







 本文介绍了字典树(Trie树)的基本概念及其在文本处理中的应用。字典树是一种特殊的树形结构,用于高效地存储和检索大量字符串。文章详细解释了如何通过结构体表示字典树节点,以及如何实现插入和查询操作。
本文介绍了字典树(Trie树)的基本概念及其在文本处理中的应用。字典树是一种特殊的树形结构,用于高效地存储和检索大量字符串。文章详细解释了如何通过结构体表示字典树节点,以及如何实现插入和查询操作。
前言
在写完了KMP算法的博客之后,我下定决心,一定要写出一篇关于“AC自动机的博客”。AC自动机实际上就是字典树上的KMP算法。所以,考虑到广大同学不一定会写Trie树,特此在此处写了一篇文章介绍介绍这种数据结构。
1.字典树的外貌
(字典树)又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。——360百科
看下面一张图:
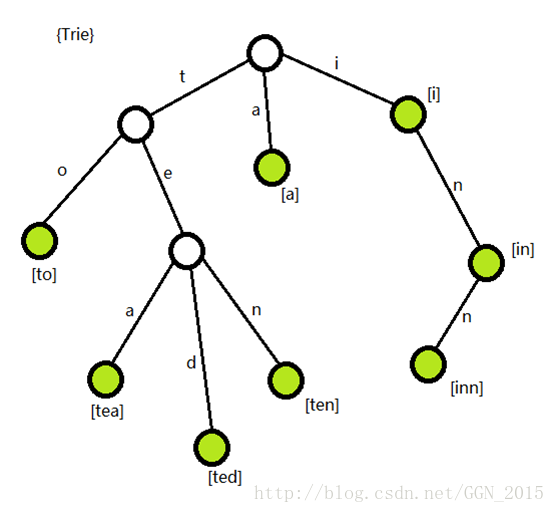
这棵字典树所表示的字符串集合为{ a , to , tea , ted , ten , i , in , inn }。其中每一个被染色的结点都是一个单词的结尾,表示从根节点到当前结点所走过的的路径是一个储存的字符串。我们被染色的结点中储存它所对应的字符串的信息。这就好像是一个字典,我可以在一个字符串所对应的结点中储存这个单词的定义、用法、以及其它信息(附加信息:i结点的附加信息用val[i]表示)。val[i]>0表示这是一个单词,val[i]=0表示这个结点不是一个单词的结尾。
我们用next[i][j]表示,i的第j个儿子。假设这个trie树中的所有字母都是小写字母,那么我们可以用j=0表示标有小写字母‘a’的边,j=25表示标有小写字母‘z’的边。用这条性质,我们可以尝试着去写一下代码。
接下来是字典树的结点用结构体的表示:
int idx(char c)//用于返回一个字符的索引值
{
return c-'a';
}
struct Trie
{
int next[MaxNode][26];//结点的权值
int val[MaxNode];//所有子结点
int size;//结点总数
Trie()
{
memset(next[0],0,sizeof(next[0]));
}
...//字典树的查询结点和插入结点函数
};2.字典树的查询结点和插入结点函数
先看一下插入结点的代码:
struct Trie
{
...//同上文数据定义部分
void insert(char* str,int Value)//插入一个字符串,并把附加信息值赋为Value
{ //要注意Value!=0
int nodeNow=0,n=strlen(str);//nodeNow:当前结点,n:字符串的长度
//0号结点表示字典树的树根
for(int i=0;i<n;i++)//每次判断字符串中的一个字符
{
int charNow=idx(str[i]);//计算这个字符的索引数
if(next[nodeNow][charNow]==0)//如果这个结点不存在
{
next[nodeNow][charNow]=++size;//申请一个新的节点
memset(next[size],0,sizeof(next[size]));//初始化
val[size]=0;//因为它是一个过程中的点,而不是字符串的末尾,所以权值为0
}
nodeNow=next[nodeNow][charNow];//"当前结点"转移到下一个下一个节点身上
}
val[nodeNow]=Value;//把最后找到的末尾结点附上一个属性值
}
};然后查询结点的代码和上文是非常像的。
struct Trie
{
...//同上文数据定义部分
int Search(char* str)
{
int nodeNow=0,n=strlen(str);
for(int i=0;i<n;i++)
{
int charNow=idx(str[i]);
if(next[nodeNow][charNow]==0)//如果结点不存在
return 0;//直接返回0
nodeNow=next[nodeNow][charNow];//光标移动到下一结点
}
return val[nodeNow];//找到之后返回结点的权值
}
};3.后记
Trie树是一种简单的数据结构,以上就是它的全部内容。
在学习了Trie树之后,再配合上KMP的算法思想,同学们就可以去进修“AC自动机”算法了。
给一个友情链接:
友情链接1:神奇的KMP——线性时间匹配算法(初学者请进)
友情链接2:我与线段树的故事(纯新手请进)
友情链接3:AC自动机详解
赶稿匆忙,如有谬误,望谅解。

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









