







lucene的版本是5.5.3
Eclipse中导入包:
project -> Build Path -> Configure Build Path -> Libraries -> Add External Jars
需要导入的包:
第一个,核心类库,Lucene-core-5.5.3.jar,其中包括了常用的文档,索引,搜索,存储等相关核心代码。
第二个,分词类库,Lucene-analyzers-common-5.5.3.jar,这里面包含了各种语言的词法分析器,用于对文件内容进行关键字切分,提取。
第三个,搜索类库,Lucene-queryparser-5.5.3.jar,提供了搜索相关的代码,用于各种搜索,比如模糊搜索,范围搜索,等等。
其他,Lucene-highlighter-4.0.0.jar,这个jar包主要用于搜索出的内容高亮显示。
建立原文件(待索引):
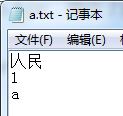
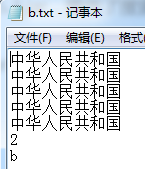
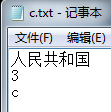
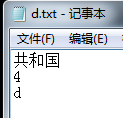
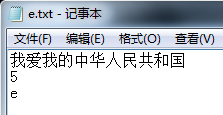
建立索引
import java.io.BufferedReader;
public class LuceneIndex {
//把字符串转化成path,用到java.nio.file.Path
File file = new File("f:\\lucene\\index");
Path indexDir = file.toPath();
File folder = new File("f:\\lucene\\test");
// 索引器
private IndexWriter writer = null;
public LuceneIndex() {
try {
//索引文件的保存位置,open方法里不再接受一个File而是Path,使用的是JDK1.7的新特性
//Directory dir = FSDirectory.open(FileSystems.getDefault().getPath("f:\\lucene\\index"));
Directory dir = FSDirectory.open(indexDir);
//分析器,不需要提供版本号
Analyzer analyzer = new StandardAnalyzer();
//配置类
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
iwc.setOpenMode(OpenMode.CREATE);//创建模式 OpenMode.CREATE_OR_APPEND 添加模式
writer = new IndexWriter(dir, iwc);
} catch (Exception e) {
e.printStackTrace();
}
}
// 将要建立索引的文件构造成一个Document对象,并添加一个域"content"
private Document getDocument(File f) throws Exception {
Document doc = new Document();
FileInputStream is = new FileInputStream(f);
Reader reader = new BufferedReader(new InputStreamReader(is));
//把文本文档的两个属性:路径和内容加入到了两个 Field 对象中
Field pathField = new StringField("path", f.getAbsolutePath(),Field.Store.YES);
Field contenField = new TextField("contents", reader);
//再把两个Field加到document中
doc.add(contenField);
doc.add(pathField);
return doc;
}
public void writeToIndex() throws Exception {
//遍历目录下的所有文本文档
if (folder.isDirectory()) {
String[] files = folder.list();
for (int i = 0; i < files.length; i++) {
File file = new File(folder, files[i]);
Document doc = getDocument(file);
System.out.println("正在建立索引 : " + file + "");
//把document加到索引中
writer.addDocument(doc);
}
}
}
public void close() throws Exception {
writer.close();
}
public static void main(String[] args) throws Exception {
// 声明一个对象
LuceneIndex indexer = new LuceneIndex();
// 建立索引
Date start = new Date();
indexer.writeToIndex();
Date end = new Date();
System.out.println("建立索引用时" + (end.getTime() - start.getTime()) + "毫秒");
indexer.close();
}
}得到索引文件
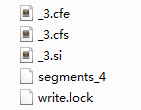
每修改一次原文件后新建一次索引,文件名的数值加1
进行搜索
import java.io.File;
public class LuceneSearch {
// 声明一个IndexSearcher对象
private IndexSearcher searcher = null;
// 声明一个Query对象
private Query query = null;
private String field = "contents";
File file = new File("f:\\lucene\\index");
Path indexDir = file.toPath();
//搜索器
public LuceneSearch() {
try {
//索引文件的保存位置
Directory dir = FSDirectory.open(indexDir);
IndexReader reader = DirectoryReader.open(dir);
//根据IndexReader创建IndexSearch
searcher = new IndexSearcher(reader);
} catch (Exception e) {
e.printStackTrace();
}
}
//返回查询结果
public final TopDocs search() {
System.out.println("正在检索");
try {
//方法一:用QueryParser类,用到分析器的唯一类
Analyzer analyzer = new StandardAnalyzer();
//创建parser来确定要搜索文件的内容,第一个参数为搜索的域
QueryParser parser = new QueryParser(field,analyzer);
// 解析关键字,包装成Query对象
query = parser.parse("中国");
Date start = new Date();
//获得前十条结果
TopDocs results = searcher.search(query, 10);
Date end = new Date();
System.out.println("检索完成,用时" + (end.getTime() - start.getTime())
+ "毫秒");
return results;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
//打印结果
public void printResult(TopDocs results) {
ScoreDoc[] h = results.scoreDocs;
if (h.length == 0) {
System.out.println("对不起,没有找到您要的结果。");
} else {
for (int i = 0; i < h.length; i++) {
try {
Document doc = searcher.doc(h[i].doc);
System.out.print("这是第" + i + "个检索到的结果,文件名为:");
System.out.println(doc.get("path"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
System.out.println("--------------------------");
}
public static void main(String[] args) throws Exception {
LuceneSearch test = new LuceneSearch();
TopDocs h = null;
h = test.search();
test.printResult(h);
}
}
搜索结果:只要文件中含有“中”或者“国”,都会匹配

