







介绍Hadoop的文章已经很多了,个人感觉这一篇还是写得不错的:
Hadoop以前是,现在仍然是大数据批处理领域的王者。Hadoop逐渐完善的生态体系,也让Hadoop广泛应用于各行业。
本文首先介绍Hadoop的架构和原理,侧重于Map-Reduce计算部分。再以简单示例带大家入门。
一、Hadoop 介绍
Hadoop 是什么
Hadoop是一个开发和运行大规模数据分析程序的软件平台,是隶属Apache的一个用java语言实现的开源软件框架,在大量普通服务器组成的集群中对海量数据进行分布式计算。
-
a java based software framework for easily writing applications
-
which process vast amounts of data (multi-petabyte data-sets)in-parallel on large clusters (thousands of nodes) of commodity hardware
-
in a reliable, fault-tolerant manner.
Hadoop 生态圈
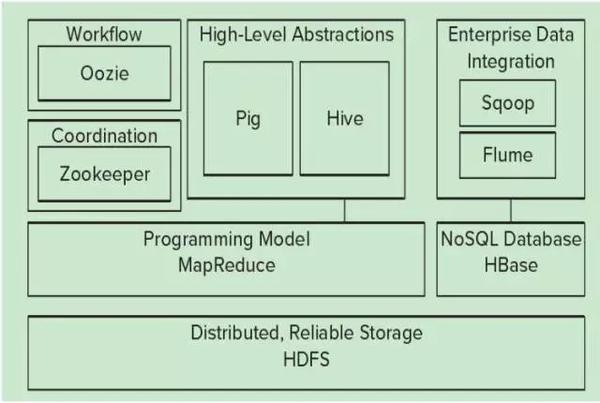
HDFS——Hadoop生态圈的基本组成部分是Hadoop分布式文件系统(HDFS)。HDFS是一种数据分布式保存机制,数据被保存在计算机集群上。HDFS为HBase等系统提供了基础。
MapReduce——Hadoop的主要执行框架是MapReduce,它是一个分布式、并行处理的编程模型。MapReduce把任务分为map(映射)阶段和reduce(化简)。开发人员基于存储在HDFS中数据,编写Hadoop的MapReduce任务。由于MapReduce工作原理的特性, Hadoop能以并行的方式访问数据,从而实现快速访问数据。
Hbase——HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
Zookeeper——用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
Oozie——Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的产出。
Pig——它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。其编译器将PigLatin翻译成MapReduce程序序列。
Hive——Hive类似于SQL高级语言,用于运行基于Hadoop的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。像Pig一样,Hive作为一个抽象层工具,吸引了很多熟悉SQL而不是Java编程的数据分析师。
