







前言
我很感谢那些写书的大牛,真是因为他们的书籍才能让我快速进步。
第一章-面向服务体系结构soa
一、基于TCP协议的RPC
remote process call
1、实现方式 rmi webservice
2、传输对象序列化方式
java自带的 objectoutputstream、hessian进行序列化
二、基于HTTP协议的RPC 夸平台优势,无需考虑多线程,并发问题。
OSI模型有7层结构,每层都可以有几个子层,网络由下往上分为:
物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。IP协议对应于网络层,TCP协议对应于传输层,而HTTP协议对应于应用层,
1、网络接口层到 ip层 到 tcp层 到http层 (socket则是对TCP/IP协议的封装和应用(程序员层面上)。TPC/IP协议是传输层协议,主要解决数据如何在网络中传输,HTTP是应用层协议,主要解决如何包装数)
2、优势 跨平台,使用json和xml作为传输数据
3、URL链接风格 rpc和restful representational state tranfor
4、springmvc restful
@RequestMapping(value=”/provider/{serviername}/{time}”,method=RequestMethod.POST)
public String test(@PathVariable (“servicename”),@PathVariable (“time”)){
}
三、服务的路由与负载均衡
1、负载均衡方法
当服务的规模比较小时候,可以采用硬编码方式,将服务方式和服务地址写在代码中。或者用f5,enignx,lvs
当服务过多就需要一个可以动态注册和获取服务的地方。zookeper
2、负载均衡算法
3、zookeeper使用
第二章-分布式系统基础设施
一、分布式缓层memcached
二、分布式session
三、持久化存储
1、关系型数据库mysql
①业务插分,提高系统扩展性,开发和测试效率,系统部署稳定性
②复制策略,mysql的主从复制可能存在数据延迟现象,因为是异步。读和写分库操作
master和多个slave结构,但是这个存在单点故障,当master发生故障时候,系统将无法完成写入。所以可以采用dual-master,也就是master和master的结构。
③分表与分库,如果单个表的数据达到亿级别,可以将这个大表拆分成n个带number标示的表。
比如根据user_id%256进行存储。例如查询user_id为255的数据 可以查询select from order_1
分表可以解决单表查询效率低下的问题,但是无法解决在高并发下对数据库的频烦修改,因此需要分库。
2、hbase、redis、activemq
进行容错和单点故障采用。
activemq集群采用master-slave架构。基于文件系统和基于共享数据库的master-slave架构。
当系统规模增大,可以采用broker模式,将不相关的的queue和topic拆分到多个broker
四、消息系统
activeMq&jms
五、垂直化搜索引擎
lucene
第三章-互联网安全架构
一、xss (cross site scripting)攻击
俗称跨站脚本攻击。利用的是站点信任的用户,在网页中嵌入恶意脚本,可以盗取cookie,用户密码,下载执行病毒。
二、crsf(cross site request forgery)攻击
俗称跨站请求伪造。利用的是伪装来自信任用户的请求来利用受信任的网站。可以以你的名义向第三方网站发送恶意请求,比如发送邮件,发送短信,进行交易。
crsf防御,
1、将cookie设置成HttpOnly
2、增加token验证。
页面的增加一个隐藏域token,token由服务器端生成,传到前台。如果模拟提交,必须要带上token的值。这样就可以避免模拟请求了。。
3、通过Referer判断
referer里面记录了访问源头网站地址。获取这个请求的源头地址,然后和服务器比较,防止跨站。
三、sql注入 sql injection attacks and defens
sql注入防范:①使用jdbc的预编译 ②使用orm框架,会对特殊符号的值进行转义操作。③前台传入的时候进行转义操作或者验证。④避免密码明文存放,用hash加密。⑤处理好相应的异常,不要把异常抛向
四、文件上传漏洞
针对用户上传到服务器的文件需要加验证,防止客户上传可执行脚本或者文件获得服务器相应的权利。
每个文件的起始的字节内容是固定的,根据这些字节内容就可以确定文件内型,这几个字节俗称魔数。后台定义一个enum内型,记录所有内型和其对应的asic码。
可以利用imagemagic架包对图片加水印,压缩,缩放,破坏用户上传的二进制文件格式。
五、ddos(distributed denial of service)分布式拒绝服务攻击。
将大量肉鸡电脑联合起来,在某一时刻对某一主机进行访问,从而达到瘫痪主机功能
①syn flood
②dns query flood
③cc攻击
五、常用安全算法
1、数字摘要:
①mda ②sha ③十六进制编码 ④base64编码 ⑤对称加密算法 ⑥非对称加密算法
2、为什么要认证
如果经由http协议进行的大量数据都是明文的,那么如果有人对网络核心节点进行监控,就有可能抓取到敏感的数据。
wireshark 工具。
六、Oauth协议
1、出现缘由
