









一、kafka / zookeeper环境配置
(mac下可以使用以下进行配置)
- 安装zookeeper :brew install zookeeper
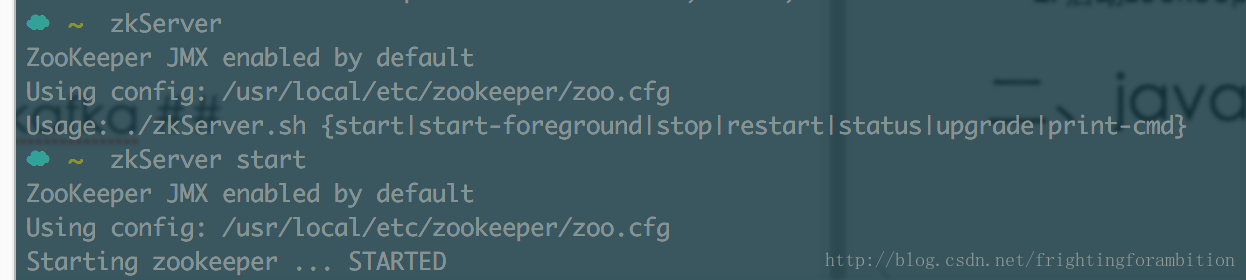
- 启动zookeeper:zkServer start
- 安装kafka:brew install kafka
- 启动kafka服务:kafka-server-start /usr/local/etc/kafka/server.properties
- 新建topic :kafka-topics –create –topic kafkatopic –replication-factor 1 –partitions 1 –zookeeper localhost:2181
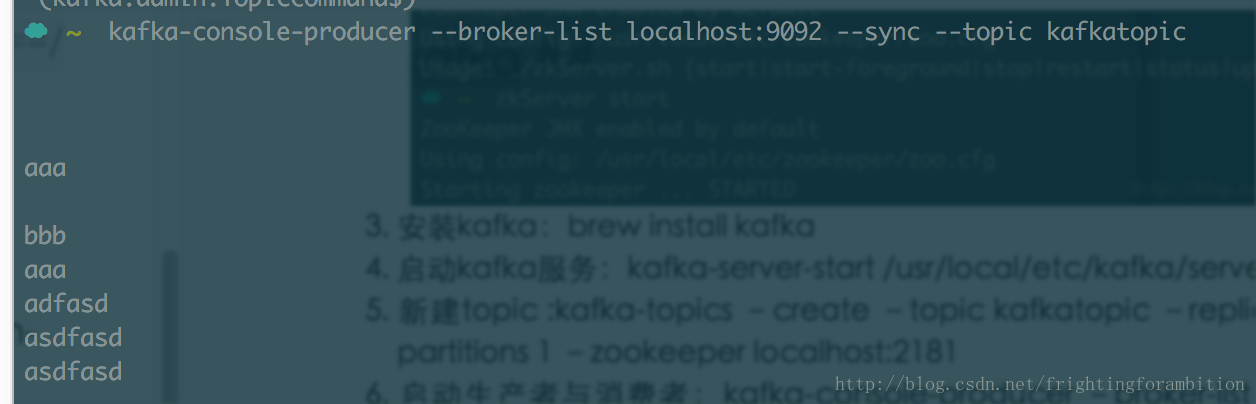
- 启动生产者与消费者:kafka-console-producer –broker-list localhost:9092 –sync –topic kafkatopic
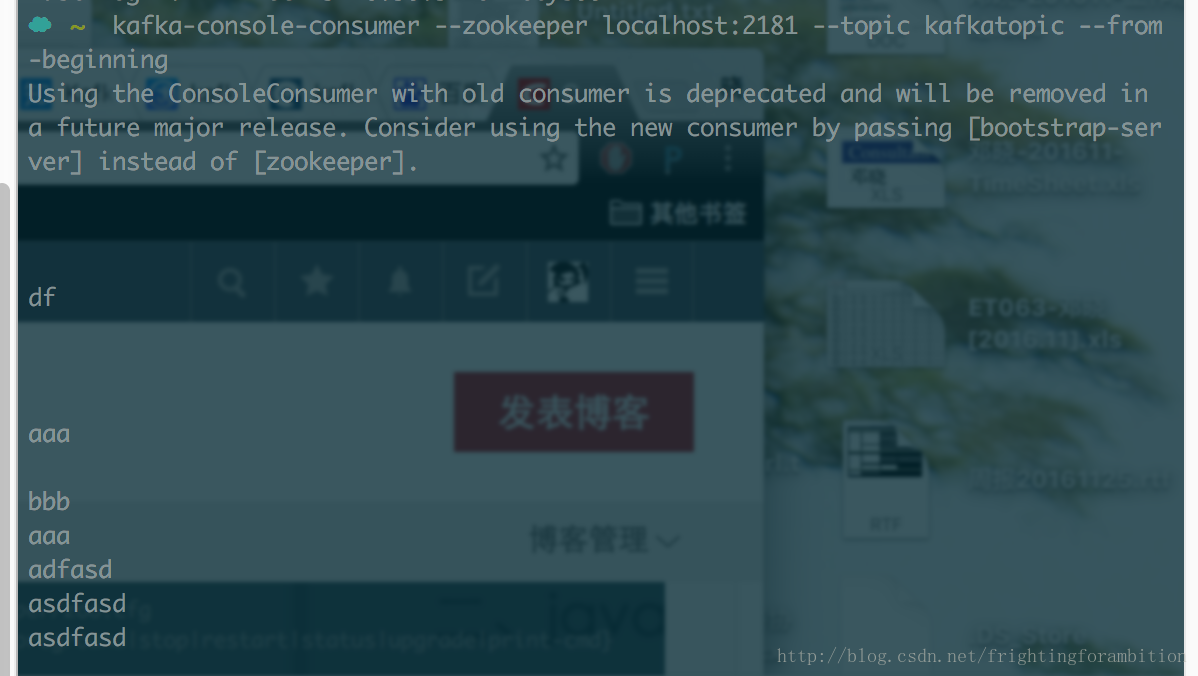
kafka-console-consumer –zookeeper localhost:2181 –topic kafkatopic –from-beginning
现在可以测试发送消息啦:
二、java中使用kafka
- maven依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.2.0</version>
</dependency>- 生产者:
package com.lenovo.m2.buy.purchase.webap.test;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
public class kafkaProducer extends Thread{
private String topic;
public kafkaProducer(String topic){
super();
this.topic = topic;
}
@Override
public void run() {
Producer producer = createProducer();
int i=0;
while(true){
producer.send(new KeyedMessage<Integer, String>(topic, "message: " + i++));
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private Producer createProducer() {
Properties properties = new Properties();
properties.put("zookeeper.connect", "localhost:2181,localhost:2181,localhost:2181");//声明zk
properties.put("serializer.class", StringEncoder.class.getName());
properties.put("metadata.broker.list", "localhost:9092");// 声明kafka broker,localhost:9093,localhost:9094
return new Producer<Integer, String>(new ProducerConfig(properties));
}
public static void main(String[] args) {
new kafkaProducer("test").start();// 使用kafka集群中创建好的主题 test
}
}
- 消费者:
package com.lenovo.m2.buy.purchase.webap.test;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
