







图像平滑处理
原理
Note
以下原理来源于Richard Szeliski 的著作 Computer Vision: Algorithms and Applications 以及 Learning OpenCV
-
平滑 也称 模糊, 是一项简单且使用频率很高的图像处理方法。
-
平滑处理的用途有很多, 但是在本教程中我们仅仅关注它减少噪声的功用 (其他用途在以后的教程中会接触到)。
-
平滑处理时需要用到一个 滤波器 。 最常用的滤波器是 线性 滤波器,线性滤波处理的输出像素值 (i.e.
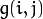 ) 是输入像素值 (i.e.
) 是输入像素值 (i.e. 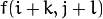 )的加权和 :
)的加权和 :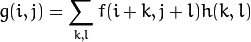
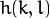 称为 核, 它仅仅是一个加权系数。
称为 核, 它仅仅是一个加权系数。不妨把 滤波器 想象成一个包含加权系数的窗口,当使用这个滤波器平滑处理图像时,就把这个窗口滑过图像。
-
滤波器的种类有很多, 这里仅仅提及最常用的:
归一化块滤波器 (Normalized Box Filter)
-
最简单的滤波器, 输出像素值是核窗口内像素值的 均值 ( 所有像素加权系数相等)
-
核如下:
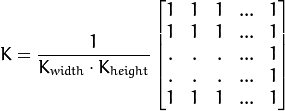
高斯滤波器 (Gaussian Filter)
-
最有用的滤波器 (尽管不是最快的)。 高斯滤波是将输入数组的每一个像素点与 高斯内核 卷积将卷积和当作输出像素值。
-
还记得1维高斯函数的样子吗?
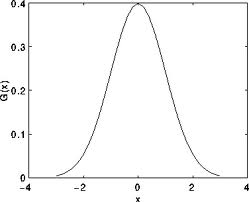
假设图像是1维的,那么观察上图,不难发现中间像素的加权系数是最大的, 周边像素的加权系数随着它们远离中间像素的距离增大而逐渐减小。
Note
2维高斯函数可以表达为 :
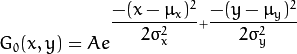
其中 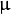 为均值 (峰值对应位置),
为均值 (峰值对应位置), 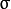 代表标准差 (变量
代表标准差 (变量 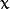 和 变量
和 变量 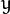 各有一个均值,也各有一个标准差)
各有一个均值,也各有一个标准差)
中值滤波器 (Median Filter)
中值滤波将图像的每个像素用邻域 (以当前像素为中心的正方形区域)像素的 中值 代替 。
双边滤波 (Bilateral Filter)
- 目前我们了解的滤波器都是为了 平滑 图像, 问题是有些时候这些滤波器不仅仅削弱了噪声, 连带着把边缘也给磨掉了。 为避免这样的情形 (至少在一定程度上 ), 我们可以使用双边滤波。
- 类似于高斯滤波器,双边滤波器也给每一个邻域像素分配一个加权系数。 这些加权系数包含两个部分, 第一部分加权方式与高斯滤波一样,第二部分的权重则取决于该邻域像素与当前像素的灰度差值。
- 详细的解释可以查看 链接
解释
-
下面看一看有关平滑的OpenCV函数,其余部分大家已经很熟了。
-
归一化块滤波器:
OpenCV函数 blur 执行了归一化块平滑操作。
我们输入4个实参 (详细的解释请参考 Reference):
- src: 输入图像
- dst: 输出图像
- Size( w,h ): 定义内核大小( w 像素宽度, h 像素高度)
- Point(-1, -1): 指定锚点位置(被平滑点), 如果是负值,取核的中心为锚点。
-
高斯滤波器:
OpenCV函数 GaussianBlur 执行高斯平滑 :
我们输入4个实参 (详细的解释请参考 Reference):
- src: 输入图像
- dst: 输出图像
- Size(w, h): 定义内核的大小(需要考虑的邻域范围)。
和
必须是正奇数,否则将使用
和
参数来计算内核大小。
则
-
中值滤波器:
OpenCV函数 medianBlur 执行中值滤波操作:
我们用了3个参数:
- src: 输入图像
- dst: 输出图像, 必须与 src 相同类型
- i: 内核大小 (只需一个值,因为我们使用正方形窗口),必须为奇数。
-
双边滤波器
OpenCV函数 bilateralFilter 执行双边滤波操作:
我们使用了5个参数:
- src: 输入图像
- dst: 输出图像
- d: 像素的邻域直径
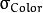 : 颜色空间的标准方差
: 颜色空间的标准方差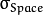 : 坐标空间的标准方差(像素单位)
: 坐标空间的标准方差(像素单位)
结果
-
程序显示了原始图像( lena.jpg) 和使用4种滤波器之后的效果图。
-
这里显示的是使用 中值滤波 之后的效果图:

