









1 摘要
可视分析使得人们能够分析大量的信息,为了支持复杂的决策和数据探索。人类作为一个中心的角色在知识产生的过程,从片段的证明到可视数据分析。虽然前者的研究提供了框架来产生这些过程,他们的范围通常聚焦很窄,所以他们不包含不同等级的不同视角。本文提供一个知识产生的可视分析模型,将这些分离的框架结合到一起,但是,仍然保留以前先进的模型(例如.KDD过程)来描述整个可视分析流程的个体片段。为了测试这个模型的有效性,用一个现实世界的可视分析系统来比较这个模型,证明当开发和评估这个系统,这个支持产生流程模型提供了一个有用向导。这个模型是用来有效对比不同数据分析系统。此外,这个模型可以提供一个公共语言与描述的可视分析流程,研究者们可以用此来进行交流。最后,这个模型反射出未来可以着手研究的领域。
2 内容
在VAST’2014的一篇论文中[1],来自德国康斯坦茨大学数据分析和可视化组(Data Analysis and Visualization Group, University of Konstanz)的Sacha等人,提出了一种基于可视化分析的知识产生模型。这个模型保留了过去的挖掘模型,如KDD模型,也从各角度、各层次更加全面地阐述了人类利用计算机的可视化分析系统产生知识的过程。Sacha等人提出了一个可视分析模型,详细的分析了从数据到知识的产生过程,以及每个过程中所涉及到的理论与方法。
如图1所示,知识产生模型包括计算机和人两部分,左边的计算机部分表示一个数据的可视化分析系统,右边则是人类验证假设的知识产生过程,云状图案表示数据分析时要求人机间密切交互。在计算机部分中,数据被绘制为可视化图表,同时也通过模型进行整理和挖掘。可视化图表既可以显示原始数据的特性,也可以显示模型的结果。用户也可以基于可视化图表来对模型进行调整,指导建模过程。
2.1 计算机部分
数据(Data)
是一切分析的开始,用来结构化、半结构化、非结构化地描述现象,在一次分析中附加的数据可以通过一定方法自动或人工生成,称作metadata,就是“关于数据的数据”。
模型(Model)
模型可以简单理解为一个子集数据的属性或者复杂数据挖掘算法的统计描述。KDD过程,包括的范围从对数据做最简单的统计分析,到复杂的数据挖掘算法,是从数据集中识别有效、可理解的模式的过程。模型服务不同的可视分析目的。可以通过计算单一的数据来解决简单的分析任务。
可视化(Visualization)
而另一个从数据到知识的路径就是可视化技术,可视化使分析员直观地观察到数据间的关系。在可视分析里,可视化是基于自动的模型,例如,聚类模型用来可视分组数据。同样,一个模型也可以被可视化,例如,一个盒形图展示数据在一维上的分布。一个模型的可视方法依赖于可视的状态,例如,在语义缩放(semantic zooming),一个可视化可能用不同的模型属性在缩放等级。Visualization通常用作分析与可视分析系统之间的基础接口,由于理解模型通常需要更多感知的付出。
2 .2 在人的部分
探索循环(Exploration Loop)
探索循环描述分析师同一个可视化分析系统进行一系列互动行为(Action),如数据准备、建立模型、操控可视化结果等,观察和探索由此产生的反馈,并获得发现(Finding)。分析师的行为应当遵循分析的目标而展开。
验证循环(Verification Loop)
验证循环是在探索循环基础上证实或者提出新的假设。分析师在观察阶段得到发现的结果后,深入分析获得现象背后的猜测(Insight),会产生新的假设(Hypothesis)并成为进一步调查的动机。猜测并非知识,而是由弱证据得到的感知等待进一步假设验证。
知识产生循环(Knowledge Generation Loop)
分析师不断形成和验证假设,当证据足够可信时这一系列的洞察和猜测便衍生出了知识(Knowledge)。知识同样会影响所提出的新假设。
在探索循环中,人们通过模型输出和可视化图表寻找数据中可能存在的模式,基于此采取一系列行动,例如改变参数,去产生得到新的模型输出和新的可视化图表。这样做的动机在验证循环之中:人们通过模式洞察到数据的特点,产生可能的猜测。这些猜测的验证正是基于探索循环中的行动。最后,在验证循环之上有知识循环,不断的收集验证循环中已被验证的猜测,总结为知识。