/*方法二:用TermQuery类,直接搜索项,因为一个字是一个项。所以必须使项和被搜索内容相匹配
Term t = new Term(field,"国");
Query query = new TermQuery(t);
*/
/*方法三:TermRangeQuery类,文本项在范围内搜索,这里的参数要传BytesRef类型
BytesRef a = new BytesRef("a");
BytesRef d = new BytesRef("d");
TermRangeQuery query = new TermRangeQuery(field, a, d, true, true);
*/
/*方法四:用NumericRangeQuery.newIntRange()方法,数字范围内搜索,
前提是必须在建立索引时把数字建成NumericFIeld
NumericRangeQuery<Integer> query = NumericRangeQuery.newIntRange(field, 1, 3, true, true);
*/搜索无结果
/*方法五:用prefixQuery类,搜索以指定字符串开头的
Term t = new Term(field,"中");
PrefixQuery query = new PrefixQuery(t);
*/搜索结果:所有含“中”的都匹配

/*方法六:用BooleanQuery类组合多个Query查询条件
Term t1 = new Term(field,"中");
Query query1 = new TermQuery(t1);
Term t2 = new Term(field,"国");
Query query2 = new TermQuery(t2);
@SuppressWarnings("deprecation")
BooleanQuery query = new BooleanQuery();
query.add(query1,BooleanClause.Occur.MUST);
query.add(query2,BooleanClause.Occur.MUST);
*/搜索结果:文件中必须同时含有“中”和“国”才匹配

/*方法七:用PhraseQuery类,搜索词语,可指定词和词之间的距离
@SuppressWarnings("deprecation")
PhraseQuery query = new PhraseQuery();
query.setSlop(5);
query.add(new Term(field,"中"));
query.add(new Term(field,"国"));
*/因为条件是“中”和“国”距离为5。即匹配“中华人民共和国”

/*方法八:用WildcardQuery类,进行通配符查询
Query query = new WildcardQuery(new Term(field,"*和?"));
*/搜索无结果
/*方法九:用FuzzyQuery类,进行模糊查询
Query query = new FuzzyQuery(new Term(field,"圆"));
*/搜索无结果
/*方法十:用MatchAllDocsQuery类,匹配所有文档,按评分高低输出
Query query = new MatchAllDocsQuery();
*/搜索结果:将所有文件按评分高低输出