腐蚀与膨胀(Eroding and Dilating)
原理
Note
以下内容来自于Bradski和Kaehler的大作: Learning OpenCV .
形态学操作
-
简单来讲,形态学操作就是基于形状的一系列图像处理操作。通过将 结构元素 作用于输入图像来产生输出图像。
-
最基本的形态学操作有二:腐蚀与膨胀(Erosion 与 Dilation)。 他们的运用广泛:
- 消除噪声
- 分割(isolate)独立的图像元素,以及连接(join)相邻的元素。
- 寻找图像中的明显的极大值区域或极小值区域。
-
通过以下图像,我们简要来讨论一下膨胀与腐蚀操作(译者注:注意这张图像中的字母为黑色,背景为白色,而不是一般意义的背景为黑色,前景为白色):
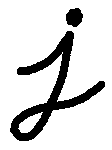
膨胀
-
此操作将图像
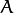 与任意形状的内核 (
与任意形状的内核 (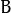 ),通常为正方形或圆形,进行卷积。
),通常为正方形或圆形,进行卷积。 -
内核
有一个可定义的 锚点, 通常定义为内核中心点。 -
进行膨胀操作时,将内核
划过图像,将内核 覆盖区域的最大相素值提取,并代替锚点位置的相素。显然,这一最大化操作将会导致图像中的亮区开始”扩展” (因此有了术语膨胀 dilation )。对上图采用膨胀操作我们得到: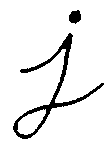
背景(白色)膨胀,而黑色字母缩小了。
腐蚀
-
腐蚀在形态学操作家族里是膨胀操作的孪生姐妹。它提取的是内核覆盖下的相素最小值。
-
进行腐蚀操作时,将内核
划过图像,将内核 覆盖区域的最小相素值提取,并代替锚点位置的相素。 -
以与膨胀相同的图像作为样本,我们使用腐蚀操作。从下面的结果图我们看到亮区(背景)变细,而黑色区域(字母)则变大了。

