







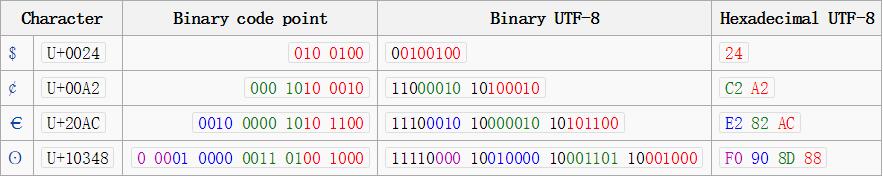
ASCII(American Standard Code):8-bit characters
'a' -> 0110 0001缺点:可表达字符太少
Unicode:32-bit characters
'n' -> 6e 00 00 00缺点:浪费存储空间,不兼容C语言函数
UTF-8
编码方法:在开头补1和0
Python’s Unicode Support
默认使用UTF-8编码,如果想设置其他编码方式,在代码开头写上:
# -*- coding: <encoding name> -*-bytes -> utf-8/ascii
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'str -> bytes
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'ord():获取字符的整数表示
chr():编码转换为对应的字符
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'编码应用
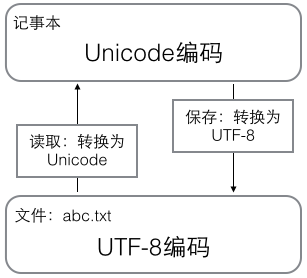
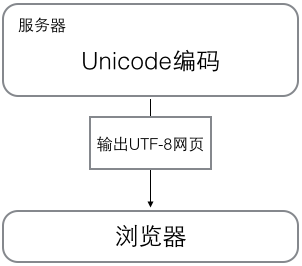
图源:廖雪峰的python教程
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









