






Drupal的数据库层
译者:老葛
Drupal的正常工作依赖于数据库。在Drupal内部,在你的代码与数据库之间存在着一个轻量级的数据库抽象层。在本章,你将学习这一数据库抽象层是如何工作的,如何使用它,甚至如何写一个自己的驱动。你将看到查询语句如何被模块自动的修改以限制这些查询的范围。然后你将看到如何链接额外的数据库(比如一个合法的数据库)。最后,当一个模块独立的安装,升级,或者禁用时,你将测试如何创建,转移,甚至删除一个表。
定义数据库参数
在建立数据库连接时,通过查看你站点的settings.php文件,Drupal将知道需要连接哪一个数据库和使用相应的用户名和密码。这个文件一般位于sites/example.com/settings.php 或者sites/default/settings.php。定义数据库连接的代码行如下所示:
$db_url = 'mysql://username:password@localhost/databasename';
这个例子使用的是MySQL数据库。使用PostgreSQL的用户需要将前缀”mysql”替换为“pgsql”。显然,这里使用的用户名和密码对于你的数据库来说必须是合法的。他们是数据库的机密,而不是Drupal的,当你使用你的数据库工具建立数据库帐号是建立他们(用户名和密码)。
理解数据库抽象层
使用一个数据库抽象层API,直到有一天你试着不再使用它的时候,你才能发现他的全部优点。你是否曾经遇到过需要改变数据库系统的项目,你花费大量的时间仔细的审查每段代码来将它改为特定数据库的函数和查询?使用数据库抽象层以后,你将不再考虑各个不同数据库之间函数名称的细微差别,由于你使用的是符合ANSI SQL的语句,你不再需要写单独的查询语句了。举例来说,没有使用mysql_query()或者pg_query(),Drupal使用的是db_query(),这使得业务层和数据库层相互隔离。
Drupal的数据库层是轻量级的,它主要用于两个目的。第一个目的是使你的代码不与特定的数据库绑定。第二个目的是清洁用户提交的用于查询语句的数据以阻止SQL注入攻击。这一层是建立在使用Sql比重新学习一个新的抽象层语言更方便的原理之上的。通过检查你的文件settings.php内部的变量$db_url,Drupal决定要连接的数据库的类型。例如,如果$db_url开始部分为“mysql”,那么Drupal将包含进includes/database.mysql.inc. 如果$db_url开始部分为“pgsql”,那么Drupal将包含进includes/database. pgsql.inc.图5-1展示这一机制。
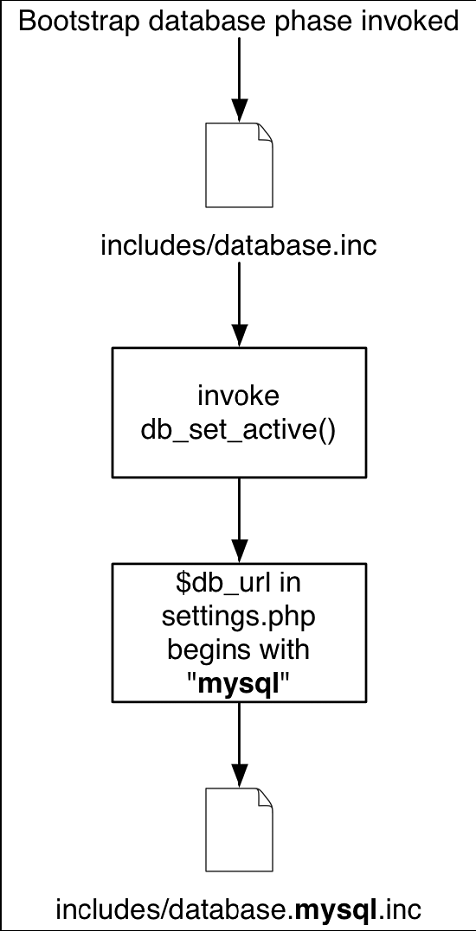
图5-1通过检查变量$db_url,Drupal决定需要引入哪一个数据库文件。
作为一个例子,让我们比较一下db_fetch_object()在MySQL和PostgreSQL抽象层的不同之处:
// From database.mysqli.inc.
function db_fetch_object($result) {
if ($result) {
return mysql_fetch_object($result);
}
}
// From database.pgsql.inc.
