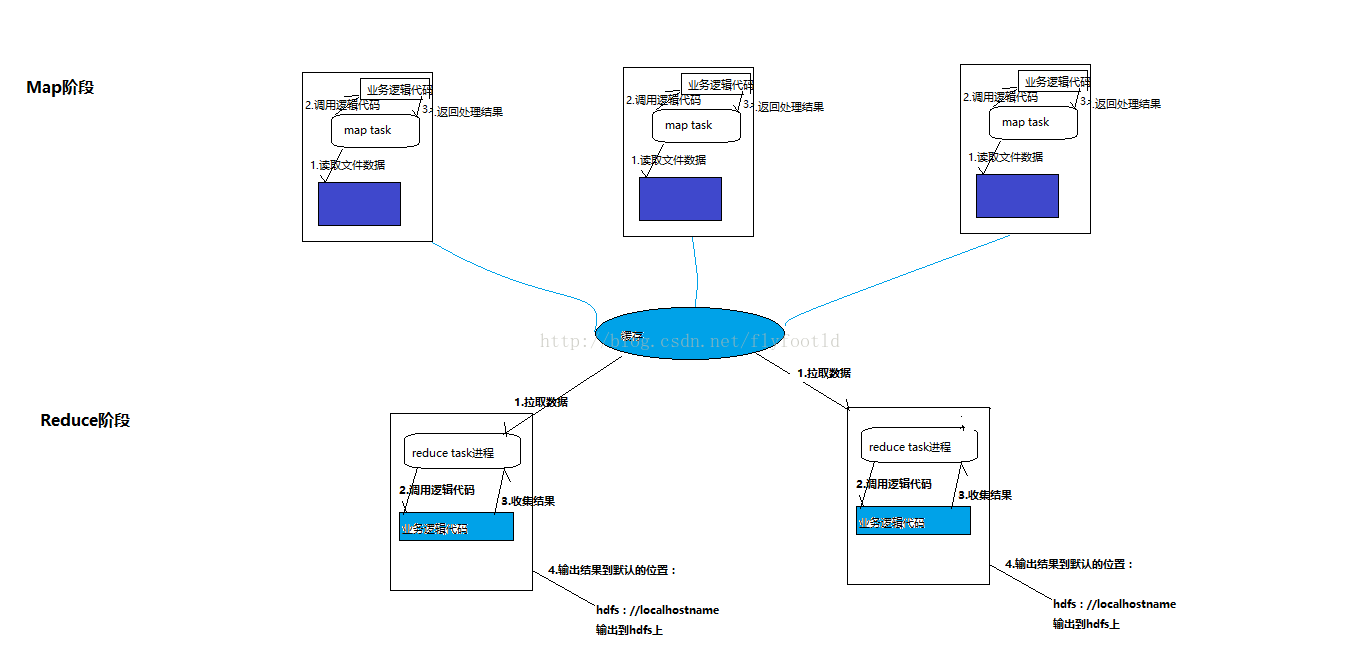
下面用几个例子来详细地示范mapreduce在实际代码应用中的过程,在mapreduce代码应用中,mapreduce主要构体分为三个部分:1,Map阶段;2,Reduce阶段;3.客户端引用阶段,下面有三个例子以供复习思考。
一.WordCount
wordcount是将一组文本数据中相同地字符出现地次数加以统计处理。其伪代码如下所示:
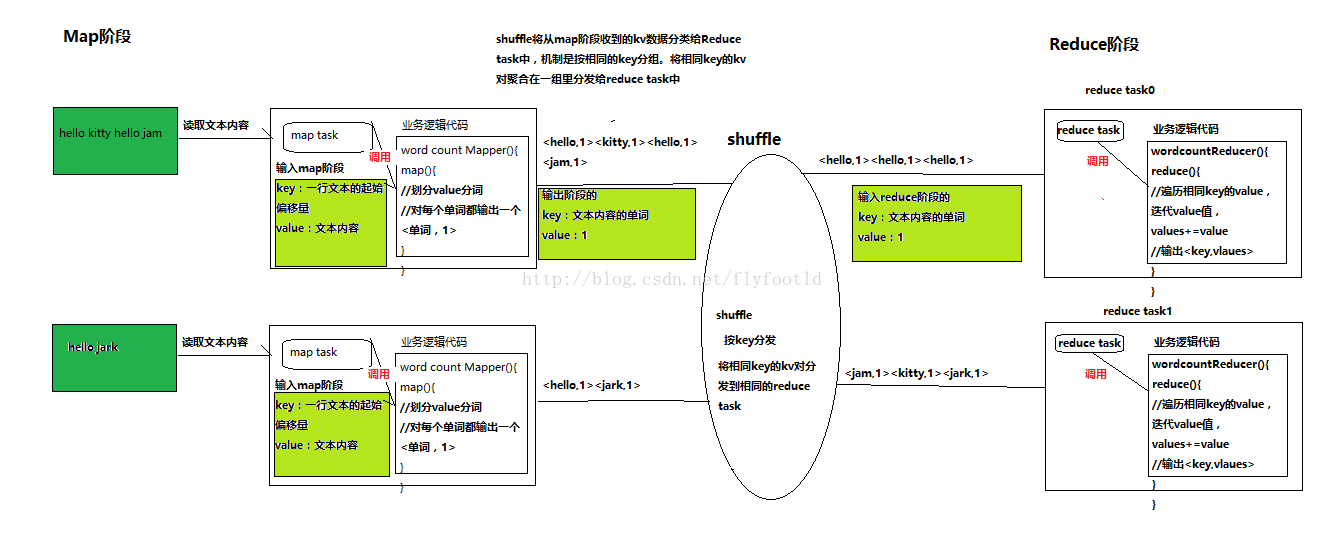
下面贴出wordcount的示例代码,分为三个板块。
一是map阶段的map task所要调用的业务逻辑代码,WordCounterMapper
package cn.itcasts.bigdata.wordcounter;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* KEYIN为输入数据中的kv对中的Key的数据类型
* VALUEIN为输入数据中的kv对中的value的数据类型
* KEYOUT为输出数据中的kv对中的Key的数据类型
* VALUEOUT为输出数据中的kv对中的value的数据类型
* @author Administrator
*
*/
public class WordCounterMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
/**
* map方法是提供给map task进程调用的,map task进程是每读取一行文本就调用一次自定义的map方法
* map task在调用map方法时,传递的参数:
* 一行的起始偏移量LongWritable作为key
* 一行的文本内容Text作为value
*/
@Override
protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException {
//拿到一行文本内容先转换为string类型
String line = value.toString();
//将这一行单词作切分
String[] words = line.split(" ");
//输出<单词,1>
for (String word: words) {
context.write(new Text(word), new IntWritable(1));
}}}二是Reduce阶段的业务逻辑代码,WordCounterReducer,示例如下:
package cn.itcasts.bigdata.wordcounter;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* keyin对应mapper阶段输出的key类型
* value对应mapper阶段输出的value类型
* KEYOUT:reduce阶段处理后输出的kv对的key类型
* VALUEOUT:reduce阶段处理后输出的kv对的value类型
* @author Administrator
*
*/
public class WordCounterReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
/**
* reduce方法是用来给reduce task来调用的
*
* reduce task会将shuffle阶段传输过来的大量kv数据对进行聚合,聚合的机制是将相同的key的kv对聚合成一组
