







(和我前一篇文章一样,这篇文章也需要读者动手写些程序,参与其中,实验过程可能需要反复重启电脑,另外最好准备一套英文Windows系统,哦,如果再有一套Windows Vista英文版,那再好不过,总之就是实验环境越丰富越好)
当我写下这个标题的时候,我就觉得我可能错了,但我之前又一直很想写这么一个subject,如今看看,确实有些硬着头皮写的感觉。
这是一个相当大相当大的论题,我不可能在短短的一篇文章里就说得清楚,所以在标题就注明了,这是第一篇,那一共有几篇呢?我也不清楚,因为这个问题我接触了好几年都没完全搞清楚,总是不断有些新的发现,或者说新的心得,也许是因为“国际化”就意味着系统的多样性以及伴随着大量的不确定因素吧。而且,这个问题我觉得很难组织,尽管我酝酿了一段时间了,如何从头到尾讲一次,心里还是没底,如果又是跟那些网上随便搜就能搜到的文章那样,把编码这些乱七八糟的东西重述一通,我想就没这个必要了,应该拒绝这种平庸。
一、普遍的错误认识
“国际化”,你认为是什么?最最常见的回答就是:多语言的翻译。其实多语言翻译只是其中一部分,除了翻译工作,别的工作还有很多很多,如果仅仅是翻译,我想就不需要我们这些开发者参与其中了。所以这是一个表面上看简单,实际上完全不如此的工作。我提几个问题,你来回答一下,就知道这个所谓“国际化”需要涵盖些什么内容了。
1,你一定遇到过乱码,你知道为什么吗?
2,你写的软件界面上的中文在英文系统下可能显示小问号或方框,为什么?而小问号和方框又各代表什么意思?
3,OEM codepage和ANSI codepage是什么?
4,UNICODE编码的一个字占多少字节?(你一定认为你答对了,其实未必)
5,你考虑过你的软件用德文和俄文这种超长鸡肠文显示的效果么?
6,为什么有时候你看到同一字符串里,一部分中文字符能够正确显示,而一部分中文字符显示小问号?
7,IME是什么?什么情况下需要IME?
8,英文系统的速度比中文系统快吗?
……
我不知道再问什么问题好,反正这些东西都很零碎,每个问题都可以写一篇独立的文章,而它们似乎又彼此相关。
我花了将近一年完成了一个软件的设计和编写工作,这个软件是需要跟公司的产品到国外去的,多语言也就成了它所必要的功能,到现在,我回想看看,我有30%以上的时间,都花在解决多语言这个问题上了,但即便到了现在,我还是偶尔能发现其中由于“多语言”而产生的一些bug,这些bug并非都是什么致命bug,但却或多或少影响了使用,比如在某些平台下出现字符串不对齐,字体比较难看等。
当你对这些问题都全部深吾透解之后,我想你一定会对Microsoft敬佩有加的,因为国际化这个问题,确实不容易,很难,不是一般的难,是“要做到完美简直不可能”的难。
而这方面出了问题的话,往往不容易马上被发现,因为你的东西是要拿到许许多多不同的,甚至可能是不正常的系统里使用的,那有个什么现象呢?我想用MSDN上的一句话概括一下:These problems are often overlooked until your customers call to complain.