解释
-
大部分代码应该不需要解释了 (如果有任何疑问,请回头参考前面的教程)。 让我们来回顾一下本程序的总体流程:
- 装载图像 (可以是 RGB图像或者灰度图 )
- 创建两个显示窗口 (一个用于膨胀输出,一个用于腐蚀输出)
- 为每个操作创建两个 Trackbars:
- 第一个 trackbar “Element” 返回 erosion_elem 或者 dilation_elem
- 第二个 trackbar “Kernel size” 返回 erosion_size 或者 dilation_size 。
- 每次移动标尺, 用户函数 Erosion 或者 Dilation 就会被调用,函数将根据当前的trackbar位置更新输出图像。
让我们分析一下这两个函数:
-
Erosion:
-
进行 腐蚀 操作的函数是 erode 。 它接受了三个参数:
-
src: 原图像
-
erosion_dst: 输出图像
-
element: 腐蚀操作的内核。 如果不指定,默认为一个简单的
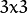 矩阵。否则,我们就要明确指定它的形状,可以使用函数 getStructuringElement:
矩阵。否则,我们就要明确指定它的形状,可以使用函数 getStructuringElement:
我们可以为我们的内核选择三种形状之一:
- 矩形: MORPH_RECT
- 交叉形: MORPH_CROSS
- 椭圆形: MORPH_ELLIPSE
然后,我们还需要指定内核大小,以及 锚点 位置。不指定锚点位置,则默认锚点在内核中心位置。
-
-
就这些了,我们现在可以对图像进行腐蚀操作了。
Note
OpenCV的 erode 函数还有另外的参数,其中一个参数允许你一下对图像进行多次腐蚀操作。在这个简单的文档中没有用到它,但是你可以参考OpenCV的使用手册。
-
-
Dilation:
下面是膨胀的代码,你可以看到,它和 Erosion 函数是多么相似。 这里我们同样可以指定内核的形状,锚点和大小。
结果
-
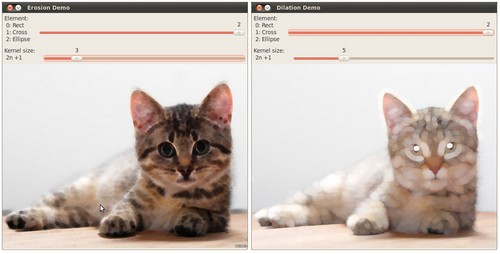
编译并使用图像路径作为参数运行程序,比如我们使用以下图像:

下面是操作的结果。 更改Trackbars的位置就会产生不一样的输出图像,自己试试吧。 最后,你还可以通过增加第三个Trackbar来控制膨胀或腐蚀的次数。
更多形态学变换
目标
本文档尝试解答如下问题:
- 如何使用OpenCV函数 morphologyEx 进行形态学操作:
- 开运算 (Opening)
- 闭运算 (Closing)
- 形态梯度 (Morphological Gradient)
- 顶帽 (Top Hat)
- 黑帽(Black Hat)
原理
Note
以下内容来自于Bradski和Kaehler的大作 Learning OpenCV 。
前一节我们讨论了两种最基本的形态学操作:
- 腐蚀 (Erosion)
- 膨胀 (Dilation)
运用这两个基本操作,我们可以实现更高级的形态学变换。这篇文档将会简要介绍OpenCV提供的5种高级形态学操作:
开运算 (Opening)
-
开运算是通过先对图像腐蚀再膨胀实现的。
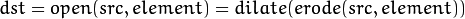
-
能够排除小团块物体(假设物体较背景明亮)
-
请看下面,左图是原图像,右图是采用开运算转换之后的结果图。 观察发现字母拐弯处的白色空间消失。
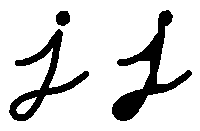
闭运算(Closing)
-
闭运算是通过先对图像膨胀再腐蚀实现的。
-
能够排除小型黑洞(黑色区域)。
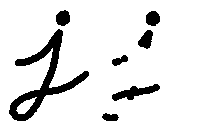
形态梯度(Morphological Gradient)
-
膨胀图与腐蚀图之差
-
能够保留物体的边缘轮廓,如下所示:

顶帽(Top Hat)
-
原图像与开运算结果图之差
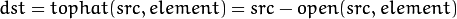
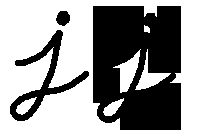
黑帽(Black Hat)
-
闭运算结果图与原图像之差
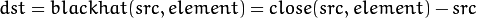