* reduce task对每一组进行聚合的kv对调用一次我们定义的reduce方法
* 比如:<hello,1><hello,1><hello,1><hello,1><Tom,1><Tom,1><Tom,1>
* hello 组会调用一次reduce方法,Tom组也会调用一次reduce方法
* 调用时传递的参数:
* key:一组kv对中相同的key
* values:一组kv对中所有相同key的value之和,一个迭代器
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
//定义一个计数器
int counter = 0;
//通过values这个迭代器,遍历这一组kv对中所有的value,进行累加
for (IntWritable value : values) {
counter += value.get();
}
context.write(key, new IntWritable(counter));
}
}
三是一个引用了两个业务逻辑代码的客户端,处在一个统筹全局的作用,负责map task与reduce task对业务逻辑代码的调度工作。WordCounterSubMitter示例代码如下:
package cn.itcasts.bigdata.wordcounter;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountJobSubmitter {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wordcountJob = Job.getInstance(conf);
//要指定wordcountJob所在的jar包
wordcountJob.setJarByClass(WordCountJobSubmitter.class);
//设置wordcountJob的mapper逻辑类
wordcountJob.setMapperClass(WordCounterMapper.class);
//设置wordcountJob的reduce逻辑类
wordcountJob.setReducerClass(WordCounterReducer.class);
//设置map阶段输出的kv对数据类型
wordcountJob.setMapOutputKeyClass(Text.class);
wordcountJob.setMapOutputValueClass(IntWritable.class);
//设置reduce阶段输出的kv对数据类型
wordcountJob.setOutputKeyClass(Text.class);
wordcountJob.setOutputValueClass(IntWritable.class);
//设置文本数据所在位置
org.apache.hadoop.mapreduce.lib.input.FileInputFormat.setInputPaths(wordcountJob, "hdfs://hadoop-LD-1:9000/wordcount/srcdata/");
//设置最终处理数据结果存放位置
FileOutputFormat.setOutputPath(wordcountJob, new Path("hdfs://hadoop-LD-1:9000/wordcount/output/"));