二、非技术困境
我们软件人通常都比较关心技术,但在转入技术讨论之前,我想稍微提一下非技术方面的难题。下面这个小故事是我从《Windows编程启示录》这本书上看到的。
作者Raymond告诉我们早期Windows设计的时候,在控制面板的区域设置里边有一张世界地图,这张世界地图上是有国界的,你要选择自己的位置的话,只要往这张地图上点击一下你所在的国家的地图,就可以了,这是个很人性化的设计,但很快问题就来了,这个星球总是不太平,而国与国间的领土一直存在着争端,当时这个小地图的国界是把一块印度和巴基斯坦有争端的土地划到巴基斯坦去的,这样就得罪了印度,但很明显也不能把这个土地划到印度去,这样巴基斯坦也会勃然大怒的,解决方法就是放弃这个设计,取消了国界……
类似的问题还有卖到中国大陆的一些软件,在其License里都不得不多注明一下:“下文提到的‘台湾’皆指中华人民共和国台湾省。”否则可能会有麻烦。而卖到台湾去的软件License怎么写,我就无从得知了。
三、最原汁原味的ASCII编码
什么叫“编码”?其实就是数值与字符的对应关系。ASCII是什么?随便网上一搜就一大堆,没错,是American Standard Code for Information Interchange,它是一种编码,而且是一种最基本又普遍的编码,容易混淆的概念还有个ANSI,American National Standards Institute,和ASCII什么关系?简单,ANSI制定了ASCII,制定时间是上个世纪50年代后期,但最后定案是在1967年。ASCII只定义了128个字符。你忍不住笑了:“从50年代末搞到1967年,才搞出了128个字符,老美的IQ真是没话说。”但你要知道一开始往往是最难的,50年代末,什么是计算机,恐怕知道的人还不多,制定一种编码标准,这是多么有前瞻意义的,更何况,我们中国人从来就没有给计算机科学的前进贡献过什么……
ASCII定义的128个字符的编码,不用说你都知道,其数值就是从0到127,其中0-31是不可见字符,又叫控制字符,从32开始,到126,是可见字符,最后一个127是DEL,是一个控制字符。ASCII的影响力无疑是深远的,远到什么地步?现在的Windows系统还支持它,不光现在支持,以后也会继续支持,而且不光Windows,所有操作系统,都支持,过去,现在,未来……现在我们来动手写个小程序,把ASCII的可见字符全部打印出来,这个没问题吧。
这段代码生成一个叫ascii.txt的文本文件,可以直接用记事本打开,上面就是所有可见的ASCII字符了,全世界基本一样。(我用了“基本”一词,就是说还是有不太一样的情况,后面再说了)
那些显示不出来的字符到底是什么呢?我这里列一下,注意看看英文解释,帮助你理解它的英文缩写的来源。中文意思我就不给出来了,鼓励你去查查字典,顺便提高下英文水平。
00 NUL null
01 SOH start of heading
02 STX start of text
03 ETX end of text
04 EOT end of transmission
05 ENQ enquire
06 ACK acknowledge
07 BEL bell
08 BS backspace
09 HT horizontal tab
0A LF line feed
0B VT vertical tab
0C FF form feed
0D CR carriage return
0E SO shift out
0F SI shift in
10 DLE data link escape
11 DC1 device control 1
12 DC2 device control 2
13 DC3 device control 3
14 DC4 device control 4
15 NAK negative acknowledge
16 SYN synchronous idle
17 ETB end of transmission block
18 CAN cancel
19 EM end of medium
1A SUB substitute
1B ESC escape
1C FS file separator
1D GS group separator
1E RS record separator
1F US unit separator
7F DEL delete
四、扩展ASCII编码
老美在制定ASCII的时候,当然不会考虑别人怎么想,因为那时候实在太早,说到计算机技术就是老美一家独大,谁会知道后来计算机技术发展如此迅猛呢?上世纪80年代初,IBM PC的出现,极大地推进了计算机的发展及普及,但对50年代末来说,也是20多年后的事情了。但不管怎么说,128个字符不够用,比如德语,虽然和英语一样同属拉丁语系,但却比英文多出了4个字母,这4个字母并不包含在128个字符中,俄罗斯语,希腊语,阿拉伯语等就更加不用说了,在这128个字符中根本找不到自己的字母。
所幸的是,各国很快地发觉,由于一个字节可容纳256个字符,而ASCII的128个字符仅用了其中的一半,还有一半可用呢,于是就纷纷把本国语言在ASCII中不存在的字母安排到剩下的128个空位(扩展位)中去,这样确实是可行的。但由于各国都我行我素地有自己的一套标准,所以对扩展位的理解,各国都不太相同,一篇用希腊语编码的文章,用俄罗斯语去解码阅读,虽然可能显示的是俄文字母,但意思完全看不明白,乱的,这就是乱码的原因。
