







Hadoop2.7.0学习——Windows下hadoop-eclipse-plugin-2.7.0插件使用
材料
已经安装好插件的MyEclipse
可参考Hadoop2.7.0学习——hadoop-eclipse-plugin-2.7.0插件安装
编译好的Hadoop2.7.0
http://pan.baidu.com/s/1dEMv0p7
hadoop安装目录,bin目录下结构
应该有hadoop.dll和winutils.exe

示例项目下载
示例项目下载:http://pan.baidu.com/s/1mhDtGSS
配置Hadoop路径


创建Map/Reduce项目



注意:如果没有配置Hadoop路径的话,新建时会需要配置Hadoop路径
修改hadoop源码
在src下创建相同路径,相同类,复制源码过来,修改对应内容


如果NativeIO.java类报错
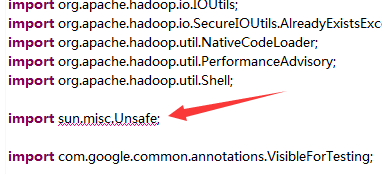
修改编译验证级别
选中项目-按alt+回车,按下图修改
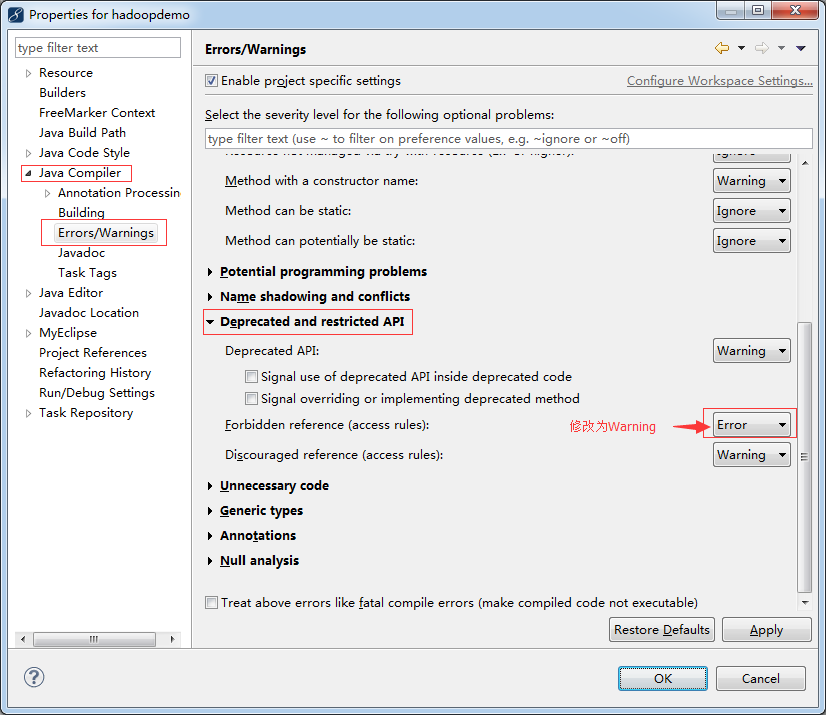
编写Map/Reduce程序
根据Hadoop权威指南(第三版)Map/Reduce例子改写
使用地震数据服务网数据,查询1999年1月至今,各月最大震级,各年最大震级和全时间段的最大震级
数据获取:http://www.csndmc.ac.cn/newweb/data.htm
earthquake_info.txt部分数据样式:
国家台网速报目录
日期 时间 纬度 经度 深度 震级 参考地点
(度.度)(度.度) (公里)
2016-08-05 00:24:33.9 25.00 141.97 520 M6.1 日本火山列岛地区
2016-08-04 22:15:10.4 -22.32 -65.90 250 M6.0 阿根廷
2016-07-31 19:33:22.8 -56.30 -27.56 100 M5.8 南桑威奇群岛地区
2016-07-31 17:18:11.2 24.08 111.56 10 M5.4 广西梧州市苍梧县
2016-07-30 05:18:23.2 18.44 145.56 200 M7.8 马利亚纳群岛
2016-07-29 22:02:48.3 21.86 99.79 8.2 M4.8 缅甸
2016-07-26 03:38:42.6 -2.90 148.13 10 M6.3 阿德默勒尔蒂群岛地区代码:
map类:MyMapper.java
package com.pzr.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class MyMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text,Text> {
@Override
public void map(LongWritable key, Text value,
OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
String str = value.toString();
if(str != null && str.length() > 2 && 0 != str.substring(0,2).trim().length()){
str = str.replaceAll(" +", " ");
String data[] = str.split(" ");
String date = data[0]; //日期
String time = data[1]; //时间
String lng = data[2]; //经度
String lat = data[3]; //纬度
String depth = data[4]; //深度(功力)
String magnitude = data[5]; //震级
String address = data[6];//参考地址
// output.collect(new Text(date.substring(0,7)), new Text(magnitude+"#"+address));//每一个月的最大
output.collect(new Text(date.substring(0,4)), new Text(magnitude+"#"+address));//每一个年的最大
// output.collect(new Text("allMax"), new Text(magnitude+"#"+address));//所有的最大
}
}
}reduce类:MyReducer.java
package com.pzr.mapreduce;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class MyReducer extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterator<Text> value,
OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
Double maxValue = Double.MIN_VALUE;
String addr = "";
while (value.hasNext()) {
Text tempValue = value.next();
String str = tempValue.toString();
String values[] = str.split("#");
//去掉字母
String tempStr = values[0].replaceAll("[a-zA-Z]", "");
Double temp = Math.max(maxValue, Double.parseDouble(tempStr.toString()));
if(!maxValue.equals(temp)){
addr = values[1];
maxValue = temp;
}
}
output.collect(key, new Text(String.valueOf(maxValue)+ " "+addr) );
}
}main方法类:MyTemperature.java
package com.pzr.mapreduce;
import java.io.IOException;
import java.util.Date;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
/**
* 查询最大震级
* @author pzr
*
*/
public class MyTemperature {
public static void main(String args[]) throws IOException{
JobConf conf = new JobConf(MyTemperature.class);
conf.setJobName("myJob");
Long fileName = (new Date()).getTime();
FileInputFormat.addInputPath(conf, new Path("hdfs://hadoop-master:9000/user/earthquake_info.txt"));
FileOutputFormat.setOutputPath(conf, new Path("hdfs://hadoop-master:9000/user/"+fileName));
conf.setMapperClass(MyMapper.class);
conf.setReducerClass(MyReducer.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
JobClient.runJob(conf);
}
}
运行Map/Reduce程序
MyMapper类中有3中分解方法,获取每月最大震级,获取每年最大震级和获取所有记录以来最大震级
每次只能执行一个,将其余的注释掉
MyTemperature是main函数运行类,执行时需要调整运行参数

