









B-树 一种 自平衡的 多路 查找树。它在文件系统里很有用。
一个m阶的B-树,要么是空树,要么是满足这些特性的树。、
1.树 最多 有 m个分支。
2.树的根 最少 两个子树。
3. 树的非终端叶子节点 最少 m/2 向上 取整 个 子树。
4.所有叶子节点 都在 一层。
它的节点 结构: (N,P0,K1,P1,K2,p2......Kn,Pn)
其中 N 是 节点的 关键字个数,p0~pn 是 指向子树的指针,K1~Kn是关键字
#define M 3 //B树的阶数..
typedef int keyType;
typedef struct BTreeNode{
int keyNum;//关键字的个数.
BTreeNode * ptr[M+1];//指针数组,(总比 关键字 多一个).
keyType key[M+1];//关键字数组,第0个没用,从 第1个开始,
BTreeNode * parentNode;//节点的父亲..
}*BTree;根据上面的特性,总结:
1.节点中 分支树,最大为 阶数,最小 为 m/2 向上 取整(根节点最小为2,只有一个根节点 的树 可以没有子树)
2.所有结构中,关键字个数 = 指向子树的指针树 -1,所以关键字 最大 为 M-1,最少 为 上面 所说的 最小值 -1.
3.K1~Kn,顺序排放。
4.假设 k 是 节点的 第 x个 关键字,那么 P(x-1)指向的 子树中的 的 关键字 都比 k小,P(x)指向的子树指向的关键字 都比 k大。
B-树的 查找,分为 两部分,一部分 是顺指针查找节点 ,一部分 是 子 节点里 查找。下面的 search函数 就是 在 子节点里查找 关键字。
struct Result{//查找的结果
int tag;//0查找失败,1查找成功
int index;//位置
BTreeNode * p;//指向查找成功的指针或者插入位置的 指针
};
//查找到:返回k的位置; 没查找到:返回 k值的 搜索指针位置。
int search(BTree t,keyType k){
if (t != NULL){
for (int i = 1; i <= t->keyNum; i++){
if (t->key[i] == k){//找到了返回当前索引
return i;
}
else if(t->key[i] > k){//没找到,返回 前一个位置
return i-1;
}
}
return t->keyNum;//所有节点 都比 k 小
}
return 0;
}
//查找
Result searchBTree(BTree t,keyType k){
BTree p = t,q = NULL;
bool isFind = false;
int index = 0;
while (p != NULL){
index = search(p,k);
if (index >= 1 && p->key[index] == k ){
isFind = true;
break;
}
else{
q = p;
p = p->ptr[index];
}
}
if (isFind){//查找到了
Result r ={1,index,p};
return r;
}
else{
Result r ={0,index,q};
return r;
}
}下面 主要 说 B-树的 插入 算法。
1.如果节点 存在,不插入
2.节点不存在,插入 节点
3.如果 插入后, 节点 的 关键字个数 大于 M-1个,则 需要 分裂 ,具体分裂如下:

如果 造成 父节点 关键字个数 超过 M-1,则 需要 分裂。
完整代码如下:
// BTree.cpp : 定义控制台应用程序的入口点。
//B-树:多路自平衡查找树
#include "stdafx.h"
#include <cstdlib>
#include <cmath>
#include "queue.h"
#define M 3 //B树的阶数..
typedef int keyType;
typedef struct BTreeNode{
int keyNum;//关键字的个数.
BTreeNode * ptr[M+1];//指针数组,(总比 关键字 多一个).
keyType key[M+1];//关键字数组,第0个没用,从 第1个开始,
BTreeNode * parentNode;//节点的父亲..
}*BTree;
//获取一个节点,这样 的 初始化是个 好习惯.