解释
-
看一下程序的总体流程:
-
装载图像
-
创建显示形态学操作的窗口
-
创建3个trackbar获取用户参数:
-
第一个trackbar “Operator” 返回用户选择的形态学操作类型 (morph_operator).
-
第二个trackbar “Element” 返回 morph_elem, 指定内核形状:
-
第三个trackbar “Kernel Size” 返回内核大小(morph_size)
-
-
每当任一标尺被移动, 用户函数 Morphology_Operations 就会被调用,该函数获取trackbar的当前值运行指定操作并更新显示结果图像。
运行形态学操作的核心函数是 morphologyEx 。在本例中,我们使用了4个参数(其余使用默认值):
- src : 原 (输入) 图像
- dst: 输出图像
- operation: 需要运行的形态学操作。 我们有5个选项:
- Opening: MORPH_OPEN : 2
- Closing: MORPH_CLOSE: 3
- Gradient: MORPH_GRADIENT: 4
- Top Hat: MORPH_TOPHAT: 5
- Black Hat: MORPH_BLACKHAT: 6
你可以看到, 它们的取值范围是 <2-6>, 因此我们要将从tracker获取的值增加(+2):
- element: 内核,可以使用函数:get_structuring_element:getStructuringElement <> 自定义。
-
结果
-
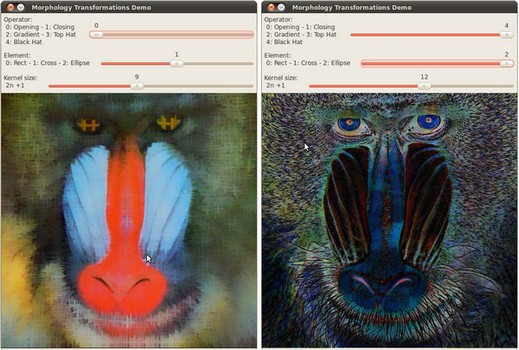
在编译上面的代码之后, 我们可以运行结果,将图片路径输入。这里使用图像: baboon.png:

-
这里是显示窗口的两个截图。第一幅图显示了使用交错内核和 开运算 之后的结果, 第二幅图显示了使用椭圆内核和 黑帽 之后的结果。
图像金字塔
原理
Note
以下内容来自于Bradski和Kaehler的大作: Learning OpenCV 。
- 当我们需要将图像转换到另一个尺寸的时候, 有两种可能:
- 放大 图像 或者
- 缩小 图像。
- 尽管OpenCV 几何变换 部分提供了一个真正意义上的图像缩放函数(resize, 在以后的教程中会学到),不过在本篇我们首先学习一下使用 图像金字塔 来做图像缩放, 图像金字塔是视觉运用中广泛采用的一项技术。
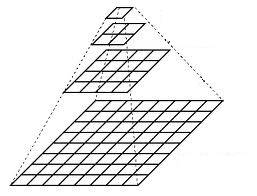
图像金字塔
- 一个图像金字塔是一系列图像的集合 - 所有图像来源于同一张原始图像 - 通过梯次向下采样获得,直到达到某个终止条件才停止采样。
- 有两种类型的图像金字塔常常出现在文献和应用中:
- 高斯金字塔(Gaussian pyramid): 用来向下采样
- 拉普拉斯金字塔(Laplacian pyramid): 用来从金字塔低层图像重建上层未采样图像
- 在这篇文档中我们将使用 高斯金字塔 。
高斯金字塔
-
想想金字塔为一层一层的图像,层级越高,图像越小。
-
