







 本文介绍了懒惰普利姆算法用于构造最小生成树的步骤,包括从源点开始遍历邻接表,将边加入优先队列,出队最轻边并考察其端点,直至所有边被考察。算法的时间复杂度为O(ElogE),其中E为边的数量。文章还给出了算法的实现细节和完整代码。
本文介绍了懒惰普利姆算法用于构造最小生成树的步骤,包括从源点开始遍历邻接表,将边加入优先队列,出队最轻边并考察其端点,直至所有边被考察。算法的时间复杂度为O(ElogE),其中E为边的数量。文章还给出了算法的实现细节和完整代码。
算法描述
lazy普利姆算法的步骤:
1.从源点s出发,遍历它的邻接表s.Adj,将所有邻接的边(crossing edges)加入优先队列Q;
2.从Q出队最轻边,将此边加入MST.
3.考察此边的两个端点,对两个端点重复第1步.
示例
从顶点0开始,遍历它的邻接表:边0-7、0-2、0-4、0-6会被加入优先队列Q.
顶点0的邻接表搜索完毕后,边0-7是最轻边,所以它会出队,并加入MST.
如下图:
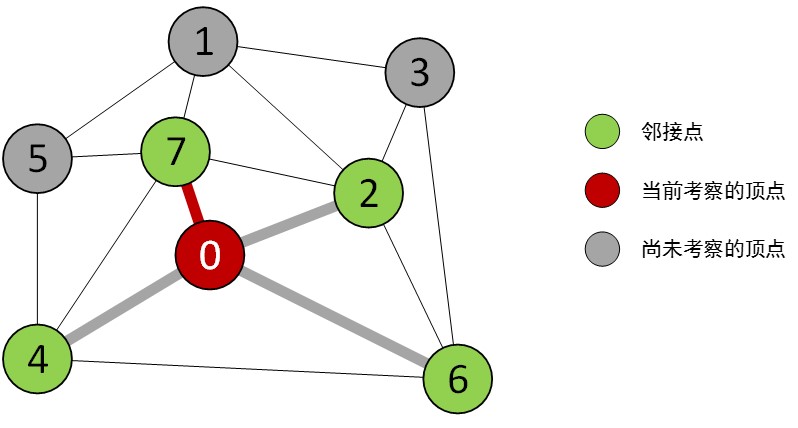
边0-7出队后,开始考察边的两个端点:
顶点0已经访问过了,跳过;
顶点7还未探索,开始探索顶点7.对7的邻接表进行访问和第一步类似.
我们找到最轻边7-1并加入MST
如下图:
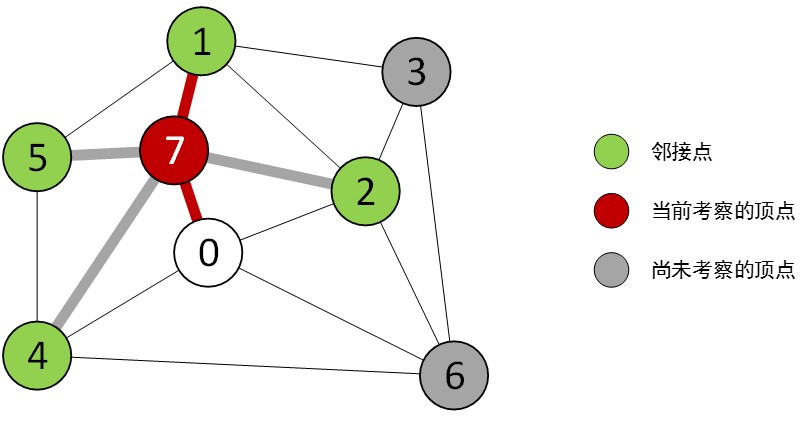
对每条边重复,当所有边都考察完毕,我们就得到了最小生成树,如下图:
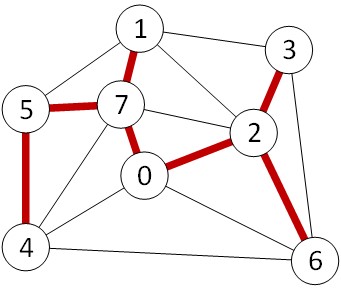
时间复杂度
扫描所有边会耗时O(E ).
由于所有的边都会入队,优先队列调整的操作耗时O(logE ).
那lazy方式最差就是O(ElogE ).
其中E 是图的边数.
算法实现
算法的第一步,将源点s所有的邻接的边加入Q,如下:
/**
* 找出从源点出发的所有的crossing edges,并用一个优先队列维护他们
*
* 原理:
* 将对未访问的邻接点进行遍历当作一次切断(graph-cut),则源点和邻接点间的边就是crossing edge
* 根据贪心策略求MST的要求,要加入的边必须是最轻边(权重最小的边),
* 故而将crossing edges加入优先队列,这样便可用O(logN)的时间找出最小权重边
*
* @param src 源点
*/
private void search(int src) {
visited[src] = true;
for(Edge e : g.vertices()[src].Adj) {
WeightedEdge we = (WeightedEdge)e;
if(!visited[we.to])
crossingEdges.offer(we);
}
}算法的第二步和第三步如下:
/**
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









