HTTP(HyperText Transfer Protocol)是一套计算机通过网络进行通信的规则。计算机专家设计出HTTP,使HTTP客户(如Web浏览器)能够从HTTP服务器(Web服务器)请求信息和服务,HTTP目前协议的版本是1.1。HTTP是一种无状态的协议,无状态是指,当浏览器发送请求给服务器的时候,服务器响应,但是同一个浏览器再发送请求给服务器的时候,它会响应,但是他不知道你就是刚才那个浏览器(在传输层上知道传给哪个电脑哪个进程,但是在应用层HTTP上它只是知道收到了HTTP请求,作出响应即可,当然在Web应用中用cookie,session就另当别论了),简单地说,就是服务器不会去记得你,所以是无状态协议
。
在服务器端不保留连接的有关信息.HTTP遵循请求(Request)/应答(Response)模型。Web浏览器向Web服务器发送请求,Web服务器处理请求并返回适当的应答。所有HTTP连接都被构造成一套请求和应答。
HTTP使用内容类型,是指Web服务器向Web浏览器返回的文件都有与之相关的类型。所有这些类型在MIME Internet邮件协议上模型化,即Web服务器告诉Web浏览器该文件所具有的种类,是HTML文档、GIF格式图像、声音文件还是独立的应用程序。大多数Web浏览器都拥有一系列的可配置的辅助应用程序,它们告诉浏览器应该如何处理Web服务器发送过来的各种内容类型。
HTTP通信机制
是在一次完整的HTTP通信过程中,Web浏览器与Web服务器之间将完成下列7个步骤:
(1)
建立TCP连接
在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80
(2)
Web浏览器向Web服务器发送请求命令
一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令
例如:GET/sample/hello.jsp HTTP/1.1
(3)
Web浏览器发送请求头信息
浏览器发送其请求命令之后,还要以头信息的形式向Web服务器发送一些别的信息,之后浏览器发送了一空白行来通知服务器,它已经结束了该头信息的发送。
(4)
Web服务器应答
客户机向服务器发出请求后,服务器会客户机回送应答,
HTTP/1.1 200 OK
应答的第一部分是协议的版本号和应答状态码
(5)
Web服务器发送应答头信息
正如客户端会随同请求发送关于自身的信息一样,服务器也会随同应答向用户发送关于它自己的数据及被请求的文档。
(6)
Web服务器向浏览器发送数据
Web服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
(7)
Web服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
在http 1.0的版本中,浏览器的每次请求(也就是对每一个页面的访问)都要求建立一次单独的连接,在处理完每一次的请求后,就自动释放连接。(这点我们应该都有感觉,比如我们访问一个页面,当该页面在浏览器中显示出来的时候,我们可以拔掉网线,此时该页面上的信息并不会丢失。)而当我们请求的网页文件中有很多图片、音乐、电影等信息时,服务器返回的信息中并不直接包含图片数据,而只是保存该图片的链接,当浏览器进行解释的时候,遇到图片的url时,才向服务器发出对图片的请求信息。可见如果一个网页中包含多个图片数据时,将会频繁的与服务器建立连接,与释放连接,这无疑会造成资源的浪费。
http 1.0 请求模式
而http 1.1则可以在一次连接中处理多个请求,并且多个请求可以重叠进行,不需要等待一个请求结束后再发送下一个请求。
使用Wireshark抓TCP、http包
打开Wireshark,选择工具栏上的“Capture”->“Options”,界面选择如图1所示:

图1 设置Capture选项