BTreeNode * makeNode(){
BTreeNode * node = (BTreeNode*)malloc(sizeof(BTreeNode));
node->parentNode = NULL;
for (int i = 0; i <= M; i++){
node->ptr[i] = NULL;
}
node->keyNum = 0;
return node;
}
void initTree(BTree *tree){
*tree = NULL;
}
struct Result{//查找的结果
int tag;//0查找失败,1查找成功
int index;//位置
BTreeNode * p;//指向查找成功的指针或者插入位置的 指针
};
//查找到:返回k的位置; 没查找到:返回 k值的 搜索指针位置。
int search(BTree t,keyType k){
if (t != NULL){
for (int i = 1; i <= t->keyNum; i++){
if (t->key[i] == k){//找到了返回当前索引
return i;
}
else if(t->key[i] > k){//没找到,返回 前一个位置
return i-1;
}
}
return t->keyNum;//所有节点 都比 k 小
}
return 0;
}
//查找
Result searchBTree(BTree t,keyType k){
BTree p = t,q = NULL;
bool isFind = false;
int index = 0;
while (p != NULL){
index = search(p,k);
if (index >= 1 && p->key[index] == k ){
isFind = true;
break;
}
else{
q = p;
p = p->ptr[index];
}
}
if (isFind){//查找到了
Result r ={1,index,p};
return r;
}
else{
Result r ={0,index,q};
return r;
}
}
//将 p 插入 到 t->ptr[index+1]
//将 k 插入到 t->key[index+1];
void insert(BTree t,int index,keyType k,BTree p){
//index 后面的移开
for (int i = t->keyNum; i > index; i--){
t->key[i+1] = t->key[i];
t->ptr[i+1] = t->ptr[i];
}
t->key[index+1] = k;
t->ptr[index +1] = p;
t->keyNum ++;
}
//将 index 后部分分裂出 一个 新的节点
//指针 复制 :index 到 keyNum
//关键字复制: index +1 到 keyNum
void split(BTree t,int index,BTree * newNode){
*newNode = makeNode();
int count = 0;
for (int i = index; i <= t->keyNum; i++){
if (i > index){关键字复制: index +1 到 keyNum
count++;
(*newNode)->key[count] = t->key[i];//从1 开始.
}
BTree child = (*newNode)->ptr[count] = t->ptr[i];
//忘记写了,需要 把 带走的节点 设置 新的 父节点
if (child != NULL){
child->parentNode = *newNode;
}
t->ptr[i] = NULL;//设置原有指针为NULL
}
//下面两句漏写..
(*newNode)->parentNode = t->parentNode;
t->keyNum = index -1;//原节点 数量 减少.
(*newNode)->keyNum = count;
}
//新的根节点(之前为 空树,或者 分裂出了 一个 头节点)
void newRoot(BTree * t,keyType k,BTree left,BTree right){
BTree p = *t = makeNode();
p->key[1] = k;
p->ptr[0] = left;
p->ptr[1] = right;
p->keyNum = 1;
if (left != NULL){
left->parentNode = p;
}
if (right != NULL)
{
right->parentNode = p;
}
}
//插入
void insertBTree(BTree * t,keyType k){
Result r = searchBTree(*t,k);
if (r.tag == 0){//不存在 ,插入.
int index = r.index;//插入位置
BTree p = r.p;//插入节点
BTree q = NULL;//插入关键字的 右孩子.
BTree r = NULL;
bool finished = false;
while (p != NULL){
insert(p,index,k,q);
if (p->keyNum < M){//M阶 的 树,最多 有 M-1个 关键字{
finished = true;
break;
}
else{//关键字个数 超过M-1个,需要 分裂.
int mid = (int)ceil(M/2.0);
split(p,mid,&q);
k = p->key[mid];//分裂需要插入 到父节点的关键字
r = p;
p = p->parentNode;//父节点
index = search(p,k);//插入到父节点的位置.