每一层都按从下到上的次序编号, 层级
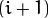 (表示为
(表示为 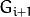 尺寸小于层级
尺寸小于层级  (
(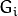 ))。
))。 -
为了获取层级为
的金字塔图像,我们采用如下方法:-
将
与高斯内核卷积: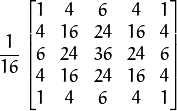
-
将所有偶数行和列去除。
-
-
显而易见,结果图像只有原图的四分之一。通过对输入图像
 (原始图像) 不停迭代以上步骤就会得到整个金字塔。
(原始图像) 不停迭代以上步骤就会得到整个金字塔。 -
以上过程描述了对图像的向下采样,如果将图像变大呢?:
- 首先,将图像在每个方向扩大为原来的两倍,新增的行和列以0填充()
- 使用先前同样的内核(乘以4)与放大后的图像卷积,获得 “新增像素” 的近似值。
- 首先,将图像在每个方向扩大为原来的两倍,新增的行和列以0填充(
-
这两个步骤(向下和向上采样) 分别通过OpenCV函数 pyrUp 和 pyrDown 实现, 我们将会在下面的示例中演示如何使用这两个函数。
Note
我们向下采样缩小图像的时候, 我们实际上 丢失 了一些信息。
解释
-
让我们来回顾一下本程序的总体流程:
-
装载图像(此处路径由程序设定,用户无需将图像路径当作参数输入)
-
创建两个Mat实例, 一个用来储存操作结果(dst), 另一个用来存储零时结果(tmp)。
-
创建窗口显示结果
-
执行无限循环,等待用户输入。
如果用户按 ESC 键程序退出。 此外,它还提供两个选项:
-
向上采样 (按 ‘u’)
函数 pyrUp 接受了3个参数:
- tmp: 当前图像, 初始化为原图像 src 。
- dst: 目的图像( 显示图像,为输入图像的两倍)
- Size( tmp.cols*2, tmp.rows*2 ) : 目的图像大小, 既然我们是向上采样, pyrUp 期待一个两倍于输入图像( tmp )的大小。
-
向下采样(按 ‘d’)
类似于 pyrUp, 函数 pyrDown 也接受了3个参数:
- tmp: 当前图像, 初始化为原图像 src 。
- dst: 目的图像( 显示图像,为输入图像的一半)
- Size( tmp.cols/2, tmp.rows/2 ) :目的图像大小, 既然我们是向下采样, pyrDown 期待一个一半于输入图像( tmp)的大小。
-
注意输入图像的大小(在两个方向)必须是2的冥,否则,将会显示错误。
-
最后,将输入图像 tmp 更新为当前显示图像, 这样后续操作将作用于更新后的图像。
-
-
结果
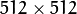 , 因此向下采样不会产生错误(
, 因此向下采样不会产生错误(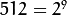 )。 原图像如下所示:
)。 原图像如下所示:


