









背景
我们在之前的文章中介绍过如何通过PAI内置的TensorFlow框架实验基于Cifar10的图像分类,文章链接:https://yq.aliyun.com/articles/72841。使用Tensorflow做深度学习做深度学习的网络搭建和训练需要通过PYTHON代码才能使用,对于不太会写代码的同学还是有一定的使用门槛的。本文将介绍另一个深度学习框架Caffe,通过Caffe只需要填写一些配置文件就可以实现图像分类的模型训练。
关于PAI的深度学习功能开通,请务必提前阅读https://help.aliyun.com/document_detail/49571.html
文末提供了相关下载链接。
数据介绍
本文使用的数据是开源数据集cifar10,这份数据是一份对包含6万张像素为32*32的彩色图片,这6万张图片被分成10个类别,分别是飞机、汽车、鸟、毛、鹿、狗、青蛙、马、船、卡车。数据集截图:

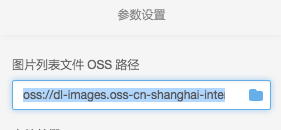
目前这份数据已经内置在PAI提供的公共数据集中,以jpg格式存储。任何PAI的用户都可以在深度学习组件的数据源OSS路径中直接输入,
* 测试数据: oss://dl-images.oss-cn-shanghai-internal.aliyuncs.com/cifar10/caffe/images/cifar10_test_image_list.txt
* 训练数据:oss://dl-images.oss-cn-shanghai-internal.aliyuncs.com/cifar10/caffe/images/cifar10_train_image_list.txt
如图:
格式转换
目前PAI上的Caffe框架只支持特定的格式,所以需要首先将jpg格式的图片进行格式转换。
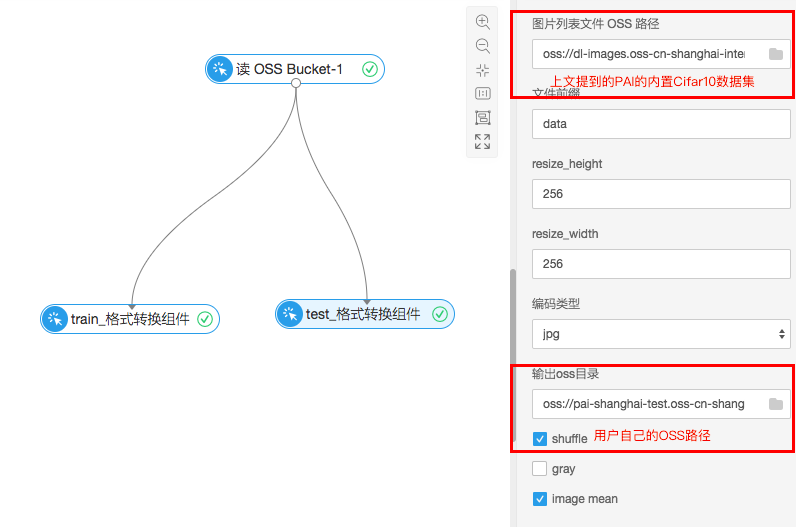
经过格式转换,可以在自己的OSS路径下生成如下文件,训练数据和测试数据各一份。

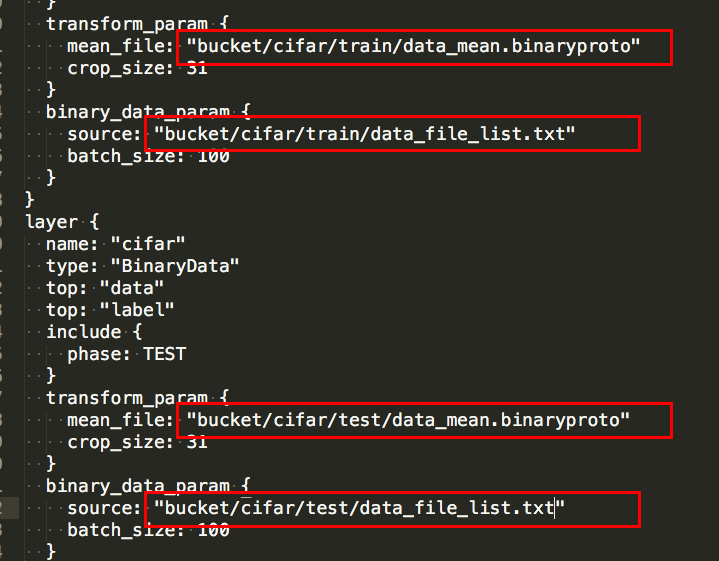
需要记录对应的OSS路径用于net文件的填写,假设路径名分别是:
训练数据data_file_list.txt:bucket/cifar/train/data_file_list.txt
训练数据data_mean.binaryproto:bucket/cifar/train/data_mean.binaryproto
测试数据data_file_list.txt:bucket/cifar/test/data_file_list.txt
测试数据data_mean.binaryproto:bucket/cifar/test/data_mean.binaryproto
Caffe配置文件
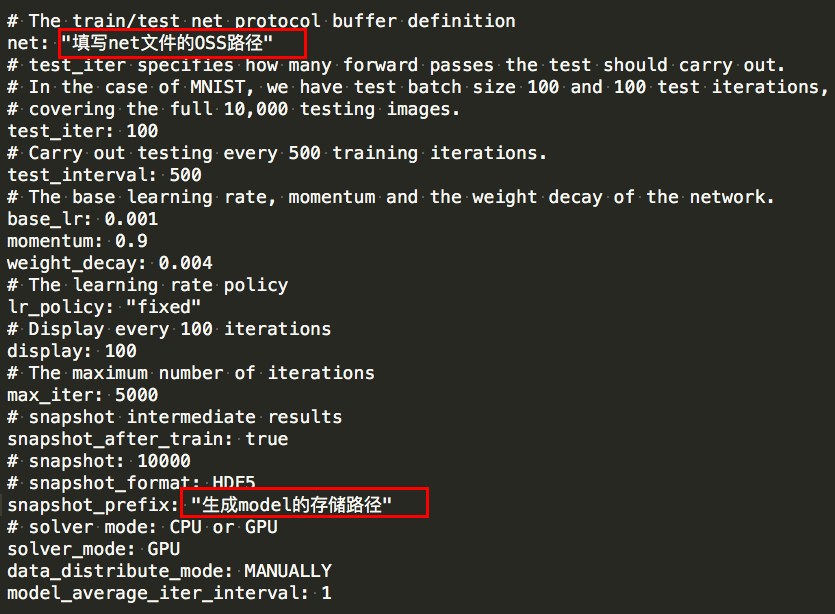
Net文件编写,对应上文格式转换生成的路径:
Solver文件编写:
运行
将编辑好的Solver文件和Net文件全部传到OSS上,拖动caffe训练组件如图,在Sovler文件路径上选择OSS上提交的Solver文件,运行即可。
生成的图片分类model文件可以在OSS对应路径下查看,可以用以下模型进行图片分类

日志查看可以参照本文开头提供的“Tensorflow实现图像分类”。
其它
免费体验:阿里云数加机器学习平台
作者微信公众号(与作者讨论):















 1695
1695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









