






O_DIRECT
Andrea Arcangeli
andrea@suse.de
SuSE Kernel Developer
http://www.suse.com
Copyright (C) 2001 Andrea Arcangeli SuSE
UKUUG Manchester, 29 June - 1 July 2001
(page 1)
Buffered I/O
In all modern operative systems all the I/O by default is buffered by some kernel cache (often by multiple layers of logical caches).
Caching all the I/O as default policy is a critical improvement for most of the programs out there because it allows us to reduce dramatically the number of I/O operations during the runtime of the system.
There are many heuristics used to optimally collect the cache when we run low on memory (page replacement).
(page 2)
Only disadvantages of the buffered I/O
When the I/O is buffered the harddisk does DMA from/to the cache, not from/to the userspace source/destination buffer allocated by the user application.
Those copies in turn imposes the CPU and memory cost of moving the data from kernel cache to userspace destination buffer for reads, and the other way around for writes.
This is of course a feature when such CPU copy avoids us to start the I/O, but if there is cache pollution maintaining a cache and passing through it for all the I/O will be totally useless.
(page 3)
Self caching applications
One real world case where the kernel cache is totally useless are the self caching applications (DBMS most of the time).
Self caching means that the application will keep its own I/O cache in userspace (often in shared memory) and so it won't need an additional lower level system cache that wouldn't reduce the amount of I/O but that would only waste ram, memory bandwidth, cpu caches and CPU cycles.
(page 4)
Advantage of self caching
There are many reasons for doing self caching:
- the application can keep the cache in a logical representation rather than in a physical representation because the applications knows the semantics of the data
- when we run low on memory the app may even prefer the logical cache to be swapped out and swapped in later rather than paging in later the on-disk representation of the data
- the applications may use a storage shared across multiple hosts, so it will need to efficiently invalidate and flush the cache in function of a cache coherency protocol implemented in userspace
- the applications knows the semantics of the data so it is will be able to do more advanced cache replacement decisions
- Most of the time those self caching applications are also doing very heavy I/O so they would tend to generate heavy cache pollution
(page 5)
Advantage of O_DIRECT
The usage domain of O_DIRECT are both self caching applications and applications that pollute the cache during their runtime.
With the O_DIRECT patch the kernel will do DMA directly from/to the physical memory pointed by the userspace buffer passed as parameter to the read/write syscalls. So there will be no CPU and mem bandwidth spent in the copies between userspace memory and kernel cache, and there will be no CPU time spent in kernel in the management of the cache (like cache lookups, per-page locks etc..).
(page 6)
O_DIRECT Numbers
I benchmarked the advantage of bypassing the cache on a x86 low end 2-way SMP box, with 128Mbytes of RAM and one IDE disk with a bandwidth of around 15Mbytes/sec, using bonnie on a 400Mbytes file.
- buffered IO
-------Sequential Output-------- ---Sequential Input-- --Random--
-Per Char- --Block--- -Rewrite-- -Per Char- --Block--- --Seeks---
MB K/sec %CPU K/sec %CPU K/sec %CPU K/sec %CPU K/sec %CPU /sec %CPU
400 xxxx xxxx 12999 12.1 5918 10.8 xxxx xxxx 13412 12.1 xxx xxx
400 xxxx xxxx 12960 12.3 5896 11.1 xxxx xxxx 13520 13.3 xxx xxx
- direct IO
-------Sequential Output-------- ---Sequential Input-- --Random--
-Per Char- --Block--- -Rewrite-- -Per Char- --Block--- --Seeks---
MB K/sec %CPU K/sec %CPU K/sec %CPU K/sec %CPU K/sec %CPU /sec %CPU
400 xxxx xxxx 12810 1.8 5855 1.6 xxxx xxxx 13529 1.2 xxx xxx
400 xxxx xxxx 12814 1.8 5866 1.7 xxxx xxxx 13519 1.3 xxx xxx
(page 7)
Comments on the previous numbers
In the environment of the previous benchmark we can basically only see the dramatical reduction of CPU usage, but also the memory usage is certainly being reduced significantly by O_DIRECT.
Note also that O_DIRECT only bypasses the cache for the file data, not for the metadata, so we still take advantage of the cache for the logical to physical lookups.
(page 8)
Low end vs high end storage devices
It's interesting to note that in the previous environment we had a very slow storage device, much much slower than the maximal bandwidth sustained by the cache and cpu of the machine.
In real life the databases are attached to raid arrays that delivers bandwidth of hundred of Mbytes per second.
The faster the disk is and the slower the cpu/memory is, the more O_DIRECT will make a difference in the numbers.
(page 9)
membus/cpu bandwidth bottleneck
With a very fast disk storage the membus and cpu bandwidth will become a serious bottleneck for the range of applications that cannot take advantage of the kernel cache.
