









转自http://blog.csdn.net/yinwenjie/article/details/52208294
1、概述
在“系统存储”专题中,我们将按照“从上至下”的顺序向读者介绍整个“系统存储”体系。在这个专题中我们将至少介绍机械硬盘的主要结构、磁盘阵列的分类、操作系统的EXT文件系统、NAS文件共享存储方案、分布式文件系统重要技术点和分布式文件系统示例。最后如果有时间我们将自行设计一款分布式文件系统。下图可以大致描述笔者的写作思路:
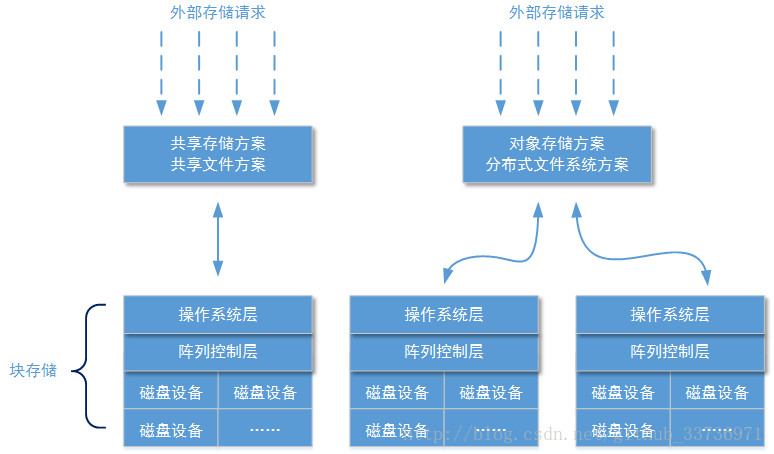
本专题首先会花费几篇文章向读者介绍块存储的知识,包括最底层机械硬盘、固态硬盘的构造结构和工作过程。块存储的知识中我们还将介绍磁盘阵列技术,包括磁盘阵列的组织方式和设备类型。最后块存储知识中我们介绍操作系统中的文件系统,包括EXT系列文件系统和XFS文件系统(会顺带提到Windows操作系统使用的NTFS文件系统)。接下来的几篇文章我们会介绍搭建在块存储方案上的关系型数据库,文章会主要讲解MySQL数据库,包括MySQL数据库中最常被使用的InnerDB存储引擎、索引构造方式以及MySQL数据库集群的几种构造方式。
由于在《标准Web系统的架构分层》这篇文章中,笔者已经大致说明了系统存储专题的写作过程,所以本文就直接开始块存储技术的介绍了。笔者计划花费两到三篇文章的篇幅,向大家介绍块存储技术的主要知识点。
2、块存储方案基本构成
块存储技术的构成基础是最下层的硬件存储设备,这些硬件存储设备可能是机械硬盘也可能是固态硬盘。一个操作系统下可以独立控制多个硬件存储设备,但是这些硬件存储设备的工作相对独立,通过Centos操作系统的df命令看到的也是几个独立的设备文件。通过阵列控制层的设备可以在同一个操作系统下协同控制多个存储设备,让后者在操作系统层被视为同一个存储设备。
操作系统控制多个独立的存储设备。下图表示的三个硬盘设备在操作系统下独立工作,在操作系统下显示了三个设备文件:
这里写图片描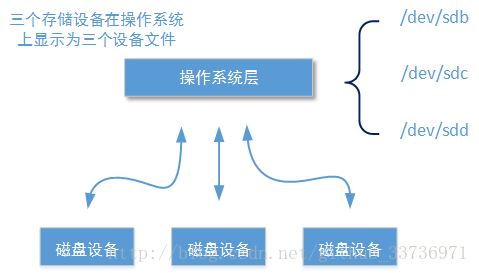
操作系统通过阵列控制设备控制多个存储设备。阵列控制设备在市场上从低端到高端有很多选择。目前市场上的一些主板就自己集成了阵列控制芯片,如果中小企业需要硬盘阵列设备可以购买民用级产品,市场价格普遍在几千块左右。高端设备可以购买IBM/EMC提供的商业级/工业级设备,市场价格从几万到几千万不等。笔者将在本专题中详细介绍硬盘阵列的重要技术知识点。
