







Java中的IO流
Java的核心库java.io提供了全面的IO接口。包括:文件读写、标准设备输出等。Java中IO是以流为基础进行输入输出的,所有数据被串行化写入输出流,或者从输入流读入。
百度百科:
在线API:
Java IO流的分类
1) 字节流:数据流中的最小的数据单元是字节,一次读入读出8位二进制;
2) 字符流:数据流中的最小的数据单元是字符,一次读入读出16位二进制,java中的字符是Unicode编码,一个字符占用两个字节。
字节流
输入字节流:InputStream类
- InputStream类是个抽象类是所有字节输入流的超类。

读取文件:FileInputStream
- 在src目录下创建一个a.txt文件
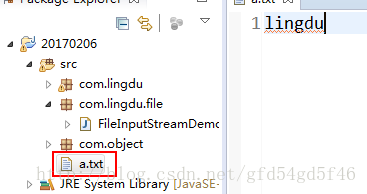
- 创建一个FileInputStream类的对象用来读取a.txt文件
package com.lingdu.file;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputStreamDemo {
/**
* 使用InputStream抽象类的子类FileInputStream类
* 从一个文件中读取流数据
*/
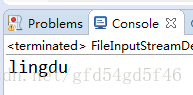
public static void test1() {
try {
//读取src下的a.txt文件
FileInputStream myStream = new FileInputStream("src/a.txt");
int a = 0;
//如果没读到文件尾,则继续执行
while((a = myStream.read()) != -1){
System.out.print((char)a);
}
//关闭流(使用完之后都要关闭)
myStream.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args) {
test1();
}
}
- 使用多态的特性使用子类FileInputStream
/**
* 使用多态的特性使用子类FileInputStream
*/
public static void test2() {
try {
InputStream is = new FileInputStream("src/a.txt");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}输出字节流OutputStream类

写到文件:FileOutputStream
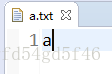
写入一个字符到文件中
/**
* 写入一个字符到文件中
* @author Administrator
*
*/
public class FileOutputStreamDemo {
public static void test1() {
try {
OutputStream os = new FileOutputStream("src/a.txt");
os.write(97);
os.flush();
os.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
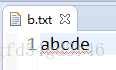
写入一个数组到文件
/**
* 写入一个数组到文件
*/
public static void test2() {
//方法比较笨拙不推荐使用,这里只是作为演示
byte myArray[] = new byte[5];
myArray[0] = 97;
myArray[1] = 98;
myArray[2] = 99;
myArray[3] = 100;
myArray[4] = 101;
try {
OutputStream os = new FileOutputStream("src/b.txt");
os.write(myArray);
os.flush();
os.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
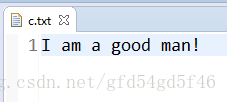
写入一个字符串到文件
/**
* 写入一个字符串到文件
*/
public static void test3() {
String myContent = "I am a good man!";
try {
OutputStream os = new FileOutputStream("src/c.txt");
os.write(myContent.getBytes());
os.flush();
os.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
FileInputStream 和 FileOutputStream 类
通过FileInputStream 和 FileOutputStream 类拷贝文件
步骤:
1、 使用FileInputStream类读取到文件
2、 使用FileOutputStream类写入到新文件
这里我在src目录下创建一个a.txt文件作为测试
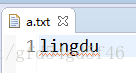
拷贝方法:
/**
* 读取文本文件,读取图片,读取视频
*/
public static void copyFile(String sourceName,String dest){
System.out.println("源文件:" + sourceName + ",目标文件:" + dest);
//1:先读取一个文件
//2:写入一个文件
try {
FileInputStream fis = new FileInputStream(sourceName);
FileOutputStream fos = new FileOutputStream(dest);
int a = 0;
//当还未到达文件尾时,循环读取
while((a = fis.read()) != -1){
//每读取一个字节过来,我们就写入到另一个文件里去
fos.write(a);//这里只会正常写入数据,不会把-1写进去
}
fos.flush();//把缓冲区里的数据强制写入到文件中
fos.close();//关闭输出流
fis.close();//关闭输入流
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
这是如果读取一个视频的话,速度就会变的很慢。
我用一个22mb的视频和1G的视频作为测试
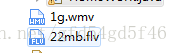
Main函数
public static void main(String[] args) {
//程序运行开始时间
long begin = System.currentTimeMillis();
HomeWork.copyFile("src/a.txt", "src/b.txt");
//程序运行时间=结束时间-开始时间 ,得到的是毫秒值。
long end = System.currentTimeMillis() - begin;
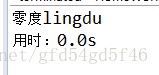
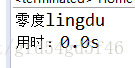
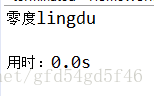
System.out.println("\n用时:" + end/1000f + "s");
}
复制22mb的视频都那么吃力,可想而知用1G的视频将会等待更久
所以我们要改进一下我们的程序
使用byte数组的方式进行复制
- 为了测试,我在src目录下创建了一个a.txt的文件用于测试,并且在txt文本中保存一些数据
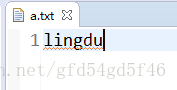
/**
* 由于读取速度太慢,所以要学习新的方法,让我们更快一点
*/
public static void test2(){
//设置每次写入3个字节
byte[] myArray = new byte[3];
try {
InputStream is = new FileInputStream("src/a.txt");
//如果到达文件尾,无法满足while的条件,不会执行while语句的内容
while(is.read(myArray) != -1){
for (int i = 0; i < myArray.length; i++) {
//打印一下每个字符
System.out.print((char)myArray[i]);
}
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}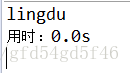
结果是可以复制的
问题:
- 我当前a.txt文件下保存的数据是lingdu,但是如果我在加一些内容会怎样呢?
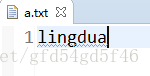
保存运行一下得到的不是我想要的数据 多出了du 两个字符
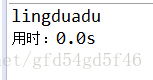
原因就是:
因为数组定义的长度是3
第一次读取到lin 输出
第二次读取到gdu 输出
第三次读取到a 因为读取时是覆盖操作 所以a覆盖了g之后,后面的全部输出 adu
所以最后的结果是 lingduadu
知道原因之后我们就要改进一下这个方法了
/**
* 问题:
* 当使用数组的时候,如果文件里的字符的长度不是数组的倍数的时候,拿到的数据会重复
*/
public static void test3(){
//这里的数组长度是指 每次读取3个字节
byte[] myArray = new byte[3];
//定义一个变量用来保存数组的长度
int len;
try {
InputStream is = new FileInputStream("src/a.txt");
//如果到达文件尾,无法满足while的条件,不会执行while语句的内容
while((len = is.read(myArray)) != -1){
//这样就解决了数据重复的问题
for (int i = 0; i < len; i++) {
System.out.print((char)myArray[i]);
}
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}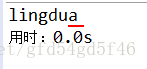
解决了这个重复的问题之后我们就可以继续进行复制了。
现在我们使用数组的方式对1G视频进行复制
/**
* 优化
* 使用数组进行读取
*/
public static void test4(){
//这里的数组长度是指 每次读取1024个字节
byte[] myArray = new byte[1024];
//定义一个变量用来保存数组的长度
int len;
try {
InputStream is = new FileInputStream("src/1.wmv");
OutputStream os = new FileOutputStream("src/test.wmv");
//如果到达文件尾,无法满足while的条件,不会执行while语句的内容
while((len = is.read(myArray)) != -1){
//定义过新的数组,这个数组要防止有多余的数据
byte descArray[] = new byte[len];
//这样就解决了数据重复的问题
for (int i = 0; i < len; i++) {
//System.out.print((char)myArray[i]);
descArray[i] = myArray[i];
}
os.write(descArray);
}
os.flush();
os.close();
is.close();
System.out.println("写入成功!");
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
使用数组的方式写入一个1G的视频才用了1.7秒左右,比刚刚使用1个字节写入快了几百倍