图 1.可视分析中的知识产生模型
本模型的提出是建立在已有的各种模型的基础之上的,如图2所示。例如,之前的信息可视化流程图描述了如何从数据产生可视化图表,数据挖掘流程图则描述了如何对数据进行预处理和建模并最终得到分析结果。之前的交互步骤模型描述了人在分析过程中的评价、目标产生和执行步骤,意义构建模型则描述了人在整个分析过程中对问题理解的加深。它们在本模型中被分解为三层循环。此外,众多的交互词汇系统的描述了探索循环中的行为。

图 2.本模型和已有模型之间的关系
作者利用本模型对一些实际的可视分析系统进行了评价和比较,如图3所示。Jigsaw是一款免费的文本可视分析系统[2],它可以读入文本数据,自动提取实体,建立主题模型,因此强于建模。此外,它提供了一系列可视化图表来显示文本的各种特征,因此也强于可视化。它的许多可视化,例如文件聚类视图,是基于主题模型的,因此可以算是对模型的可视化。用户可以在多种视图之间切换,改变各种视觉特性,因此它很好的支持了探索循环。此外,它还提供了tablet视图,允许用户记录自己的发现,并整理归类,提供了一定的验证循环支持。然而,Jigsaw不支持对原始数据预处理,也不太支持模型参数选择。
3一个模型应用的例子——Jigsaw文档可视化分析系统
Jigsaw是一款利用文本挖掘算法建立各种文档可视化视图的软件,可生成文档的聚类图、时间轴、词树图等。建模是系统根据任务自动完成的,并产生相对模型的可视化图表,用户可自由调节图表的属性和外观,是一个典型的可视化分析系统。

