







“回归”一词的来历:
原本是用来根据双亲的身高预测其一下代的身高,如果双亲高度高于平均值,其子女身高也倾向于比平均值高,但低于双亲身高。而双亲身高低于平均值的,子女身高倾向于比均值低,但是高于双亲身高。 预测值的两类都倾向于回归到均值,而不是与父母身高相同。Galton在多项研究中都注意到了这个现象。后来用这种方式来寻找一堆测量数据点的数学关系,而不是均值回归,但这种方法仍被称为回归。虽然这个单词与数值预测没有关系。
线性回归:
简单的理解就是寻找一条直线或曲线来拟合数据点。
假设我们有一个数据集
D={(x1,y1),(x2,y2)...(xm,ym)}
(m =样本数量),
(xi,yi)
是数据集中第
i
样本。
那么用来进行学习的假设函数:
f(x)=wTx+b=w1x1+w2x2...+wnxn+b
(在ANA的机器学习课程里直接用 θ 来表示参数 w,b , θ是一个n+1维的向量 : f(x)=θ0+θ1x+θ2。。。θn=θTx )*
接下来寻找最佳拟合线:(调参)
首先,评估一个模型好坏,要先看预测值
f(x)
与真实值
y
之间差,误差越小模型预测准确度越高。线性回归里,即数据点到拟合线距离和最小。一般用
在ANA的课程里,采用了梯度下降法来寻找最优参数解。
算法先要初使化赋值如图红圈位置,我们的目的是使其下降到低部最低值。通过对代价函数求导的方式来确定移动的方向,这里切线的斜率就是这个点的导数,而下降多少用 α 来控制, α 称为learning rate。如果 α 过大,可能会错过最低值而无法收敛。如果过小,过程会很慢。下降的过程重复下列公式直到收敛到低部某个最小值。在更新 θ 时,需要同步更新所有 θ 值。
θj=θj−α∂∂θjJ(θ0,θ1)(j:特征索引值)
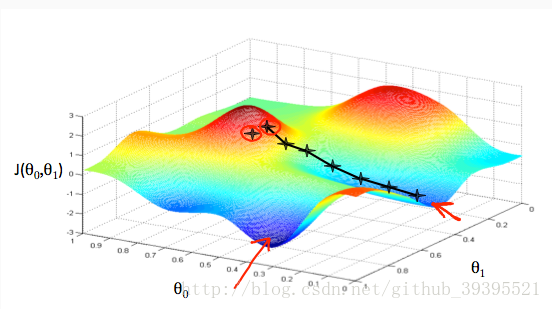
(图片和公式来自cousera上斯坦福机器学习课程)
注:由图可知,不同初始点下降的最终位置也不同,这代表梯度下降有可能是局部最小值而不是全局。
梯度下降应用到线性回归上,代入公式:
这里分开了 θ0和θ1 ,第二项乘 xi 是求偏导的结果。因为 J 本身是一个 二次凸函数,结果最终会收敛于全局最低点。(注:需补知识点:凸函数)
以下是来自c站ANA课程的对
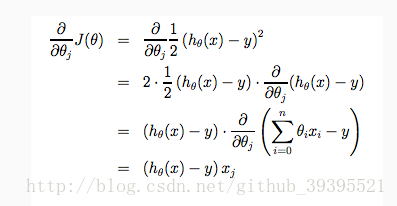
凸函数:对区间[a,b]上定义的函数,如果它对区间 的任意两点
x1,x2
均满有
f(x1+x22)≤f(x1)+f(x2)2
, 则称
f
为区间[a,b]上的凸函数。对实数集上的函数,可通过二阶求导来判断:若结果在区间上非负,则为凸函数,为0则为严格凸函数。(引自周志华《机器学习》)
另一种最小化
求解
如果用向量和矩阵分别表示参数和数据集,方程可表示为:
Ew^=(y−Xw^)T(y−Xw^)
对 w^ 求导为零后可得:
w^=(XTX)−1XTy
相关知识点:
SSE=∑mi=1(f(x)−y)2














 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









