







作者简介
运小辰 百度高级研发工程师

负责百度运维智能故障自愈方案相关设计研发工作,致力于降低单机房故障自愈风险、提高故障自愈效率,为业务可用性保驾护航。
干货概览
在故障自愈机器人,保你安心好睡眠一文中,我们介绍了单机房故障自愈的必要性和解决思路。本文主要介绍单机房故障自愈前需要进行的准备工作,具体包括:
单机房容灾能力建设中遇到的常见问题及解决方法
基于网络故障及业务故障场景的全面故障发现能力
百度统一前端(BFE)和百度名字服务(BNS)的流量调度能力
单机房容灾能力--常见问题
单机房故障场景下,流量调度是最简单且最有效的止损手段,但我们发现业务线经常会遇到如下问题导致无法通过流量调度进行止损:
1. 服务存在单点
描述:系统内只有一个实例或者多个实例全部部署在同一物理机房的程序模块即为单点。
问题:单点服务所在机房或单点服务自身发生故障时,无法通过流量调度、主备切换等手段进行快速止损。
要求:浏览请求的处理,不能存在单点;提交请求的处理,若无法消除单点(如有序提交场景下的ID分配),则需要有完整的备份方案(热备或者冷备)保障单机房故障时,可快速切换至其他机房。
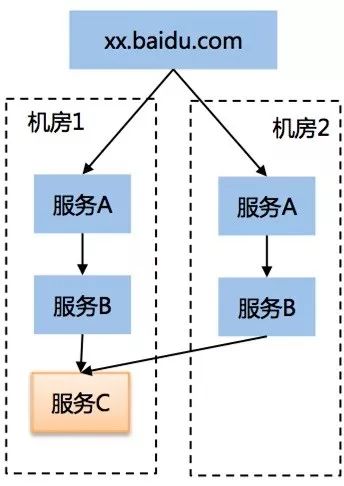
2. 服务跨机房混联
描述:上下游服务之间存在常态的跨机房混联。
问题:逻辑服务单元未隔离在独立的物理范围内,单机房故障会给产品线服务带来全局性影响。同时流量调度也无法使得服务恢复正常。
要求:将服务拆分为若干不同的逻辑单元,每个逻辑单元处于不同的物理机房,均能提供产品线完整服务。

3. 服务不满足N+1冗余
描述:任意单个机房故障时,其余机房剩余容量不足以承担该机房切出的流量。
问题:流量调度导致其余机房服务过载,造成多个机房服务故障,造成更大范围的影响。
要求:容量建设需要对于每个逻辑服务单元都要有明确的容量数据,并具备N+1冗余,即任意机房故障情况下,其余机房均可承载这部分流量,同时需要保证服务变化时及时更新数据和扩容服务,避免容量数据退化。同时对于流量的变化趋势,也需要有提前的预估,为重大事件流量高峰预留足够容量(如节日、运营、假期)。
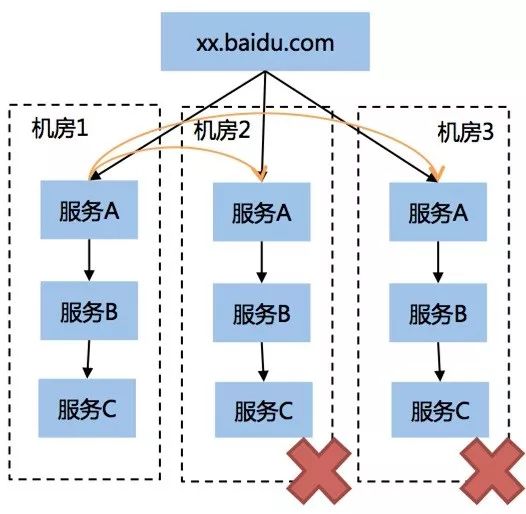
4. 服务关联强耦合
描述:上下游服务使用固定IP或固定机器名进行直接连接。
问题:单机房故障发生时,关联的上下游之间无法进行快速的流量调度止损。
要求:线上服务关联不允许使用固定IP或机器名链接,需使用具备流量调度能力的上下游连接方式以实现上下游依赖解耦,下游服务发生单机房故障,可以快速调整路由比例实现止损。
单机房容灾能力--盲测验收
完成以上四点单机房容灾能力建设后,业务线就具备了通过流量调度进行止损单机房故障的基本条件。那么如何验证业务线是否具备该能力、能力是否出现退化,我们采取盲测验收的方式,模拟或真实制造故障,验证不同业务线故障情况及止损效率,并给出相应的优化意见。
根据业务线进行容灾能力建设的不同阶段,我们从对产品实际可用性影响程度、成本、效果等方面权衡,将盲测分为三种类型:
无损盲测:仅从监控数据层面假造故障,同时被测业务可根据监控数据决策流量调度目标,对于业务服务实际无影响,主要验证故障处置流程是否符合预期、入口级流量切换预案是否完整。
提前通知有损盲测:真实植入实际故障,从网络、连接关系等基础设施层面植入真实错误,对业务服务有损,用于实战验证产品线各个组件的逻辑单元隔离性、故障应急处置能力。同时提前告知业务盲测时间和可能的影响,业务线运维人员可以提前准备相应的止损操作,减少单机房止损能力建设不完善导致的损失。
无通知有损盲测:在各业务线单机房容灾能力建设完成后,进行不提前通知的有损盲测,对业务来说与发生真实故障场景完全相同。真实验证业务线在单机房故障情况下的止损恢复能力。
单机房故障止损流程
一个完整的故障处理生命周期包括感知、止损、定位、分析四个阶段。