一般读者只需要选择最上边的下拉框,选择合适的Device,而后点击“Capture Filter”,此处选择的是“HTTP TCP port(80)”,选择后点击上图的“Start”开始抓包。
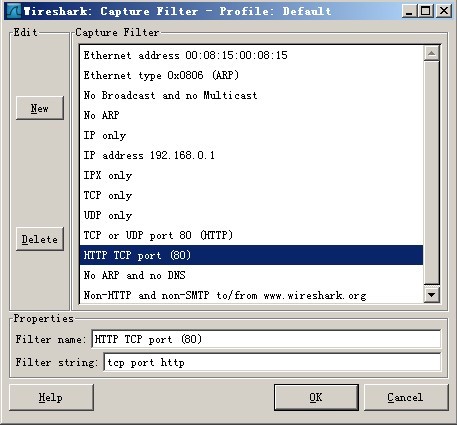
图2 选择Capture Filter
例如在浏览器中打开http://image.baidu.com/,抓包如图3所示:
http://www.blogjava.net/images/blogjava_net/amigoxie/40799/o_http%e5%8d%8f%e8%ae%ae%e5%ad%a6%e4%b9%a0-%e6%a6%82%e5%bf%b5-3.jpg
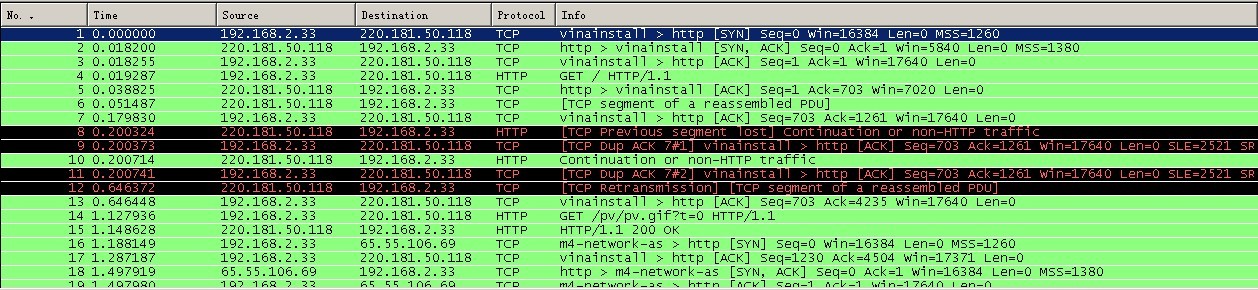
图3 抓包
在上图中,可清晰的看到客户端浏览器(ip为192.168.2.33)与服务器的交互过程:
1)No1:浏览器(192.168.2.33)向服务器(220.181.50.118)发出连接请求。此为TCP三次握手第一步,此时从图中可以看出,为SYN,seq:X (x=0)
2)No2:服务器(220.181.50.118)回应了浏览器(192.168.2.33)的请求,并要求确认,此时为:SYN,ACK,此时seq:y(y为0),ACK:x+1(为1)。此为三次握手的第二步;
3)No3:浏览器(192.168.2.33)回应了服务器(220.181.50.118)的确认,连接成功。为:ACK,此时seq:x+1(为1),ACK:y+1(为1)。此为三次握手的第三步;
4)No4:浏览器(192.168.2.33)发出一个页面HTTP请求;
5)No5:服务器(220.181.50.118)确认;
6)No6:服务器(220.181.50.118)发送数据;
7)No7:客户端浏览器(192.168.2.33)确认;
8)No14:客户端(192.168.2.33)发出一个图片HTTP请求;
9)No15:服务器(220.181.50.118)发送状态响应码200 OK
……
HTTP请求格式
当浏览器向Web服务器发出请求时,它向服务器传递了一个数据块,也就是请求信息,HTTP请求信息由3部分组成:
l
请求方法URI协议/版本
l
请求头(Request Header)
l
请求正文
下面是一个HTTP请求的例子:
GET/sample.jspHTTP/1.1
Accept:image/gif.image/jpeg,*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)
Accept-Encoding:gzip,deflate
username=jinqiao&password=1234
(1)
请求方法URI协议/版本
请求的第一行是“方法URL议/版本”:GET/sample.jsp HTTP/1.1
以上代码中“GET”代表请求方法,“/sample.jsp”表示URI,“HTTP/1.1代表协议和协议的版本。
根据HTTP标准,HTTP请求可以使用多种请求方法。例如:HTTP1.1支持7种请求方法:GET、POST、HEAD、OPTIONS、PUT、DELETE和TARCE。在Internet应用中,最常用的方法是GET和POST。
URL完整地指定了要访问的网络资源,通常只要给出相对于服务器的根目录的相对目录即可,因此总是以“/”开头,最后,协议版本声明了通信过程中使用HTTP的版本。
(2) 请求头(Request Header)
Accept:image/gif.image/jpeg.*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible:MSIE5.01:Windows NT5.0)
Accept-Encoding:gzip,deflate.