这里写图片描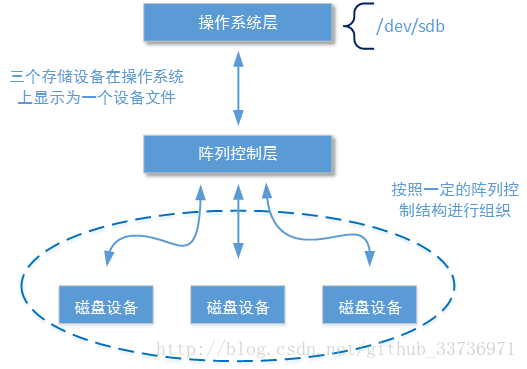
为什么操作系统层可以做到以上两种存储设备的组织方案同时兼容呢?因为操作系统层通过各种文件系统规则,可以过滤掉各种存储设备的不同硬件特性。EXT1、EXT2、EXT3、EXT4系列文件系统和XFS文件系统都是Linux操作系统下常用的文件系统,Btrfs文件系统是最近今年Linux操作系统下越来越流行的新一代操作系统。这些文件系统的共同特点是:通过文件系统内部能够辨识的一个文件索引结构规范对下层的硬件设备结构进行封装,以便起到屏蔽和代理操作下层硬件结构的目的。 那么当下层存储设备不是机械硬盘而是固态硬盘又或者是阵列控制设备时,又是怎样的工作原理呢?本专题中将会一一解答这些问题。对于操作系统中的文件系统,我们将着重介绍EXT系列文件系统的结构。
3、机械硬盘
3-1、机械硬盘结构
这里写图片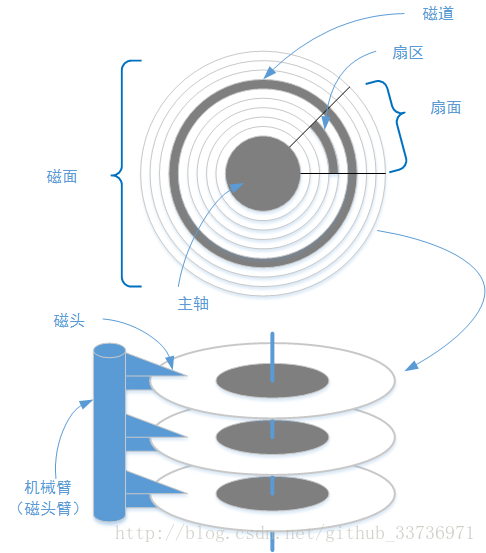
现在的机械硬盘技术都非常成熟了,存储容量也出现了几何级增长。但是机械硬盘的基本结构却一直没有太大的变化:它基本上是由机械臂(磁头臂)、主轴、多个成对的磁头和磁面构成。在每个磁面上被分成多个磁道、多个扇面和多个扇区,它们的具体存在形式如下:
磁面上会有多个磁道,它们在一个磁面上拥有不同的磁道编号。从磁面最外围离主轴最远的磁道到磁面最内侧离主轴最近的磁道,它们的编号从0开始,分别是0、1、2、3、4…….N(N大于等于10000,依据硬盘制作工艺不同而不同)。磁头将会顺着磁道基于磁面的转动读取数据,并且可以在各个磁道间切换位置。
实际情况下,外部将要存储到硬盘上的数据不会一次性写满整个磁道,读取数据到外部时也不需要读取整个磁道的数据。这是因为一个磁道被分为多个弧段,这些弧段称之为扇区。扇区是硬盘上存储数据的最基本物理单元。注意,目前市场上无论哪个供应商提供的机械硬盘产品,每个物理扇区单元固定的存储容量都是512字节。只是根据硬盘密度不一样,单位磁面下的扇区数量也不一样。既然扇区是数据存储的基本单元,就意味着一次硬盘读写操作的最小数据量就是512字节。
那么问题来了,是不是觉得512字节太小了点?是的,很多时候操作系统层面请求读写操作的文件都会大于一个扇区的单位容量。那么在物理层面上就需要两个甚至更多个扇区来存储这个文件,那么怎样来规划存储一个文件的若干扇区在磁面上的分布,从而达到减少读取时间的目的呢?