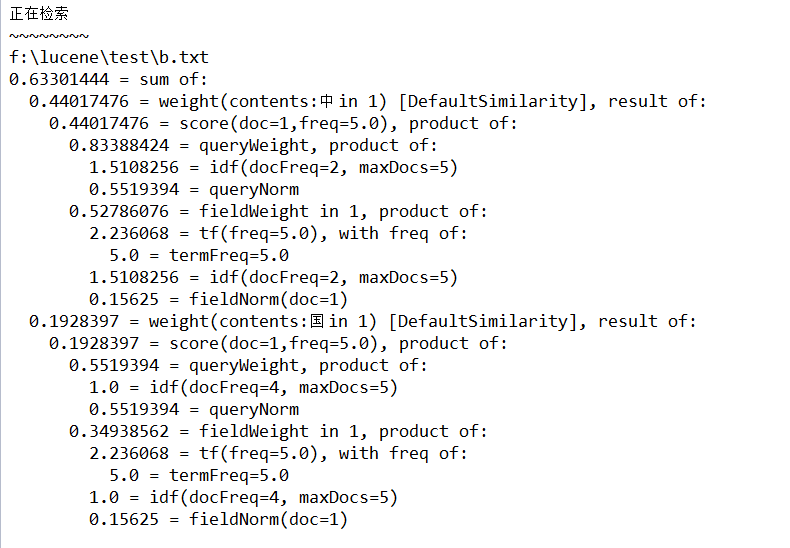
显示评分
//获得前十条结果
TopDocs results = searcher.search(query, 10);
//获得评分
for(ScoreDoc match : results.scoreDocs){
Explanation explanation = searcher.explain(query, match.doc);
System.out.println("~~~~~~~~");
Document doc = searcher.doc(match.doc);
System.out.println(doc.get("path"));
System.out.println(explanation.toString());
}
得到分词的结果(英文)
public class AnalyzerDemo {
private static final String[] examples = {
"The quick brown fox jumped over the lazy dog",
"XY&Z Corporation - xyz@example.com",
"to be or not to be"
};
private static final Analyzer[] analyzers = new Analyzer[]{
new WhitespaceAnalyzer(),
new SimpleAnalyzer(),
new StopAnalyzer(),
new StandardAnalyzer()
};
//得到分析器分词的结果
public static void displayTokens(Analyzer analyzer,String text) throws IOException{
TokenStream stream = analyzer.tokenStream("contents,", new StringReader(text));
//Lucene 3.1开始废弃了TermAttribute和TermAttributeImpl,用CharTermAttribute和CharTermAttributeImpl代替。
//TokenStream 是继承于AttributeSource,其包含Map,保存从class 到对象的映射,从而可以保存不同类型的对象的值,
//将CharTermAttributeImpl添加到Map 中,并保存一个成员变量。即 保存Token对应的term文本
CharTermAttribute term = stream.addAttribute(CharTermAttribute.class);
stream.reset();
while(stream.incrementToken()){
//从TokenStream中提取Token
System.out.print("[" + term.toString() + "]");
}
stream.close();
//stream必须调用reset方法和close方法,否则报错
}
private static void analyze(String text) throws IOException{
System.out.println("Analyzing \"" + text + "\"");
for(Analyzer analyzer : analyzers){
String name = analyzer.getClass().getSimpleName();
System.out.println(" " + name + ":");
System.out.println(" ");
displayTokens(analyzer,text);
System.out.println("\n");
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
String[] strings = examples;
if(args.length > 0){
strings = args;
}
for(String text : strings){
try {
System.out.println("*******************************************");
analyze(text);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}

这里分词结果出现空白,是因为后两种分析器默认 去掉常用词
得到分词的结果(中文)
处理中文,需要导入
E:\java\lucene-5.5.3\analysis\smartcn中的
lucene-analyzers-smartcn-5.5.3.jar包
public class ChineseDemo {
private static String[] strings = {"道德经"};
private static Analyzer[] analyzers = {
new SimpleAnalyzer(),
new StandardAnalyzer(),
new CJKAnalyzer(),
new SmartChineseAnalyzer()
};
public static void analyze(String string,Analyzer analyzer) throws IOException{
StringBuffer buffer = new StringBuffer();
TokenStream stream = analyzer.tokenStream("contents", new StringReader(string));
CharTermAttribute term = stream.addAttribute(CharTermAttribute.class);
stream.reset();
while(stream.incrementToken()){
buffer.append("[");
buffer.append(term.toString());
buffer.append("]");
}
stream.close();
String output = buffer.toString();
System.out.println(output);
}
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
for(String string : strings){
for(Analyzer analyzer : analyzers){
analyze(string,analyzer);
}
}
}
}















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