单机房故障止损覆盖从感知到止损阶段,其中感知阶段依赖监控系统的故障发现能力,止损阶段依赖流量调度系统的调度能力。我们来具体看下百度的监控系统与流量调度系统是如何在单机房故障止损场景中起作用。
故障发现:百度监控平台
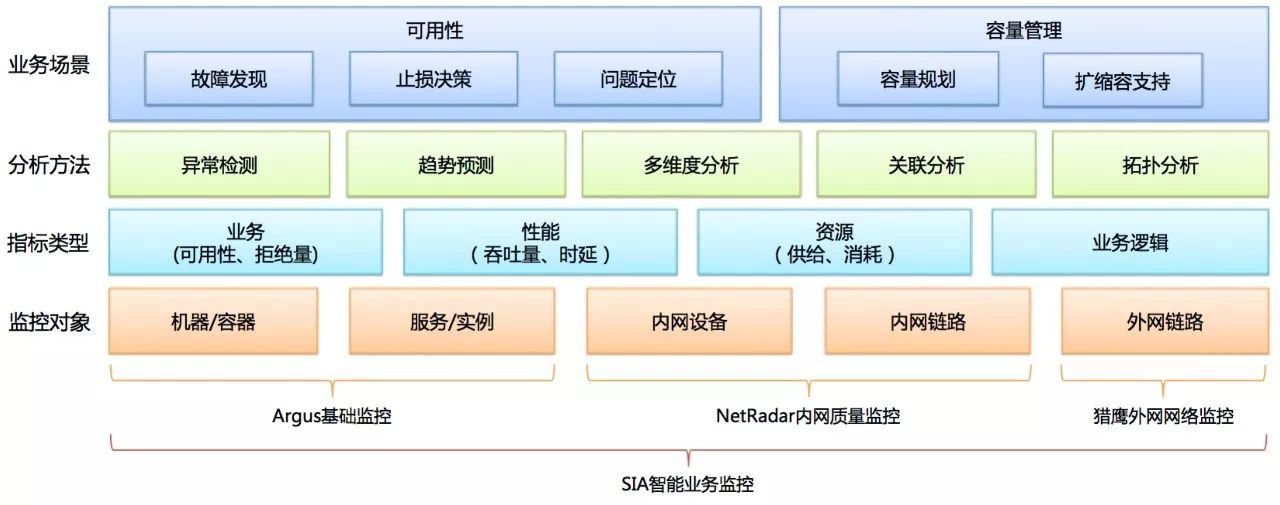
百度监控平台,针对单机房止损过程中的可用性场景,覆盖故障发现、止损决策、问题定位各阶段的监控。同时针对单机房止损依赖的容量管理场景,提供资源类监控采集,为容量规划、扩缩容提供数据支持。实现从运营商外网链路、百度内部网络设备/链路、服务/实例、机器/容器的全方位数据采集与监控。满足网络类单机房故障、业务类单机房故障的监控覆盖需求。
同时提供一系列数据分析方法。如智能异常检测、趋势预测、多维度分析、关联分析、服务和链路拓扑分析,实现故障的精准发现和定位。
故障止损:百度流量调度平台
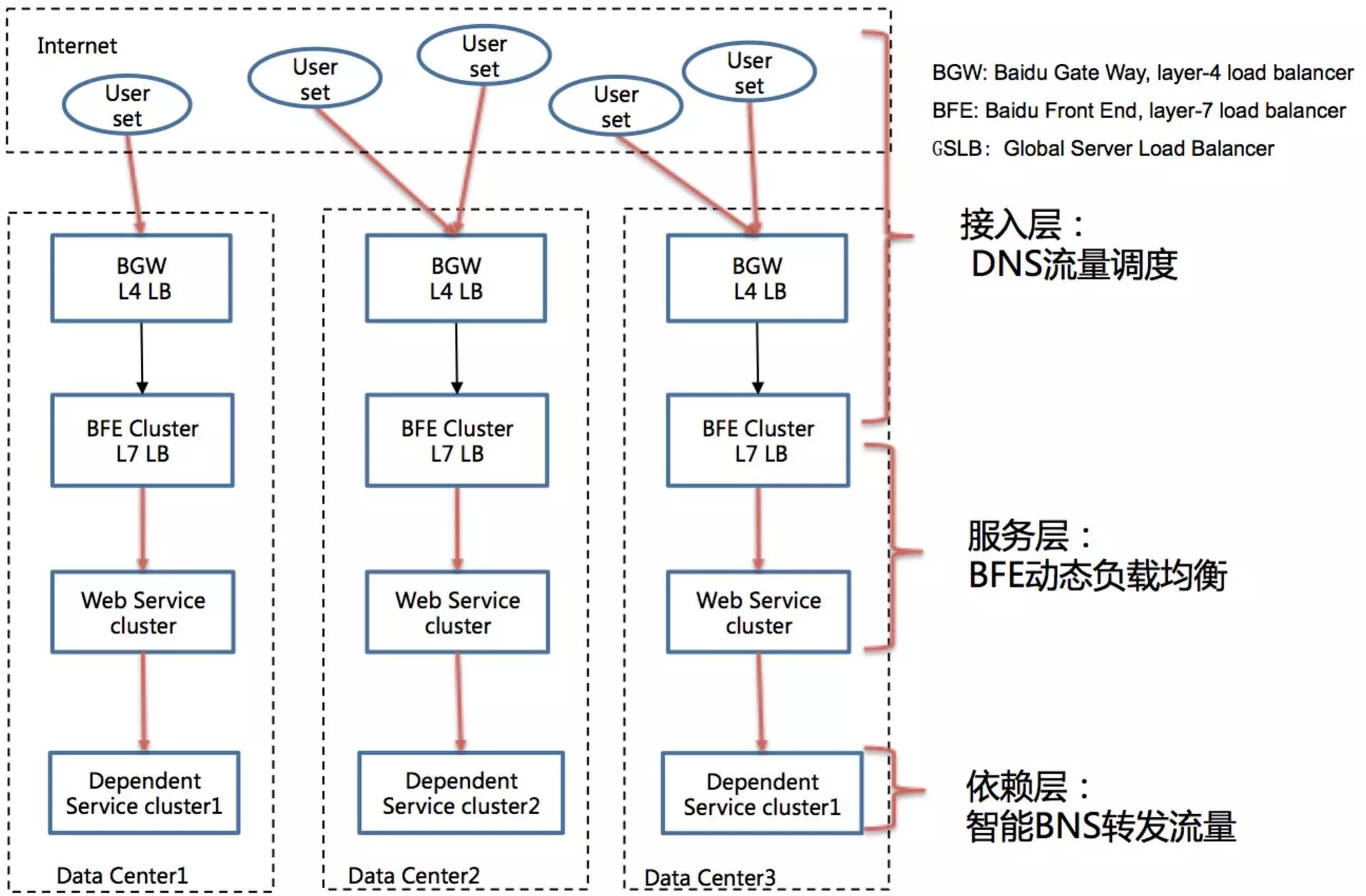
针对百度的网络架构和业务架构,我们将流量调度拆分为三层:接入层、服务层、依赖层。
接入层:从外网用户发起请求经过运营商网络到百度统一前端(BFE)的过程,使用DNS实现外网流量调度。
服务层:从BFE流量转发至内网服务的过程,使用BFE提供的GSLB动态负载均衡进行流量调度。
依赖层:内网上下游业务之间的流量调度过程,使用百度名字服务(BNS)进行流量调度。
对于单机房止损场景来说,DNS流量调度的生效时间较服务层、依赖层的流量调度生效时间要慢很多,所以我们期望在发生某个业务的局部单机房故障时,优先进行服务层、依赖层调度。提升止损时效性。
在单机房容灾能力、智能监控平台、流量调度平台的基础上,启动单机房故障自愈工作的时机已经成熟。我们将会在下篇文章中详细介绍单机房故障自愈解决方案,敬请期待!
单机房故障止损的能力标准
单机房故障自愈的常见问题
单机房故障自愈的解决方案

↓↓↓ 点击"阅读原文" 【查看更多信息】














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