添加环境变量,其中E:\hadoop-2.7.0是本地Hadoop目录
Hadoop_home:E:\hadoop-2.7.0
PATH:%PATH%;E:\hadoop-2.7.0\bin

结果
运行完成后会在指定目录下找到对应的生成文件

获取每月最大震级(部分结果)
1999-01 5.6 新疆托克逊
1999-02 7.2 新赫布里底群岛
1999-03 7.3 堪察加
1999-04 7.3 巴布亚新几内亚
1999-05 7.0 巴布亚新几内亚
1999-06 5.3 新疆拜城
1999-07 7.1 危地马拉与洪都拉斯间
1999-08 7.8 土耳其
1999-09 7.6 台湾花莲、南投间
1999-10 7.6 墨西哥获取每年最大震级(部分结果)
1999 7.8 土耳其
2000 7.8 苏门答腊南部
2001 8.1 新疆青海交界(新疆境内若羌)
2002 7.8 印尼苏门答腊北部海中
2003 8.0 日本北海道地区
2004 8.7 印度尼西亚苏门答腊岛西北近海
2005 8.5 苏门答腊北部
2006 8.0 堪察加半岛东北地区
2007 8.5 印尼苏门答腊南部海中
2008 8.0 四川汶川县
2009 8.0 萨摩亚群岛地区获取所有震级以来最大震级
allMax 9.0 日本本州东海岸附近海域出现问题
出现问题: 没有打印日志
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.解决办法:
在src目录下添加log4j.properties配置文件,内容如下
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n出现问题: java.lang.NullPointerException
Exception in thread "main" java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1010)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:483)
at org.apache.hadoop.util.Shell.run(Shell.java:456)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:722)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:815)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:798)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:728)
at org.apache.hadoop.fs.RawLocalFileSystem.mkOneDirWithMode(RawLocalFileSystem.java:486)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirsWithOptionalPermission(RawLocalFileSystem.java:526)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:504)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:305)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:133)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:147)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:562)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:557)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:557)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:548)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:833)
at com.pzr.mapreduce.MyTemperature.main(MyTemperature.java:35)
解决办法:
配置main方法的执行参数
添加环境变量,其中E:\hadoop-2.7.0是本地Hadoop目录
Hadoop_home:E:\hadoop-2.7.0
PATH:%PATH%;E:\hadoop-2.7.0\bin
出现问题: Exception in thread “main” java.lang.UnsatisfiedLinkError
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:609)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977)
at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:187)
at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:174)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:108)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:285)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:344)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:150)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:131)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:115)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:131)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:163)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:731)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:243)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:562)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:557)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:557)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:548)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:833)
at com.pzr.mapreduce.MyTemperature.main(MyTemperature.java:35)
解决办法:
修改hadoop源码
在src下创建相同路径,相同类,复制源码过来,修改对应内容
参考
http://blog.csdn.net/shennongzhaizhu/article/details/50493338
http://my.oschina.net/muou/blog/408543
















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