For example if you run `hdparm -T /dev/hda' you will see the maximum bandwidth that the buffer cache can sustain on your machine. That can get quite close to the actual bandwidth provided by an high end scsi array. It will range between 100/200 Mbytes/sec on recent machines.
(page 10)
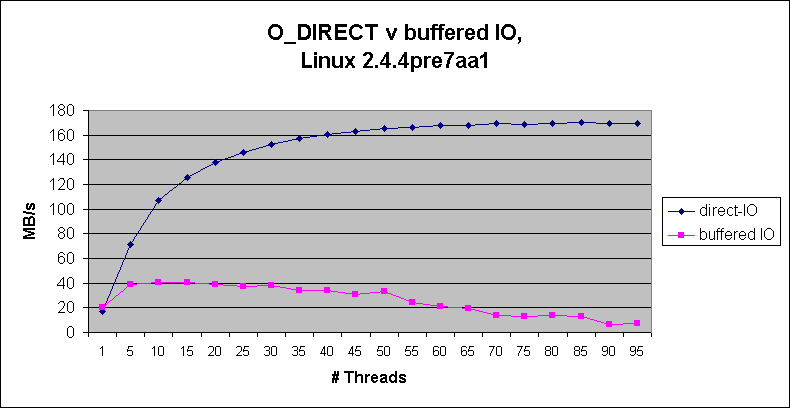
Highend Numbers
The @fast.no folks are using the O_DIRECT patch for their self caching database application and they benchmarked the throughput of their database w/ and w/o using O_DIRECT.
http://boudicca.tux.org/hypermail/linux-kernel/2001week17/1175.html
http://boudicca.tux.org/hypermail/linux-kernel/2001week17/att-1175/01-directio.png
(page 11)
Comments on the highend numbers
The highend numbers were measured using a Dell PowerEdge 4300, dual PIII with 2G of RAM using a megaraid of 4 SCSI disks in raid0 for a total of 140GB.
It's quite clear how much O_DIRECT is faster and more scalable on such an high end hardware for a self caching application like the @fast.no database.
Similar improvements are expectable from applications writing endless streams of multimedia data to disk like digital multitrack video/audio recorder where the kernel cache is absolutely worthless even if it would be of the order of the gigabytes.
(page 12)
Be careful in using O_DIRECT
If the application may want to use O_DIRECT but it is not self caching and you can imagine a setup with enough RAM to cache all the working set of your application then you should at least add a switch to turn off the O_DIRECT behaviour, so if someone has that much memory he will be able to take advantage of it (remember linux runs on the GS 256GByte boxes too ;).
Adding a switch to turn off O_DIRECT can often be a good idea so we can more easily measure how much the buffered IO helps or hurts for a certain workload.
(page 13)
O_DIRECT API
To use O_DIRECT all you need to do is to pass the O_DIRECT flag to the open(2) syscall. That will be enough to tell the kernel that the next read/writes will be direct and they will bypass the cache layer completely.
After opening with O_DIRECT there are two constraints imposed on both the buffer alignment and the size of the buffer. (second and third parameters of read/write syscalls)
The buffer must be softblocksize aligned and the size of the buffer must be a multiple of the softblocksize.
(page 14)
softblocksize vs hardblocksize
The softblocksize is the blocksize of the filesystem (mke2fs -b 4096 for example creates a filesystem with a blocksize of 4096 bytes)
The hardblocksize is instead the minimal blocksize provided by the hardware.
It is possible we reduce the constraint from the softblocksize to the hardblocksize to allow people to decrease the I/O load during non contiguous (aka random) I/O.
(page 15)
Cache coherency
One of the relevant problems of the O_DIRECT support is to maintain some degree of cache coherency between buffered and direct I/O.
- Before any direct IO we need to flush the _dirty_ cache to disk because:
- in case of a direct read we must make sure to read the latest data that was supposed to be on disk
- in case of a direct write we must make sure our next direct writes won't be invalidated later by some older dirty cache that was floating around
- After a direct write we must invalidate the cache to make sure the future buffered reads will see the changes we did on disk.
(page 16)
Cache coherency graphical simulation
Not printable, sorry.
(page 17)
not perfect coherency
During the invalidate after a direct write if the cache is mapped into userspace we will only mark the cache not uptodate, so the next buffered read will refresh the cache contents from disk but the old data will remain mapped into userspace for some time.
Also with concurrent direct and not direct writes going on coherency is not guaranteed.
Doing perfect coherency would be too slow, it would involve putting anchors into the pagecache hashtable and running lookups for every write, plus unmapping all the mapped memory until the direct I/O is complete, but this would slow down the direct I/O common case.
(page 18)
Code
The O_DIRECT patch was developed by SuSE and I expect it to be merged into the mainline kernel tree as worse in the 2.5 timeframe.
You can find the latest o_direct patch against 2.4.6pre2 here:
ftp://ftp.us.kernel.org/pub/linux/kernel/people/andrea/patches/v2.4/2.4.6pre2/o_direct-8














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}