BufferedInputStream和BufferedOutputStream 类
性能优化
使用封装好的write(byte[] b, int off, int len)方法,简易代码。
/**
* 性能优化
* 1:使用封装好的方法直接使用write(myArray, 0, len);
*/
public static void test5(){
//这里的数组长度是指 每次读取1024个字节
byte[] myArray = new byte[1024];
//定义一个变量用来保存数组的长度
int len;
try {
InputStream is = new FileInputStream("src/1.wmv");
OutputStream os = new FileOutputStream("src/test.wmv");
//如果到达文件尾,无法满足while的条件,不会执行while语句的内容
while((len = is.read(myArray)) != -1){
//最后一次读取数据的时候,只把数组的第0个长度开始到数组的指定len(我们从流里最好一次实际读出的数据)
os.write(myArray, 0, len);
}
os.flush();
os.close();
is.close();
System.out.println("写入成功!");
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
使用封装好的方法要比自己定义数组数值快很多,而已省去了很多的代码,提高了开发效率
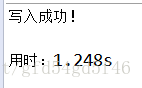
使用缓冲区 BufferedInputStream和BufferedOutputStream
/**
* 进一步性能优化
* 2:使用缓冲区 BufferedInputStream跟BufferedOutputStream
*/
public static void test6(){
//这里的数组长度是指 每次读取3个字节
byte[] myArray = new byte[1024];
//定义一个变量用来保存数组的长度
int len;
try {
//把原来的流装进一个类里
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("src/1g.wmv"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("src/test.wmv"));
//如果到达文件尾,无法满足while的条件,不会执行while语句的内容
while((len = bis.read(myArray)) != -1){
//最后一次读取数据的时候,只把数组的第0个长度开始到数组的指定len(我们从流里最好一次实际读出的数据)
bos.write(myArray, 0, len);
}
bos.flush();
bos.close();
bis.close();
System.out.println("写入成功!");
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
使用缓冲区写入数据的时候,速度快了1倍