消息头主要是用来向服务器传达某种信息或指示。如告诉服务器自己的终端(User-Agent)是什么(如果是浏览器则返回相应的浏览器型号),终端所可以解释的类型(Accept)是什么,是从哪个页面提交的请求(Referer),以及浏览器所能解释的语言(Accept-Language)等等。我们这里拿Accept-Language来举个例子,大家都知道google在中国大陆显示的是简体中文,而在其它的国家则显示对应的语言,这个是怎么做到的呢?其实就是浏览器向服务器递交的请求信息中包含了Accept-Language,而我们的浏览器默认是zh-cn,然后服务器在接受到该信息时返回对应的页面。
我们可以通过以下方法来验证一下:
1、打开浏览器->工具->internet选项->常规选项卡
2、选择"语言",可见默认的语言是中文
3、选择"添加",选择一种语言,然后调节一下优先顺序
(3) 请求正文
请求头和请求正文之间是一个空行,这个行非常重要,它表示请求头已经结束,接下来的是请求正文。请求正文中可以包含客户提交的查询字符串信息:
username=jinqiao&password=1234
在以上的例子的HTTP请求中,请求的正文只有一行内容。当然,在实际应用中,HTTP请求正文可以包含更多的内容。
HTTP请求方法我这里只讨论GET方法与POST方法
l
GET方法
GET方法是默认的HTTP请求方法,我们日常用GET方法来提交表单数据,然而用GET方法提交的表单数据只经过了简单的编码,同时它将作为URL的一部分向Web服务器发送,因此,如果使用GET方法来提交表单数据就存在着安全隐患上。例如
从上面的URL请求中,很容易就可以辩认出表单提交的内容。(?之后的内容)另外由于GET方法提交的数据是作为URL请求的一部分所以提交的数据量不能太大
l
POST方法
POST方法是GET方法的一个替代方法,它主要是向Web服务器提交表单数据,尤其是大批量的数据。POST方法克服了GET方法的一些缺点。通过POST方法提交表单数据时,数据不是作为URL请求的一部分而是作为标准数据传送给Web服务器,这就克服了GET方法中的信息无法保密和数据量太小的缺点。因此,出于安全的考虑以及对用户隐私的尊重,通常表单提交时采用POST方法。
从编程的角度来讲,如果用户通过GET方法提交数据,则数据存放在QUERY_STRING环境变量中,而POST方法提交的数据则可以从标准输入流中获取。
HTTP应答
与HTTP请求相似,HTTP响应也由3个部分构成,分别是:
l 协议状态版本代码描述
l 响应头(Response Header)
l 响应正文
下面是一个HTTP响应的例子:
HTTP/1.1 200 OK
Server:Apache Tomcat/5.0.12
Date:Mon,6Oct2003 13:23:42 GMT
Content-Length:112
<html>
<head>
<title>HTTP响应示例<title>
</head>
<body>
Hello HTTP!
</body>
</html>
协议状态代码描述HTTP响应的第一行类似于HTTP请求的第一行,它表示通信所用的协议是HTTP1.1服务器已经成功的处理了客户端发出的请求(200表示成功):
HTTP/1.1 200 OK
响应头(Response Header)响应头也和请求头一样包含许多有用的信息,例如服务器类型、日期时间、内容类型和长度等:
Server:Apache Tomcat/5.0.12
Date:Mon,6Oct2003 13:13:33 GMT
Content-Type:text/html
Last-Moified:Mon,6 Oct 2003 13:23:42 GMT
Content-Length:112
响应正文响应正文就是服务器返回的HTML页面:
<html>
<head>
<title>HTTP响应示例<title>
</head>
<body>
Hello HTTP!
</body>
</html>
响应头和正文之间也必须用空行分隔
。
l HTTP应答码
HTTP应答码也称为状态码,它反映了Web服务器处理HTTP请求状态。HTTP应答码由3位数字构成,其中首位数字定义了应答码的类型:
1XX-信息类(Information),表示收到Web浏览器请求,正在进一步的处理中
2XX-成功类(Successful),表示用户请求被正确接收,理解和处理例如:200 OK
3XX-重定向类(Redirection),表示请求没有成功,客户必须采取进一步的动作。
4XX-客户端错误(Client Error),表示客户端提交的请求有错误 例如:404 NOT
Found,意味着请求中所引用的文档不存在。
5XX-服务器错误(Server Error)表示服务器不能完成对请求的处理:如 500
对于我们Web开发人员来说掌握HTTP应答码有助于提高Web应用程序调试的效率和准确性。
安全连接
Web应用最常见的用途之一是电子商务,可以利用Web服务器端程序使人们能够网络购物,需要指出一点是,缺省情况下,通过Internet发送信息是不安全的,如果某人碰巧截获了你发给朋友的一则消息,他就能打开它,假想在里面有你的信用卡号码,这会有多么糟糕,幸运的是,很多Web服务器以及Web浏览器都有创立安全连接的能力,这样它们就可以安全的通信了。
通过Internet提供安全连接最常见的标准是安全套接层(Secure Sockets layer,SSl)协议。SSL协议是一个应用层协议(和HTTP一样),用于安全方式在Web上交换数据,SSL使用公开密钥编码系统。从本质讲,这意味着业务中每一方都拥有一个公开的和一个私有的密钥。当一方使用另一方公开密钥进行编码时,只有拥有匹配密钥的人才能对其解码。简单来讲,公开密钥编码提供了一种用于在两方之间交换数据的安全方法,SSL连接建立之后,客户和服务器都交换公开密钥,并在进行业务联系之前进行验证,一旦双方的密钥都通过验证,就可以安全地交换数据。



























 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