Hadoop的生态圈还包括以下几个框架,用来与其它企业融合:
Sqoop是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用MapReduce实现并行化运行和容错技术。
Flume提供了分布式、可靠、高效的服务,用于收集、汇总大数据,并将单台计算机的大量数据转移到HDFS。它基于一个简单而灵活的架构,并提供了数据流的流。它利用简单的可扩展的数据模型,将企业中多台计算机上的数据转移到Hadoop。
Hadoop历史
• Apache社区的开源分布式系统
• 2003, 2004 Google发布GFS/ MapReduce论文
• 2006, Doug Cutting创立Apache Hadoop
• 2008, release 0.19.0
• 2009, release 0.20.0 -> 0.20.20x (生产系统稳定版本)
• 201111, release 0.23.0 alpha -> 20120523 2.0.0 alpha
• 201112, 0.20.20x -> release 1.0.0
• 商业公司支持:Cloudera & Hortonworks
Who use Hadoop

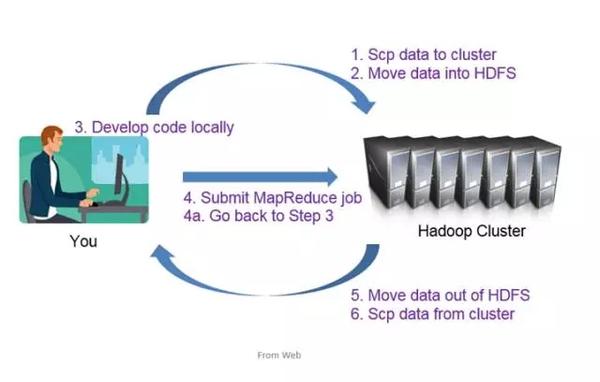
Hadoop程序的研发流程
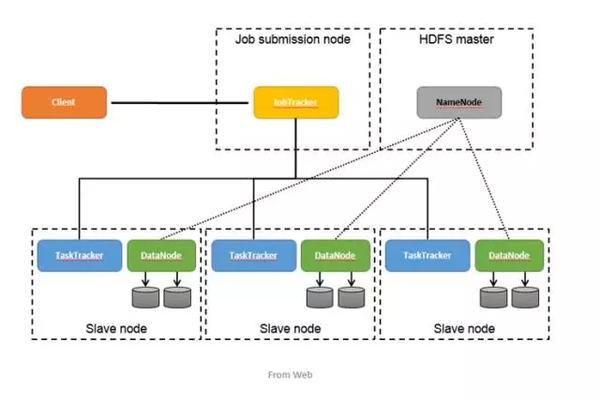
 Hadoop的构架
Hadoop的构架
第一代Hadoop架构如下:
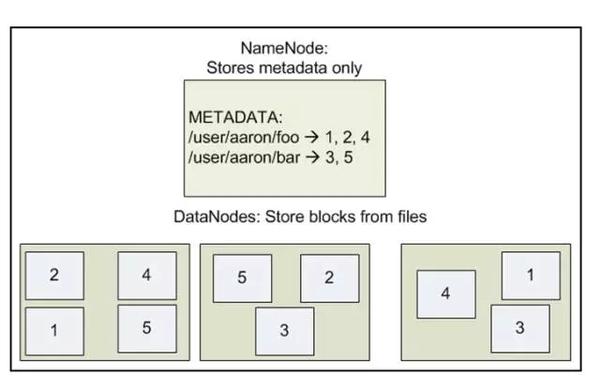
HDFS介绍
HDFS基本操作
hadoop fs –ls /user/
显示hdfs指定路径下的文件和文件夹
hadoop fs –putmy_file /data/
将本地文件上传到hdfs
hadoop fs –get/tmp /data/my_file
将hdfs上的文件下载到本地
hadoop fs –cat /tmp /data/my_file查看dfs中的文本文件内容
hadoop fs –text /tmp /data/my_sequence_file
查看dfs中的sequence文件内容
hadoop fs –rm /tmp/data/my_file
将hdfs上的文件删除
二、MapReduce 原理
MapReduce – 模型原理
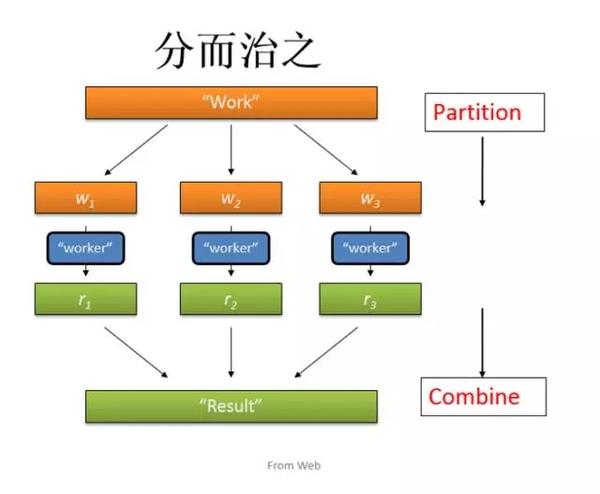
原理是分治思想,把一件事情先分解处理,然后再把处理后的结果合并。Map阶段就是分解处理,reduce阶段合并:
分治思想
-
分解、求解
-