ByteArrayInputStream 类
- 当我们没有文件的时候,如何使用流?
这时我们就要用到ByteArrayInputStream 类
/**
* 当我们没有文件的时候,如何使用流
*
*/
public static void test8(){
String content = "lingdu";
ByteArrayInputStream is = new ByteArrayInputStream(content.getBytes());
int i = 0;
while((i = is.read()) != -1){
System.out.print((char)i);
}
}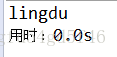
当文件里有中文的时候,会出现乱码
/**
* 新的问题:当文件里有中文的时候,可能会乱码
*
*/
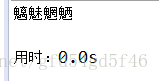
public static void test9(){
String content = "魑魅魍魉";
byte myArray[] = content.getBytes();
ByteArrayInputStream is = new ByteArrayInputStream(content.getBytes());
for (int i = 0; i < myArray.length; i++) {
System.out.print((char)myArray[i]);
}
System.out.println();
byte a = 0;
while((a = (byte)is.read()) != -1){
System.out.print((char)a);
}
}
如何解决乱码问题呢?
/**
* 解决乱码问题
*
*/
public static void test10(){
String content = "魑魅魍魉";
byte myArray[] = content.getBytes();
ByteArrayInputStream is = new ByteArrayInputStream(content.getBytes());
int len = 0;
try {
while((len = is.read(myArray)) != -1){
System.out.println(new String(myArray));
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
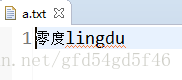
- 如果我要读取一个文本文件里面的中文呢?
我在src下创建一个a.txt,并写入数据
/**
* 读取文件
* 解决乱码问题
*
*/
public static void test11(){
InputStream is;
try {
is = new FileInputStream("a.txt");
byte myArray[] = new byte[6];
ByteArrayInputStream bais = new ByteArrayInputStream(myArray);
int len = 0;
while((len = is.read(myArray)) != -1){
System.out.println(new String(myArray));
}
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
运行结果并不会出现乱码

字符流
Reader类
优点:
对InputStream进行包装
比较擅长读取文本文件
还是拿刚刚的文件进行测试,为了解决中文问题,引用字符流
/**
* 引用字符流,来解决中文问题
* Reader抽象类,InputStreamReader实现类
*/
public static void test12() {
try {
//InputStreamReader(InputStream in, String charsetName) 可以设置文件的编码
Reader reader = new InputStreamReader(new FileInputStream("src/a.txt"), "UTF-8");
int a;
while((a = reader.read())!= -1){
System.out.print((char)a);
}
reader.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
使用数组进行读取
/**
* 字符流其实就是对字节流进行了包装
* 字符流读数组
*/
public static void test13() {
try {
Reader reader = new InputStreamReader(new FileInputStream("src/a.txt"), "UTF-8");
//字符长度越大,越不会出错
char myArray[] = new char[12];
int a;
while((a = reader.read(myArray))!= -1){
System.out.print(new String(myArray));
}
reader.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
BufferedReader类
性能优化:
- 使用BufferedReader 进行包装
/**
* 字符流
* BufferedReader
* 提高读取效率
*/
public static void test15() {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("src/a.txt"), "UTF-8"));
//准备读取
while (reader.ready()) {
//打印一行数据
System.out.println(reader.readLine());
}
reader.close();
} catch (UnsupportedEncodingException | FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Writer类
所谓有读取就有写入,所以引用字符输出流Writer,对OutputStream进行包装
- 写入数据到文件
/**
* 字符流
* Writer抽象类,OutputStreamWriter实现类
* 写入数据到文件
*/
public static void test14() {
try {
//true表示在尾部继续添加数据
Writer writer = new OutputStreamWriter(new FileOutputStream("c.txt",true));
//BufferedWriter bw = new BufferedWriter(writer);
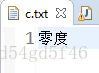
writer.write("零度");
writer.flush();
writer.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}数据已经写入到c.txt文件下了
BufferedWriter类
性能优化:
- 当然我们也可以让程序写快一些,就是使用BufferedWriter
/**
* 字符流
* BufferedWriter
* 提高写入字符流效率
*/
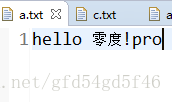
public static void test16() {
try {
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("a.txt")));
bw.write("hello 零度!");
bw.write("pro");
bw.flush();
bw.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Scanner 类
Scanner 类使读取文件更为简单
/**
*读取文件的时候要更方便
*/
public static void test18() {
try {
Scanner sc = new Scanner(new FileInputStream("a.txt"));
while(sc.hasNextLine()){
System.out.println(sc.nextLine());
}
System.out.println("读取完成!");
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}

printWriter类
对输出流进行包装,输出操作更简单了
/**
*为了能够输出数据的时候更方便,我们要引入printWriter
*/
public static void test17() {
try {
PrintWriter pw = new PrintWriter("a.txt");
pw.print("I am 零度! 我");
pw.print(18);
pw.print("岁");
pw.flush();
pw.close();
System.out.println("写入完成!");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