/**
1. Created by D_xiao on 16/12/9.
*/
public class kafkaConsumer extends Thread{
private String topic;
public kafkaConsumer(String topic){
super();
this.topic = topic;
}
@Override
public void run() {
ConsumerConnector consumer = createConsumer();
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, 1); // 一次从主题中获取一个数据
Map<String, List<KafkaStream<byte[], byte[]>>> messageStreams = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = messageStreams.get(topic).get(0);// 获取每次接收到的这个数据
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
while(iterator.hasNext()){
String message = new String(iterator.next().message());
System.out.println("接收到: " + message);
}
}
private ConsumerConnector createConsumer() {
Properties properties = new Properties();
properties.put("zookeeper.connect", "localhost:2181,localhost:2181,localhost:2181");//声明zk
properties.put("group.id", "group1");// 必须要使用别的组名称, 如果生产者和消费者都在同一组,则不能访问同一组内的topic数据
return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
public static void main(String[] args) {
new kafkaConsumer("test").start();// 使用kafka集群中创建好的主题 test
}
}先运行生产者,在运行消费者,消费端便可接收到消息啦~
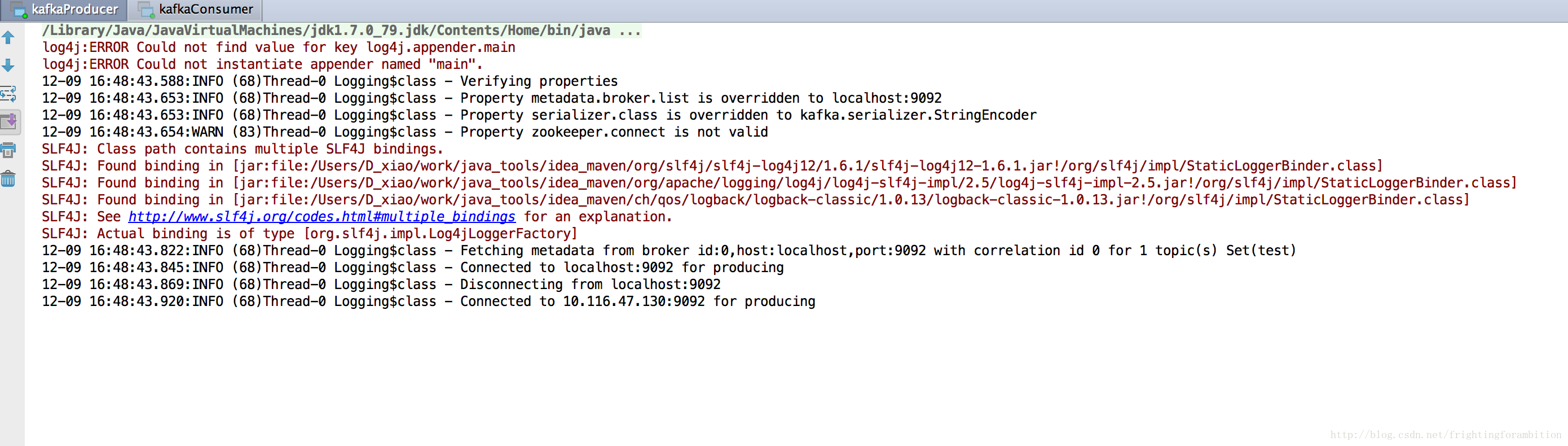
更新一下新版kafka 消费端代码, 新版纯java实现,新版jar包兼容旧版。
jar:
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.10.1.1</version>代码:
package com.fengjr.elk.web.write;
import java.util.*;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
/**
* Created by D_xiao on 2018/4/10.
*/
public class kafkaConsumerTest1 extends Thread{
private String topic;
public kafkaConsumerTest1(String topic){
super();
this.topic = topic;
}
@Override
public void run() {
Properties props = new Properties();
props.put("bootstrap.servers", "10.255.73.160:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("app-log-all"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecord<String, String> record : records){
System.out.println("partition:"+ record.partition()+ ",value:" + record.value());
}
}
}
public static void main(String[] args) {
new kafkaConsumerTest1("app-log-all").start();// 使用kafka集群中创建好的主题 test
}
}














 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