合并
MapReduce映射
-
分:map
-
合:reduce
举个例子,有一堆的商品,共M种,需要数一下每种商品的个数。
传统的做法是,找一个人,数所有的商品,得出结果,如果觉得不够快,那就换一个数的更快的人(分布式计算出现以前的思路)。随着商品数量的增加,单个人数商品的做法,已不太可行。
基于MR计算模型,可以采用的方案是:找N个人,每人分一堆商品,每人都各自统计自己的商品,M种中每种有多少;然后再找M个人,每个人负责一种商品,把前面N个人的统计结果进行汇总。
总之,数据可以切割的计算,都可以用 Hadoop 实现。
MapReduce – 调度框架
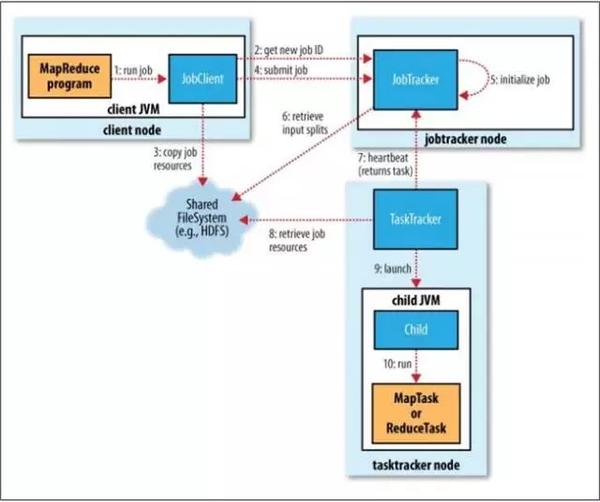
这张图展示了MapReduce的调度框架,主要有这几个角色:JobClient、JobTracker、TaskTracker,这里面的JT是一个单Master节点,TT是部署在每台计算节点上的一个Service。
其中JobClient负责根据用户指定的参数,生成一个MapReduce作业,然后把作业提交到JobTracker,JT负责把Job所有的Task调度到TT上。
MapReduce – 执行层
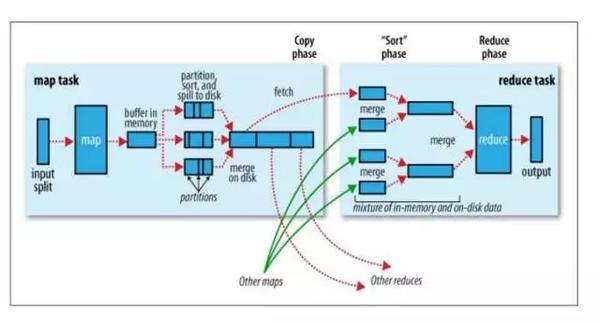
这个图展示了一个Mapreduce的执行过程,是一个具体的执行单元内(Task)发生的事情。左边是Map Task,map task的输入是一个数据分片,叫一个split。
输入数据由 MapReduce 框架解析成一条条记录,这是一个按照用户指定的规则(或者是默认规则)读取数据的过程。
读取出的数据,将他们一条条的传给map处理,就是大家写的mapper函数
经过mapper 处理后,又生成一条新记录,写在mapper所在机器的本地磁盘,分Partition写入,不同Partition数据会交由不同reduce处理;
右边是Reduce Task,Rt运行起来后先做的事情就是把属于自己的那一份份数据给拉到自己本地来,这个过程叫shuffle,shuffle的具体过程很复杂,其中包括各种异常处理,性能优化点也比较多。
数据shuffle到reduce本地之后,和map类似,一条条交给reduce函数处理,然后按照用户指定的格式写到HDFS指定目录。
MapReduce – 开发方式
1.基于java开发
--优势:原生接口,功能完备,性能较高
2.Streaming开发
--优势:不限语言,实现简单
三、Streaming 作业举例
Streaming 原理
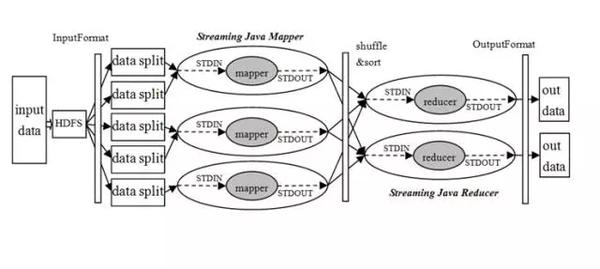
Hadoop Streaming通过标准输入将数据传递给用户实现的map/reduce程序,map/reduce程序使用标准输出将数据返回给Hadoop框架。