//提交job给hadoop集群
wordcountJob.waitForCompletion(true);
}
}
1,设置客户端所引用的业务逻辑代码所在的类,包括客户端自身所在的类;
2,设置map阶段与reduce阶段所输出的的值的数据类型,因为reduce阶段的输出相当于最终的结果输出,所以直接可以set到一个outputkeyclass与outputvalueclass方法;
3,设置客户端所要处理的数据存放位置与处理过后的数据存放位置。
在这三个代码完成之后,就可以将代码打包成jar,然后上传到linux虚拟机上,直接运行即可。
二,FlowCount
FlowCount是对一组手机流量信息的查询过程,源数据是一份日志文件,里面记录了大量手机号与其在一段时间内的流量信息,流量信息分为上传流量,下载流量与总流量。与WordCount相似,下面只列出不同之处。
1.输入map阶段的数据。key:是日志文件一行的起始偏移量。value:是日志文件一行的内容
2.输出map阶段的数据。key:是切分后的日志文件,也就是手机号。value:是从日志文件中抽取的流量信息upFlow与downFlow
**重点在于,由于输出的流量信息过多,所以我们可以自定义一个数据类型文件FlowBean
3.输入reduce阶段的数据,key与value与输出map阶段的key,value值相同。
4.输出reduce阶段的数据,key与输入相同为手机号,新的value值需要遍历相同key的所有value值然后叠加而成。
列出FlowBean数据类型文件。FlowBean文件如下:
package cn.itcasts.bigdata.flowcounter;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
/**
* FlowBean是自定义的一个数据类型,为了能在hadoop上成功运行,必须实现hadoop的序列化结构,
* 也就是实现一个端口
* @author Administrator
*
*/
public class FlowBean implements Writable{
private long upFlow;
private long downFlow;
private long sumFlow;
//因为反射机制的需要,需要构造一个无参构造函数
public FlowBean(){};
//构造函数快捷键alt+shift+s
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
/**
* 序列化方法:将我们所要传递的数据序列化为字节流
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
}
/**
* 反序列化方法:将数据字节流逐个恢复为我们要传递的数据
*/
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
}
//输出的数据格式
@Override
public String toString() {
return upFlow + "\t" + this.downFlow + "\t" + this.sumFlow;
}
}














 1705
1705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