操作系统层面会将物理硬盘上两个或者多个能够连续读取的扇区组成合并成一个区域,称之为“簇”。注意,这两个或者多个能够连续读取的扇区不一定在物理上是连续的。这是什么原因呢?这是因为硬盘转动的速度很快(标准速度为7200转/分),当磁头完成一个“扇区1”的读写后还来不及读取下一个连续的“扇区2”相邻的扇区就“飞”过去了,要等磁面再转动一圈到预定“扇区2”的位置才能继续进行读写。
所以一个簇在物理磁面的分布可能是不连续的。实际上各个硬盘生产商都会设置一个“跳跃因子”来确定能够连续读取的扇区。如下图所示,四个不存在于连续物理位置的扇区构成一个簇。这样保证了磁面在旋转一圈的情况下就可以完成一个簇的全部读写。
这里写图片描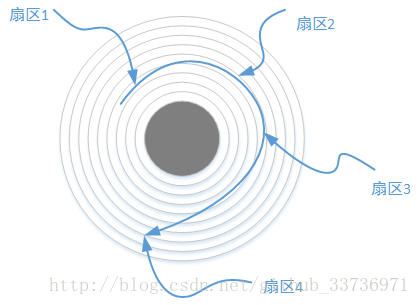
最后说明一点,虽然扇面是硬件层面上机械磁盘读取数据的最小单元,但是“簇”才是操作系统层面上读取磁盘数据的最小单元。我们后文将讲解EXT文件系统和Btrfs文件系统,这两种文件系统定义的簇大小是不一样的。例如EXT文件系统的族大小可以有1KB(两个扇区)、2KB(四个扇区)、4KB(八个扇区)等多种选择。那么如果一个文件太小,不需要用完一个簇怎么办呢?没办法,它有需要使用至少一个簇的硬盘空间。也就是说,在操作系统存储一个文件时,即使一个簇没有占满,剩下的簇空间也不能再使用了。这就是为什么一个文件在操作系统上有两个大小:一个是文件的实际大小、另一个是文件占用硬盘空间的大小。
3-2、机械硬盘性能瓶颈
3-2-1、影响机械硬盘性能的因素
当需要从硬盘上读取一个文件是,首先会要求磁头定位到这个文件的起始扇区。这个定位过程包括两个步骤:一个是磁头定位到对应的磁道,然后等待主轴马达带动盘片转动到正确的位置,这个过程所花费的时间被称为寻址时间。也就是说寻址时间实际上包含两部分:磁头定位到磁道的时间为寻道时间,等待盘片转动到正确位置的时间称为旋转等待时间。
硬盘寻址的目的是为了找到将要读取的文件的起始扇区,并开始去取数据。这就可以解释为什么硬盘上读取一个100MB大小的文件和读取1000个100KB大小的文件时间是完全不一样的现象了:通常来说一个100MB的文件是存储在硬盘上可以连续读取的扇区上的,也就是说当硬盘需要读取这个文件时只需要进行一次寻址(为什么说是“通常”呢?因为前提是硬盘上至少要有一端连续空白的扇区,如果此时硬盘上碎片太多可能就找不到这样的连续空白区域了);而读取1000个文件时,由于这些文件的起始存储位不连续,所以每次都要进行寻址操作。寻址时间是评价机械硬盘性能的重要指标,这个指标和硬盘转数、磁头数有直接关系:
硬盘转速越快的硬盘,在同样的寻址算法控制条件下将能够更快的将正确的扇区转动到磁头下方。但是硬盘转速也不能做得无限快,因为硬盘转速越快要求的磁面工艺、主马达工艺也就越高,并且产生的噪音、温度也会成几何级增加。现在民用级、商用级和工业级硬盘上最常采用三种转速选择:5400转/分、7200转/分和10000转/分。
磁头数,现在的机械硬盘中一般都包含了多个盘片并且分别使用独立的磁头。这样做的主要作用是在硬盘密度不变的情况下增加机械硬盘的容量。实际上这样的做法也可以增加一定的硬盘性能,因为读取存储在不同磁面上的文件时,它们的寻道时间可以相对独立。但是其对性能的提示只能是有限的,因为这些盘片共享同一个主轴马达。
机械硬盘的工作原理导致了它的工作性能会远逊于内存,现在主流的7200转硬盘外部传输速度的理论峰值大概也就是200MB/s。那么问题又来了,天才的硬件工程师难道就没有办法增加机械硬盘读写性能了吗?