词频统计 – 示例
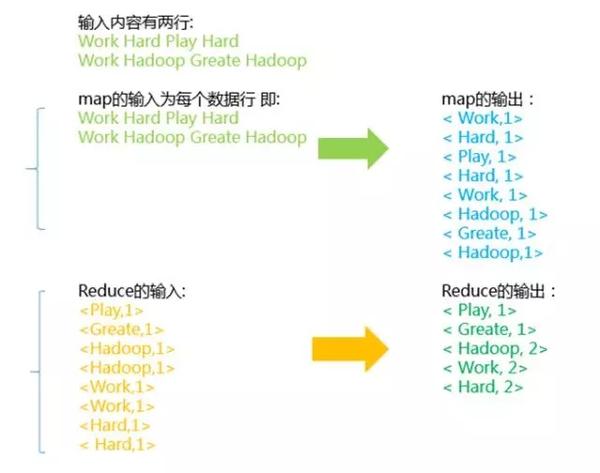
词频统计 – Shell实现
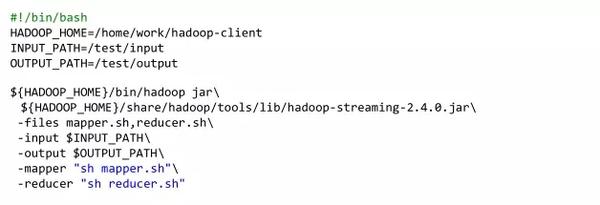

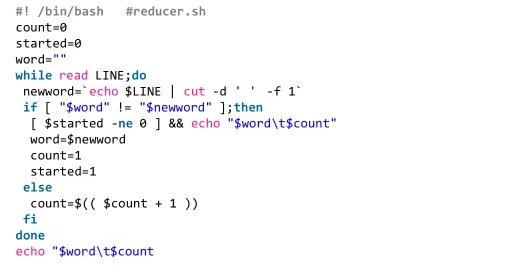
Streaming - 本地调试
Streaming最大的优点就是写起来方便,Streaming作业的本地调试的方法如下:
把输入数据用cat命令送到管道,管道另一头接mapper程序,输出重定向到文件,用sort命令把输出数据排序。然后再把以排过序的数据通过管道送给reducer程序,最后保存结果得到输出数据。
map
cat input | sh mapper.sh > map.out
sort
sort map.out > map.sort
reduce
cat map.sort | sh reducer.sh > reduce.out
四、第二代 Hadoop 架构
Hadoop1 存在的问题
Hadoop1存在的问题,主要有这么几方面:
1、可用性,JobTracker是单点,升级中断服务,正在运行的作业会失败;
2、扩展性,因为JobTracker单点性能瓶颈,单机群最大规模也就是几千台
3、按槽位分task,集群整体资源利用率不高,因为每台机器上运行多少个Task是固定的,但是每个Task消耗的资源,其实差异很大。
Hadoop2与Hadoop1的对比

Hadoop2 计算架构
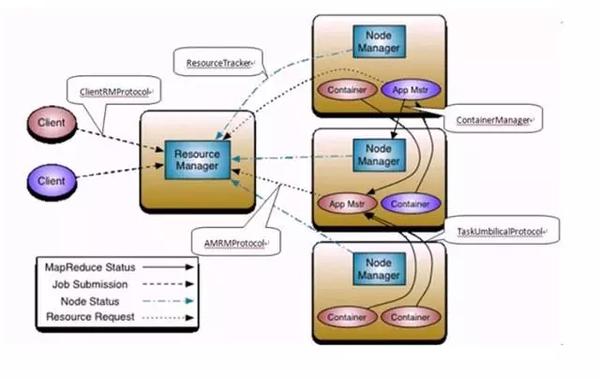
Hadoop1计算部分,主要有两个角色,JT和TT,其中JT是单点。
Hadoop2把单点的JT角色做了分布式化:
分布式化成包括RM 和AM两个角色,其中RM是单点,而AM是每个job一个,不同job之间是独立的AM。
这样,作业级别的调度在RM,Task级别的调度在AM,大大减轻了RM的压力:
RM:资源管理
AM:负责具体某一个作业的运行,申请Task资源,调度Task调度
AS:相当于之前的TT,但是每个机器上可以同时运行多个AS,每个AS同时只运行一个Task,理解为一个槽位。
Hadoo2的主要优势有:
1、支持热升级
-
中断时间很短,对用户基本透明
2、支持更大规模的集群
-
集群规模可超过万台
3、更高的集群资源利用率
-
淡化槽位概念,更细粒度资源<cpu, memory>
链接:https://zhuanlan.zhihu.com/p/20953323
来源:知乎














 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