}
}
if (finished == false){//空树,或者 根节点的 关键字 大于 M-1
newRoot(t,k,r,q);
}
}
}
//index之后的关键字 和指针左移
void leftMove(BTree p,int index){
if(index < p->keyNum){
for (int i = index; i < p->keyNum; i++){
if (i>= 1){
p->key[i] = p->key[i+1];
}
p->ptr[i] = p->ptr[i+1];
}
}
else{//在最后一个位置,不需要移动
p->ptr[p->keyNum] = NULL;
}
p->keyNum--;
}
//*t 树根,start:搜索开始的节点
bool deleteBTree(BTree * t,BTree start,keyType key){
Result r = searchBTree(start,key);
if (r.tag == 1){//找到了
BTree p = r.p;
int index = r.index;
//不是 最底下一层非终端节点,寻找右子树最小节点,替换k值,并删除最小节点
if (p->ptr[0] != NULL){
BTree q = p->ptr[index];
while (q->ptr[0] != NULL){
q = q->ptr[0];
}
p->key[index] = q->key[1];
return deleteBTree(t,p->ptr[index],q->key[1]);//删除最小节点退出函数
}
else// 是 最底下一层 非终端节点.
{
//节点最小阶数为 M/2 向上取整,关键字 比 最小阶数 小1
int min = (int)ceil(M/2.0)-1;
BTree parent = p->parentNode;
//是根节点 或者 节点数 大于 min
if (p->keyNum > min || parent == NULL ){
leftMove(p,index);//index后面的关键字左移
if (p->keyNum == 0){//根节点关键字最少为1,空树.
free(*t);
*t = NULL;
}
return true;
}
else if(p->keyNum == min){
leftMove(p,index);//将删除关键字后面的 左移
BTree leftBrother = NULL;
BTree rightBrother = NULL;
int pIndex = search(parent,key);//寻找节点在 父节点的 位置(查找位置
if (pIndex>=1){
leftBrother = parent->ptr[pIndex-1];//左相邻兄弟
}
if (pIndex < parent->keyNum){
rightBrother = parent->ptr[pIndex+1];//右兄弟
}
//寻找 是否 有相邻 兄弟 keyNum大于 min的.
if(leftBrother != NULL && leftBrother->keyNum > min){//左兄弟有空间
//整个空间 的关键字 右移一个位置
for (int i = p->keyNum; i >= 1; i--){
p->key[i+1] = p->key[i];
}
p->key[1] = parent->key[pIndex];//父节点关键字下移
p->keyNum++;
parent->key[pIndex] = leftBrother->key[leftBrother->keyNum];//将最大值上移到父节点。
leftBrother->keyNum--;//最终 左兄弟节点的 关键字少了一个,其余没变.
return true;
}
else if (rightBrother != NULL && rightBrother->keyNum > min){//右兄弟有空间
p->key[p->keyNum+1] = parent->key[pIndex+1];//父节点关键字下移
p->keyNum++;
parent->key[pIndex+1] = rightBrother->key[1];//将最小值上移
leftMove(rightBrother,1);//将 最小值 之后的 左移.
return true;
}
BTree merger = NULL;//合并后的节点
while (parent != NULL){
//左右相邻空间都等于 min,需要 删除节点后合并(书中第三种情况)
if (leftBrother != NULL){
merger = leftBrother;
//将节点中其他关键字 和 父节点的第pindex个 复制到左兄弟中
int lIndex = leftBrother->keyNum+1;//左兄弟下标
leftBrother->key[lIndex] = parent->key[pIndex];//先复制父节点关键字
leftMove(parent,pIndex);//父节点关键字后面的左移
for (int i = 0; i <= p->keyNum; i++){
if (i >=1){
leftBrother->key[lIndex] = p->key[i];
}
leftBrother->ptr[lIndex++] = p->ptr[i];
if (p->ptr[i] != NULL){//设置新的父节点
p->ptr[i]->parentNode = leftBrother;
}
}
leftBrother->keyNum += p->keyNum + 1;
free(p);//合并完成删除节点
}
else if (rightBrother != NULL){
merger = rightBrother;
//加入到右兄弟节点的关键字个数,减去一个关键字,再加上一个父节点关键字
int addNum = p->keyNum + 1;
rightBrother->keyNum += addNum;
//为插入关键字移位
for (int i = rightBrother->keyNum; i >= 0; i--){
if (i >= 1){
rightBrother->key[i+addNum] = rightBrother->key[i];
}
rightBrother->ptr[i+addNum] = rightBrother->ptr[i];
}
int i = 0;
for (; i <= p->keyNum; i++){
if (i >= 1){
rightBrother->key[i] = p->key[i];
}
rightBrother->ptr[i] = p->ptr[i];
if (p->ptr[i] != NULL){//设置新的父节点
p->ptr[i]->parentNode = rightBrother;
}
}
rightBrother->key[i] = parent->key[pIndex+1];
leftMove(parent,pIndex+1);//左移
free(p);//合并完成,删除节点
}
//父节点关键字不足,继续删除父节点,然后合并.