第三方服务如果想接入某一平台的应用,传统的肯定涉及到密码等用户敏感信息认证。如果在不涉及用户密码情况下完成认证。
用户,平台商,第三方开发者。
oauth授权过程:
第四章-系统稳定性
- 在线日志分析
一般我们部署项目都是在Linux服务上面的,所以利用命令去查看日志文件是一个合格程序员的基本功。记得有次去面试的时候,面试官问我如果系统down掉,需要咋弄,我第一反应自然是看日志了,接着他就问我怎么去定位错误,然后我的回答弱爆了,利用SSH去服务器将日志文件拷贝到本地,然后用编辑器打开,分析日志。如果日志文件小的话,这样操作没问题,可是如果当日志文件达到G级别的话,这样做的弊端就出现了,其实他这样问的意思就是想看看我对linux常用命令的了解情况。
常用命令:
cat -n test.log :显示文本所有内容,带行数号。cat命令只适用于文本内容较少情况,当文本内容过多,我就需要用到带分页命令
more test.log: 按住enter显示下一行,空格显示下一页。f显示下一屏内容,b显示上一屏幕内容。有时候我们需要查找文件里面指定字符串的文件,并且高亮显示,这时候less命令就出来了。和gerp命令有点类似
less test.log 然后我们按住“/”输入需要查找的内容有时候我们项目发布新版本,需要我们一遍操作,一遍查看日志进行验证。上面的哪些命令运行之后只能看到文件当前里面的内容,不能动态的查看后来追加到日志里面的内容,这时候就需要用到我们的tail命令
tail -f 20 test.log -f表示可以动态显示追加的内容,20表示显示文件末尾到前面20行数据
head -f 20 test.log 命令是和tail相反的,从头部开始显示sort 默认是按照字符排序的 -n参数是按照数字顺序的 -r参数是按照逆顺序的。
字符统计
wc -c参数表示文件字节数 -l参数文件行数 -L参数文件最大行的长度 -w文件包含的单词数
查看重复行的次数 :uniq -c参数表示每行显示该数值重复的次数
字符串查找
grep -c gao log.txt -c参数为显示该查找值所在行数。
文件查找
find /usr/java -name log.txt
find . print 递归打印当前目录所有文件
定位执行程序位置
whereis mysql
表达式求值
expr 2 + 2
生成日志归档文件
tar -cf log.tar temp temp2 将temp和temp2目录下文件打包成log.tar
-c是生成新的tar -f参数指的是文件名称
tar -xf log.tar 解压包到当前路径
tar 对应的命令有 :
-x:解压 -c: 建立压缩档案 -t:查看内容
-r:向压缩归档文件末尾追加文件
-u:更新原压缩包中的文件 -z:有gzip属性的
-v :显示所有过程
-f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。 必须的还有一些复杂的命令组合以后用到再看吧。
集群监控
1、监控指标
监控指标主要分以下几类:系统load,cpu负载过高,磁盘I/O过于繁忙,内存使用过多导致频繁Full GC ,qps(Query Per Second)过高
常用命令如下:
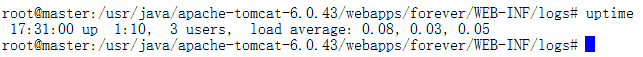
uptime : load average后三个数表示1,5,15分钟系统的load值。只要系统load值在3和5之间都算正常
top命令查看cpu信息:
top: shirft+m 可以按照内存大小排序
top |grep Cpu 可以显示cpu的信息
磁盘剩余空间:
df -h :磁盘剩余空间
网络拥堵情况:
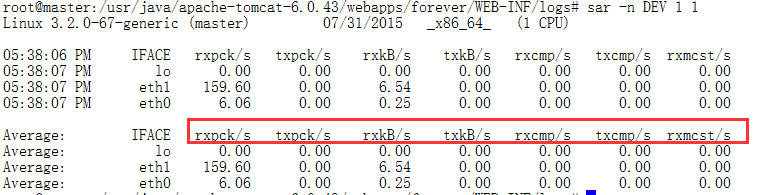
sar -n DEV 1 1:
rxpck:表示每秒接收数据包数量
txpck:每秒发出的数据包数量
rxkb :每秒接收到的字节数
txkb :每秒发送的字节数
rxcmp:每秒收到的压缩包数量
txcmp 每秒发送的压缩包数量
rxmcst 每秒收到的广播包数量
磁盘i/o吞吐量:

iostat -d -k
kB_read/_wrtn s 每秒读/写
kB_read/wrtn 总读/写总量
内存查看:

free -m(m为单位)
buffer里面为缓冲的
free=第一行的(free)+buffers+cached
vastat: 也可以查看swap/Io
还有一些可以检查性能的有:
response time:相应时间
qps:Query Per Second 每个页面加载时间心跳监测
集群情况下,当某一天服务器挂了需要第一时间知道,可以利用程序代码去控制。比如zookeeper或者手动写代码去控制
- 流量控制
暂时没接触的,就当了解。
当大量并发过来了,可以利用activeMq队列去处理请求
性能优化
一、服务稳定性
①依赖管理,那个服务调用那个服务,分布式soa
②优雅降级
③服务分级
④开关
⑤应急预案
二、高并发系统设计
①操作原子性,可见性,有序性。
②多线程同步 线程锁使用
③数据一致性
④系统可扩展性
⑤并发减少库存
三、性能优化
①前端优化
YSlow工具 、页面响应时间、方法响应时间btrace工具、gc日志分析(minor GC ,Full GC )
、数据库查询故障排查
第五章-数据分析
- 列表内容














 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