基本的阈值操作
基本理论:
-
注意:
- 本节的解释出自Bradski与Kaehler的书籍 Learning OpenCV 。
什么是阈值?
-
最简单的图像分割的方法。
-
应用举例:从一副图像中利用阈值分割出我们需要的物体部分(当然这里的物体可以是一部分或者整体)。这样的图像分割方法是基于图像中物体与背景之间的灰度差异,而且此分割属于像素级的分割。
-
为了从一副图像中提取出我们需要的部分,应该用图像中的每一个像素点的灰度值与选取的阈值进行比较,并作出相应的判断。(注意:阈值的选取依赖于具体的问题。即:物体在不同的图像中有可能会有不同的灰度值。
-
一旦找到了需要分割的物体的像素点,我们可以对这些像素点设定一些特定的值来表示。(例如:可以将该物体的像素点的灰度值设定为:‘0’(黑色),其他的像素点的灰度值为:‘255’(白色);当然像素点的灰度值可以任意,但最好设定的两种颜色对比度较强,方便观察结果)。

阈值化的类型:
-
OpenCV中提供了阈值(threshold)函数: threshold 。
-
这个函数有5种阈值化类型,在接下来的章节中将会具体介绍。
-
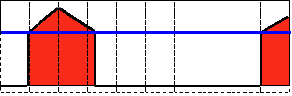
为了解释阈值分割的过程,我们来看一个简单有关像素灰度的图片,该图如下。该图中的蓝色水平线代表着具体的一个阈值。
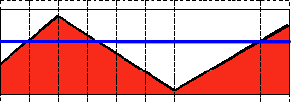
阈值类型1:二进制阈值化
-
该阈值化类型如下式所示:
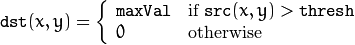
-
解释:在运用该阈值类型的时候,先要选定一个特定的阈值量,比如:125,这样,新的阈值产生规则可以解释为大于125的像素点的灰度值设定为最大值(如8位灰度值最大为255),灰度值小于125的像素点的灰度值设定为0。
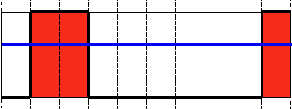
阈值类型2:反二进制阈值化
-
该阈值类型如下式所示:
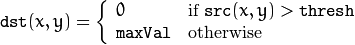
-
解释:该阈值化与二进制阈值化相似,先选定一个特定的灰度值作为阈值,不过最后的设定值相反。(在8位灰度图中,例如大于阈值的设定为0,而小于该阈值的设定为255)。
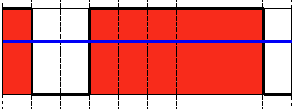
阈值类型3:截断阈值化
-
该阈值化类型如下式所示:
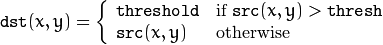
-
解释:同样首先需要选定一个阈值,图像中大于该阈值的像素点被设定为该阈值,小于该阈值的保持不变。(例如:阈值选取为125,那小于125的阈值不改变,大于125的灰度值(230)的像素点就设定为该阈值)。
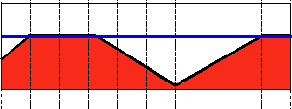
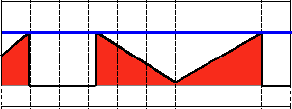
阈值类型4:阈值化为0
-
该阈值类型如下式所示:
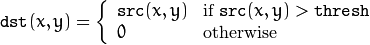
-
解释:先选定一个阈值,然后对图像做如下处理:1 像素点的灰度值大于该阈值的不进行任何改变;2 像素点的灰度值小于该阈值的,其灰度值全部变为0。
阈值类型5:反阈值化为0
-
该阈值类型如下式所示:
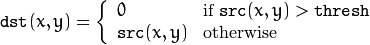
-
解释:原理类似于0阈值,但是在对图像做处理的时候相反,即:像素点的灰度值小于该阈值的不进行任何改变,而大于该阈值的部分,其灰度值全部变为0。
解释:
-
先看一下整个程序的结构:
-
先读取一副图片,如果是图片颜色类型是RGB3色类型,则转换成灰度类型的图像。转换颜色类型可以运用OpenCV中的 cvtColor<> 函数。
-
然后创建一个窗口来显示该图片可以检验转换结果
-
接着该程序创建两个滚动条来等待用户的输入:
- 第一个滚动条作用:选择阈值类型:二进制,反二进制,截断,0,反0。
- 第二个滚动条作用:选择阈值的大小。
-
在这里等到用户拖动滚动条来输入阈值类型以及阈值的大小,或者是用户键入ESC健退出程序。
-
无论何时拖动滚动条,用户自定义的阈值函数都将会被调用。
就像你看到的那样,在这样的过程中,函数 threshold<> 会接受到5个参数:
- src_gray: 输入的灰度图像的地址。
- dst: 输出图像的地址。
- threshold_value: 进行阈值操作时阈值的大小。
- max_BINARY_value: 设定的最大灰度值(该参数运用在二进制与反二进制阈值操作中)。
- threshold_type: 阈值的类型。从上面提到的5种中选择出的结果。
-
结果:
-
程序编译过后,从正确的路径中读取一张图片。例如,该输入图片如下所示:

-
首先,阈值类型选择为反二进制阈值类型。我们希望灰度值大于阈值的变暗,即这一部分像素的灰度值设定为0。从下图中可以很清楚的看到这样的变化。(在原图中,狗的嘴和眼睛部分比图像中的其他部分要亮,在结果图中可以看到由于反二进制阈值分割,这两部分变的比其他图像的都要暗。原理具体参见本节中反二进制阈值部分解释)

-
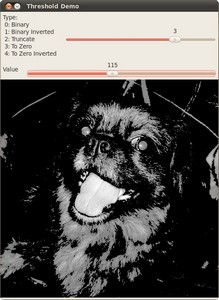
现在,阈值的类型选择为0阈值。在这种情况下,我们希望那些在图像中最黑的像素点彻底的变成黑色,而其他大于阈值的像素保持原来的面貌。其结果如下图所示:














 1642
1642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