图3 Jigsaw中的可视化结果。(a)中表示将人名和文本关联,(b)中表示文本聚类图,(c)Tablet界面
Jigsaw十分支持模型中提出的所有行为。在人类的探索循环中,Jigsaw提供各种专业的可视化结果,而用户可以利用这些工具探索某一数据集,如用户根据他们的需要改变聚类的簇数。验证循环同探索循环紧密连接,引导用户由发现产生猜测,而这些发现又可用来验证实际的假设。Jigsaw中提供tablet界面,允许用户整理和归纳发现,有助于结构化地衍生出猜测。知识产生循环取决于用户,因为涉及到相信和推理的概念,而知识又是建立在验证基础上的,Jigsaw形象化的分析过程也有助于知识的产生。
这个模型将人类和计算机作为一个循环,在产生知识的过程中二者不可或缺。利用模型可以评估分析系统的功能和效果,改进系统;在模型中探索循环是知识产生的基础,对知识生态系统改进的重心应放在人机交互,如自动发现意外的结果特征和复杂模型的可操作性;而在知识圈中间位置的验证循环,要求可视化的分析系统设计有效组织和总结结果的功能;对于最末端的知识循环,人类设计和依赖系统提供不同的视角
Weka是一款免费的数据挖掘系统 [3],它允许用户对数据进行一系列的预处理,例如数据删除、离散化、文本分词等等,同时支持大量的数据挖掘算法,涵盖了各种分类、聚类、关联规则挖掘模型。但是该系统支持的可视化相当有限,例如显示散点图矩阵,或者显示决策树结果、显示神经网络结构。另外,用户探索仅限于更换预处理方法和更换模型,功能较为简单。用户无法整理自己的发现,因此该系统对验证循环的支持并不好。
Tableau是一款商业化的可视化系统 [4],它允许用户通过漂亮的UI来预处理数据,通过简单的拖拽来设计各种可视化图表。但是一直以来,它支持的模型很有限,直到今年,Tableau支持了R语言,它才真正用于建模功能。Tableua支持灵活的数据探索。它还支持spreadsheet和storyboard等强大的功能,可以生成MLV视图和类似powerpoint的演示界面。这些都是对验证循环的支持。
nSpace是一款商业化的文本分析系统 [5],虽然它对数据预处理和数学模型的支持很弱,但是它提供了多种可视化图表显示数据的不同特征。这些图表可以较好的支持数据探索循环。最为与众不同的是,nSpace提供了sandbox界面用于组织用户的发现,并生成结果报告。该功能比Jigsaw的tablet和Tableau的storyboard更为强大,能较好的支持验证循环。
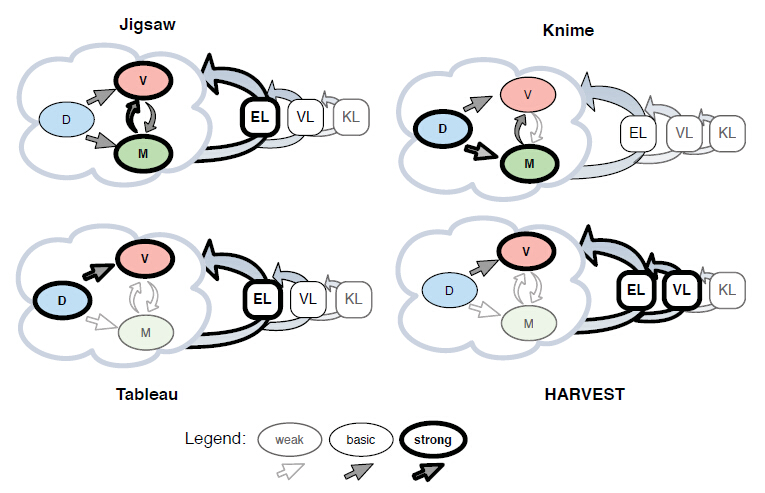
图 4.利用本模型对不同的可视分析系统进行评价和比较
作者也谈到,本模型具有一些局限性,比如未考虑多个分析人员之间的协作与交流,未考虑不同可视分析系统之间的切换,未考虑分析人员和领域专家、政府官员之间的沟通,未考虑动态变化的流数据。这些问题可以进一步研究。
基于此模型,作者展望了未来可视分析的研究方向。例如,在探索循环中,研究者可以更多的考虑通过可视化与数学模型进行交互的技术,也可以考虑如何引导用户快速系统的发现数据中的模式,或者如何自动检测模式。在验证循环中,研究者可以如何保存之间的探索结果,以方便回溯,验证其可靠性。研究者可以考虑如何组织不同的探索结果,辅助用户产生假设,甚至自动产生假设。在知识发现循环中,研究者可以做的比较少。毕竟,知识发现只在人脑中。但研究者可以提供更多更方便的可视化视图和数学模型,方便用户从多个角度考虑同一个数据、同一个问题。这样,也许用户更容易最终得到有用的知识。
[1] Dominik Sacha, Andreas Stoffel, Florian Stoffel, Bum Chul Kwon, Geoffrey Ellis, and Daniel Keim, Knowledge Generation Model for Visual Analytics, IEEE Trans. Vis. Comput. Graph. (VAST’14), 2014, to appear.
[2] C. Görg, Z. Liu, J. Kihm, J. Choo, H. Park, and J. T. Stasko. Combining Computational Analyses and Interactive Visualization for Document Exploration and Sensemaking in Jigsaw, IEEE Trans. Vis. Comput. Graph., 19(10):1646–1663, 2013.
[3] Weka 3: Data Mining Software in Java, http://www.cs.waikato.ac.nz/ml/weka/
[4] Tableau: Visual Analytics for Everyone, http://www.tableausoftware.com/
[5] nSpace: Web 2.0 Analysis, http://www.oculusinfo.com/nspace/














 6403
6403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