答案是否定的,硬件工程师为机械硬盘集成了缓存,并采用预读机制读取当前扇区的临近扇区。举个例子,当硬盘读取一个文件所在扇区时,会将这个扇区临近的若干扇区上的数据一同读取出来并存储到硬盘缓存中。这样做的原因是依据计算机科学中得一个著名原理:局部性原理。
局部性原理包括三层含义。时间局部性,如果一个信息项正在被访问,那么在近期它很可能被再次访问。空间局部性,在近期将要被使用的信息很可能与现在正在使用的信息在空间地址上是临近的。顺序局部性,在典型程序中,除转移类指令外,大部分指令是顺序进行的。局部性是所有高速缓存设计的基本原理依据。
说人话,局部性原理在硬盘硬件设备设计中被应用的依据是:当一个文件被读取时,在它临近扇区所存储的文件数据也将在近期被读取。所以硬盘会预先读取后者到缓存中,以便在不久的将来,这些数据被请求读取时直接从缓存中向外部设备输出文件数据。
局部性原理不止适合高速缓存这样的硬件设计,它也适用于软件设计:一个程序90%的时间运行在10%的代码上。
3-2-2、顺序读写和随机读写
上一小节已经提到硬盘的顺序读写和随机读写有非常大的性能差异,其中主要的原因是两者寻址操作上所耗费的时间存在巨大差异。那么顺序读写和随机读写的差异到底有多大呢?仅仅是靠上一小节的文字描述显然不能给读者数值化的认识,所以在本小节中我们将使用一款名叫CrystalDiskMark的测试软件,让读者具体体会一下两者的巨大区别:
这里写图片描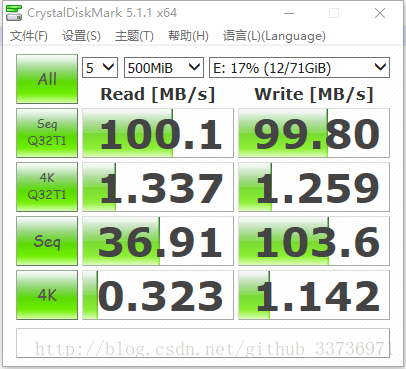
以上是笔者编写文稿使用的某品牌笔记本上5400转机械硬盘的测试截图(题外话,这款笔记本用起来真想骂人),这个机械硬盘属于中低端硬盘,但是相同级别的硬盘在万元级以下的笔记本上却被大量使用,所以这个测试结果很能说明一些问题。首先解释一下以上截图中的几个主要项目:
在测试结果的上方写明了这是一个针对E盘符的测试,每一单项所测试的读写数据总量为500MB,并且每个单项测试分别执行5次。执行5次后综合每次的测试结果取平均值,最终形成这个单项的测试结果。
“Seq”和“Seq Q32T1”这两个选项分别代表没有IO队列的单线程顺序读写和一个深度为32的IO队列的单线程顺序读写,其中Q32代表队列深度为32,T1表示IO线程数为1。这个队列长度和IO线程数量都可以在CrystalDiskMark进行调整。
4K表示进行小文件读写测试时这些小文件的大小,这些4K文件将进行随机读和随机写测试。4K测试项是衡量固态硬盘性能的重要测试项,直接描述了固态硬盘的性能,这个我们将在下文进行说明。
从上图的测试结果来看,顺序读写的性能远远高于随机读写的性能,使用了IO队列的读性能又远远高于没有使用IO队列的读性能(且写性能基本持平)。当然以上的测试数值和选用的机械硬盘型号是密切相关的,但无论数值结果如何变化,最后都会符合以上所描述的性能规则。
例如如果您对7200转企业级硬盘进行测试,那么所有测试项的横向数值会高出很多;如果您的INTEL SSD 企业级固态硬盘卡进行测试,那么横向数值又会再高出很多倍。下图展示了INTEL SSD 750 企业级固态硬盘卡的测试结果(截图来源于网络):
这里写图片描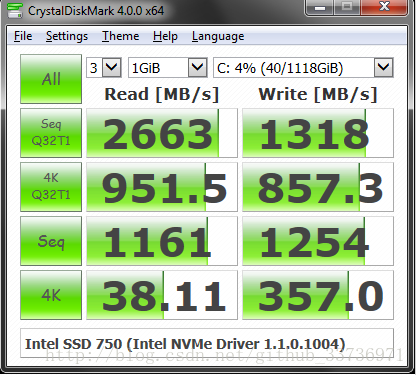
4、固态硬盘
看了以上来源于网络的截图后,是不是感觉整个世界瞬间清爽了。目前固态硬盘的生产工艺日趋成熟,单位容量价格也趋于下降通道。固态硬盘替代机械硬盘是一个必然趋势,迟早有一天后者将被完全替换。本节向读者介绍固态硬盘大致的构成结构和工作过程。