function db_fetch_object($result) {
if ($result) {
return pg_fetch_object($result);
}
}
如果你使用的数据库还未被支持,你可以通过为你的数据库实现相应的包裹函数来建立你自己的数据库抽象层。更多信息,参看本章最后部分的”建立你自己的数据库抽象层”。
建立数据库连接
作为Drupal的通常的引导指令(bootstrap)流程的一部分,它将自动的建立数据库链接,所以你不需要为此担心。
-----------------------------------------------------------------------------------注意:当你遇到需要写一个单独的PHP脚本或者有段处于Drupal之外的PHP代码的情况时,你需要访问Drupal的数据库,你可以使用include_once('includes/bootstrap.inc'),然后调用drupal_bootstrap(DRUPAL_BOOTSTRAP_DATABASE)来建立一个数据库连接。然后你就可以使用db_query()了,正如下节所讲。
执行简单的查询
Drupal的函数db_query()用来为已建立的数据库连接执行查询语句。这些查询语句包括SELECT, INSERT, UPDATE, 和 DELETE。让我们看一些例子。
从名为joke的表中取出所有字段的所有行,条件为字段vid的整数值与$node->nid的值相等:
db_query('SELECT * FROM {joke} WHERE vid = %d', $node->vid);
向名为joke的表中插入一行。这一行中将包含两个整数和一个字符串值(注意字符串值的占位符位于单引号中,这将帮助阻止SQL注入攻击):
db_query("INSERT INTO {joke} (nid, vid, punchline) VALUES (%d, %d, '%s')",
$node->nid, $node->vid, $node->punchline);
修改名为joke的表中的所有行,条件为字段vid的整数值与$node->nid的值相等。通过设置字段puchline等于$node->punchline包含的值来修改所有的这些行:
db_query("UPDATE {joke} SET punchline = '%s' WHERE vid = %d", $node->punchline,
$node->vid);
从名为joke的表中删除所有行,条件为字段vid的整数值与$node->nid的值相等:
db_query('DELETE FROM {joke} WHERE nid = %d', $node->nid);
当你写SQL语句的时候你需要知道,这里有一些Drupal特定的语法。首先,注意到表名位于花括号之间。这样做是为了表名可以前缀化这样可以保证它们名称的唯一性。这一习惯可以使用户在已存在的数据库中安装Drupal而避免表名的冲突,因为用户的主机托管提供者限制了他们可以建立的数据库的个数。
下一个不同寻常的地方是%d占位符。在Drupal中,查询语句通常使用占位符,真实值作为参数跟在后面。占位符%d将自动的被后面参数的值替换掉—在此为$node->vid.更多的占位符意味着更多的参数:
db_query('SELECT FROM {joke} WHERE nid > %d AND nid != %d', 5, 7);
在数据库中执行时,他将转化为如下形式:
SELECT FROM joke WHERE nid > 5 and nid != 7
用户提交的数据应该作为单独的参数传入,这样这些值可以被清洗从而阻止SQL注入攻击。Drupal使用printf语义(参看http://php.net/printf)来作为占位符在查询语句中的值。根据用户提交数据的类型,这里有不同的%修饰符。
表5-1列出了数据库查询占位符和他们的含义。
表5-1数据库查询占位符和他们的含义
Placeholder Meaning
------------------------------------------------------------------------------
%s String
%d Integer
%f Float
%b Binary data; do not enclose in ' '
%% Inserts a literal % sign (e.g., SELECT * FROM {users} WHERE name LIKE '%%%s%%')
db_query()的第一个参数总为查询语句本身。剩下的参数都是用于验证和插入到查询字符串中去的动态值。它可以是一个值的数组,或者每个值都作为一个独立的参数。后者更常用一些。
我们应该注意到使用这一语法我们将NULL,TRUE,和FALSE自动类型转换到了相应的数字等价形式(0或1)。大多数情况它是对的。
回显查询结果
有多种方式用于回显查询结果,这依赖于你的需求,你是需要一个单独的一行还是需要整个结果集,或者为了内部使用你打算得到结果的一部份,或者你想分页显示。
取回单个的值
如果你需要的仅是单个的一个值,那么你可以使用db_result()来回显该值。下面是一个例子,用来回显已发布博客日志的总数:
$sql = "SELECT COUNT(*) FROM {node} WHERE type = 'blog' AND status = 1";
$total = db_result(db_query($sql));
取回多行
大多数情况,你需要从数据库中返回的都多于一个字段。下面是一个典型的迭代方式用于遍历整个结果集:
$sql = "SELECT * FROM {node} WHERE type = 'blog' AND status = 1";
$result = db_query(db_rewrite_sql($sql));
while ($data = db_fetch_object($result)) {
$node = node_load($data->nid);
print node_view($node, TRUE);
}