if (parent->keyNum < min){
p = parent;
parent = parent->parentNode;
pIndex = search(parent,key);//寻找节点在 父节点的 位置(查找位置
leftBrother = rightBrother = NULL;
if (pIndex>=1){
leftBrother = parent->ptr[pIndex-1];//左相邻兄弟
}
if (pIndex < parent->keyNum){
rightBrother = parent->ptr[pIndex+1];//右兄弟
}
}
else if (parent->keyNum > M-1){//合并后的关键字超过 M-1,需要分裂
BTree newNode = NULL,r = NULL;
bool finished = false;
p = parent;
keyType k = 0;
while (p != NULL){
int mid = (int)ceil(M/2.0);
split(p,mid,&newNode);
k = p->key[mid];//分裂需要插入 到父节点的关键字
r = p;
p = p->parentNode;
if (p != NULL){
index = search(p,k);//插入到父节点的位置.
insert(p,index,k,newNode);
if (p->keyNum < M){//M阶 的 树,最多 有 M-1个 关键字{
finished = true;
break;
}
}
}
if (finished == false){//空树,或者 根节点的 关键字 大于 M-1
newRoot(t,k,r,newNode);
}
return true;
}
}
//根节点最少一个,当为0时,将合并的节点设置为新的 根节点。
if (p->keyNum == 0){
free(p);
*t = merger;
return true;
}
}
else{//error
printf("------------ERROR--------------\n");
}
}
}
return false;//没找到
}
//层序遍历
void levelOrderTraverse(BTree tree){
if (tree != NULL){
LinkQueue queue;
queueInit(&queue);
enqueue(&queue,tree);
int count = 1;
int nextCount = 0;
int level = 1;
printf("-----------层序遍历--------------\n");
while (!queueEmpty(queue)){
printf("第%d层数据:",level);
for (int i = 0; i < count; i++){
BTree front;
dequeue(&queue,&front);
for (int j= 0; j <= front->keyNum; j++){
if (j >=1){
printf("%d\t",front->key[j]);
}
if (front->ptr[j] != NULL){
enqueue(&queue,front->ptr[j]);
}
nextCount++;
}
printf("------");
}
printf("\n");
count = nextCount;
nextCount = 0;
level ++;
}
queueDestory(&queue);
printf("\n");
}
}
int _tmain(int argc, _TCHAR* argv[])
{
BTree tree;
initTree(&tree);
int array [11] = {22,11,55,66,77,33,44,99,88,22,33};
for (int i = 0; i < 11; i++){
insertBTree(&tree,array[i]);
//printf("-----插入%d后------------\n",array[i]);
//levelOrderTraverse(tree);
}
levelOrderTraverse(tree);
return 0;
}
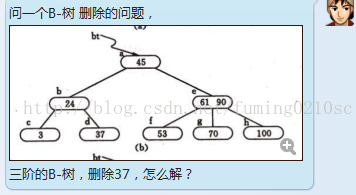
其中包含了部分不正确的 B-树 删除代码,在处理 下面 这个问题时,不正确。书中 也没提到 这种情况。希望 以后 完善。














 7716
7716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