4-1、固态硬盘结构
固态硬盘的结构和工作原理和机械硬盘大不一样。它主要由大量NAND Flash颗粒、Flash存储芯片、SSD控制器控制芯片构成。他们三者的关系通过下图进行表示:
这里写图片描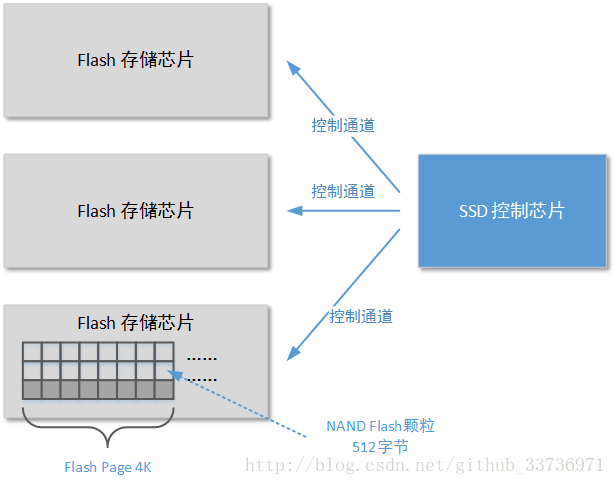
在一个固态硬盘上会有若干Flash存储芯片(可能有2颗、4颗、8颗等数值),每颗存储芯片内部包含大量NAND Flash颗粒,目前(2016年)NAND Flash颗粒的制作工艺已经达到12nm(2012年的主流工艺是90nm)。无论NAND Flash颗粒的制作工艺如何,每一个单位的存储容量都是512字节。多个Flash存储芯片被一个SSD主控芯片,目前能够生成SSD主控芯片的厂商不多,例如:SandForce、Marvell、三星、JMicron、Intel等。SSD主控芯片的主要工作包括识别来自于外部接口(PCI-E、SATA等)的控制指令、在将数据写入Flash存储芯片前接收和压缩这些数据、在将数据送入内存前解压从Flash存储芯片读取的数据、完成 LBA和PBA的映射转换(这个过程将在下一小节进行介绍)等工作。
虽然一个单位的NAND Flash颗粒存储容量是512字节,但是SSD主控芯片进行数据操作的最小单位并不是512字节。在SSD操作规则中定义的一个数据操作的最小单位为4KB,它包括了8个单位的NAND Flash颗粒称为Flash Page(有的资料中称为Host Page)。如果将固态硬盘和机械硬盘进行对比,那么机械硬盘中的一个最小的操作单位就是扇区,单位大小就是512字节;固态硬盘中的一个最小操作单位就是Flash Page,单位大小为4K。这就解释了上文中提到的硬盘读写性能测试中,为什么测试软件会专门针对4K大小的文件进行读写测试了。
既然固态硬盘中最小的操作单位为4K,那么在进行操作系统文件系统格式化的时候就需要注意了。文件系统中设置的一个簇大小不能小于4K且最好为4K的整数倍,这样才能保证充分发挥固态硬盘的性能。
固态硬盘不依靠磁头定位和主马达旋转确定数据的物理位置,所以固态硬盘没有寻址时间。SSD控制芯片拥有的多个控制通道可以让它同时向多个Flash存储芯片发送读写指令,这类似于机械磁盘上可以独立工作的磁头臂,但却没有共享主轴马达的限制。这些特点足以保证固态硬盘的性能远远高于机械硬盘。这也让我们认识到,以下因素影响着固态硬盘的最终性能:
SSD主控芯片:上文已经说到SSD主控芯片几乎完成了固态硬盘上所涉及的所有控制指令操作和数据读写操作。不同的SSD主控芯片内置的FTL算法不一样、数据压缩/解压算法不一样、控制通道数也不一样,所以固态硬盘采用哪种SSD主控芯片将直接影响其性能,目前最好的控制芯片来自于Intel,最广泛使用的控制芯片来自于三星。
FLash存储芯片工艺:本文提到的NAND Flash颗粒只是其中一种使用最广泛的型号,实际上还有NOR Flash颗粒等。NAND Flash颗粒又分为两种子类型:MLC存储颗粒与SLC存储颗粒。在相同单位体积下,MLC可以提供两倍于SLC的存储空间,而后者在存储响应时间和存储稳定性上又高于前者。所以MLC存储颗粒市场占有率更高,SLC存储颗粒更倾向于企业级市场。
4-2、固态硬盘工作过程
================================
(接下文)














 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