上面的代码片段将输出所有的已发布的类型为blog的节点(表node中的字段status的值为0时,意味着未发布,为1时意味着已发布)。我们在接下来会讲解db_rewrite_sql()。函数db_fetch_object()从结果集中取出一行作为一个对象。将取出的结果作为一个数组可以使用db_fetch_array()。前者更为常用,这是因为大多数开发者觉得它更简洁一些。
取回限制范围的结果
你可能会觉得,在一个比如说有10,000个日志的站点上运行上面的代码将会是一个危险的想法。我们将限制这个语句的结果,10个最新发布的日志:
$sql = "SELECT * FROM {node} n WHERE type = 'blog' AND status = 1 ORDER BY
n.created DESC";
$result = db_query_range(db_rewrite_sql($sql), 0, 10);
我们没有将语句传递到db_query()和使用LIMIT条件语句,我们使用了函数db_query_range()。为什么?因为并非所有的数据库都支持LIMIT语句,所以我们需要使用db_query_range()作为包裹函数。
如果你还有一些没有硬编码的参数,你需要将这些用来填充占位符的变量放到范围的前面(所以type和status位于0,10之前,如下面的例子所示):
$type = 'blog';
$status = 1;
$sql = "SELECT * FROM {node} n WHERE type = '%s' AND status = %d ORDER BY
n.created DESC";
$result = db_query_range(db_rewrite_sql($sql), $type, $status, 0, 10);
将结果分页显示
我们可以使用一个更好的方式展示这些日志:分页显示。我们可以使用Drupal的分页器(pager)来这样做。让我们在此取回所有的日志,而这次我们将分页显示它们,使用指向更多结果页面的链接和位于最下面的“第一页和最后一页”的链接。
$sql = "SELECT * FROM {node} n WHERE type = 'blog' AND status = 1 ORDER BY
n.created DESC"
$result = pager_query(db_rewrite_sql($sql), 0, 10);
while ($data = db_fetch_object($result)) {
$node = node_load($data->nid);
print node_view($node, TRUE);
}
// Add links to remaining pages of results.
print theme('pager', NULL, 10);
虽然pager_query()不是数据库抽象层的真正的一部份,当你需要创建一个分页显示的结果时,你需要知道它。最后一行的调用theme('pager')将展示导航到其他页面的链接,你不需要向theme('pager')传递结果的总数,因为结果总数在调用pager_query()时已被记下。
使用临时表
如果你需要做很多的处理,在请求流程中你可能需要创建一个临时表。你可以通过调用函数db_query_temporary()来完成它,如下面的格式:
$result = db_query_temporary($sql, $arguments, $temporary_table_name);
接下来你可以使用临时表的名称来对临时表进行查询。例如,在Drupal的搜索模块(search module)中的函数do_search(),搜索是在多个阶段中完成的,它使用了临时表来保存中间信息。下面是常用方式,这里被简化了(学习search.module可了解全部实现,它可能是令人头痛的事):
// Select initial search results into temporary table named 'temp_search_sids'.
$result = db_query_temporary("
SELECT i.type, i.sid, SUM(i.score * t.count) AS relevance, COUNT(*) AS matches
FROM {search_index} i
INNER JOIN {search_total} t ON i.word = t.word $join1
WHERE $conditions
GROUP BY i.type, i.sid
HAVING COUNT(*) >= %d",
$arguments, 'temp_search_sids');
...
// Later: calculate maximum relevance, to normalize it, using temporary table.
$normalize = db_result(db_query('SELECT MAX(relevance) FROM temp_search_sids'));
...
// Still later: create a temporary search results table named 'temp_search_results'.
$result = db_query_temporary("
SELECT i.type, i.sid, $select2
FROM temp_search_sids i
INNER JOIN {search_dataset} d
ON i.sid = d.sid AND i.type = d.type $join2
WHERE $conditions $sort_parameters",
$arguments, 'temp_search_results');
...
// Finally: do actual search query.
$result = pager_query("SELECT * FROM temp_search_results", 10, 0, $count_query);
注意,临时表不需要使用花括号以对表进行前缀化,这是因为临时表的存在是暂时的,他不能出发表的前缀化流程。与之相对应的,永久的表的名称位于花括号内部以支持表的前缀化。















 1570
1570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