那能不能开个国际会议,让各国的编码都统一起来?——不行,因为虽然各国的语言独自放进扩展位是没问题,可一起进就有问题了,这128个位置就不够了。所以各国往后的很长一段时间里,都还是各人自扫门前雪,只有老美悠哉,因为他们得天独厚地占据了前面的128个位置,对美国英语而言,这128个字符足够了。
可最难的问题前面都没有说,那就是这个星球上“字母”最多的3种语言还没考虑进去,那就是——CJK。CJK即中日韩,全因为我们祖先创造的汉字实在太过博大精深,使得中文一度被认为是一种不适合信息化的语言,但这明显是扯蛋,这点难不倒聪明的软件人。一个字节不足以容纳下那么多的汉字,那两个字节,总该可以了吧?根据这个原理,我们国人自创了GB2312编码,GB即拼音的“国标”,非英文也,GB2312是由我国国家标准总局1980年发布,1981年5月1日开始实施的一套国家标准,基本集共收入汉字6763个和非汉字图形字符682个。GB2312在1995年的时候得到了一次扩展,汉字数增加到21003个,包括了我们所能看到的绝大多数的繁体字,甚至一些冷僻字(比如最近流行起来的“囧”字等),符号也增加到了883个,扩展后的GB2312被称为GBK码,(K是拼音“扩展”)当然你还是叫它“GB2312”也可以,或者叫它“GB码”都行,其实指的都是GBK,GBK也是最有影响力的中文编码,中文版的Windows 95就使用了它作为内码,即便到了Windows XP,你用记事本写一篇中文文章,默认的保存编码也是GBK码。关于GBK码,就先讲那么多,后面再详谈。日本也面临着这样的问题,所以他们也创建了自己的编码,叫“Shift-JIS”,和GBK码是不兼容的,台湾香港则是“Big5”码,和GBK码也不兼容,所以我们以前在DOS和Windows95环境下玩一些台湾开发的游戏软件时,总看到乱码。OK,关于汉字编码先暂时开个头,详细后面再提。
我这里有个问题:你认为汉字一共有多少个?小学时候我们学了大约2500个,接下去的日子里陆陆续续又学了1000多个,这就是我们的最常用汉字和次常用汉字,加起来大约3500个,但汉字的总数远远不止这点,1994年出版的《中华字海》就收入了87019个汉字,而已经通过专家鉴定的北京国安咨询设备公司的汉字字库,收入有出处的汉字高达91251个……我相信没有哪个人全部认识这些字。也许细心的你也注意到了,即便是两个字节(理论上最多能表示65536种字符),也不足以容纳所有的汉字字符,这个实在有些出人意料,但现在先不去讨论这个问题。
现在,我们来写一个小程序,打印所有的“扩展位”的字符,把前面的那个小程序稍微改一下就可以了。
现在,我来问一下,生成的这个asciiex.txt到底是什么编码?其实我这个提问本身就是有问题的,什么编码从根本上来说并不是文件本身,而是你用什么编码方式去理解这个文件的文本,前面我也说了,编码其实就是数值与字符的对应关系,用什么编码方式去理解,这是可选的。所以,打印到文件中去的这128个扩展位字符,应该怎么显示,这是不一定的,但现在大家可以尝试看,很简单,同开始一样,直接用记事本打开,你会看到类似下图的显示,但可能你的情况跟我的不尽相同,这取决于你的系统设置以及记事本所采用的字体等因素。
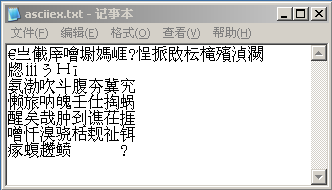
中文居然显示出来了,尽管你一口咬定这是“乱码”,但电脑可不知道什么叫做“乱码”,就算你把一篇你看起来很优美的文章显示出来,电脑也不会认为跟这种“乱码”有什么本质区别——本来就一堆数字而已。这堆数字用不同的编码方式去理解,就有不同的显示,其实就算是ASCII也是这样的,只不过ASCII得到普遍的认同,所以通常都能正常显示而已。
五、OEM code page和ANSICP code page
我相信很多人都用过这两个Windows API:MultiByteToWideChar和WideCharToMultiByte,这两个API用于“宽字符”和“窄字符”之间的转换,它们的第一个参数叫做“CodePage”,你通过查看MSDN,会发现CodePage可以是以下这些:
CP_ACP ANSI code page
CP_MACCP Macintosh code page
CP_OEMCP OEM code page
CP_SYMBOL Windows 2000/XP: Symbol code page (42)
CP_THREAD_ACP Windows 2000/XP: The current thread's ANSI code page
CP_UTF7 Windows 98/Me, Windows NT 4.0 and later: Translate using UTF-7
CP_UTF8 Windows 98/Me, Windows NT 4.0 and later: Translate using UTF-8. When this is set, dwFlags must be zero.
我第一次用这两个函数的时候,也不知道应该选什么参数好,于是到网上去寻找范例,发现范例使用的是CP_ACP这个参数,于是我也用这个参数,当然,用下来没发现什么问题,但如果你想理解这些参数到底什么意义,就得多花些时间了。
在解释前,先说说code page是什么,前面提到了,编码其实就是数值和字符的对应关系,那么这种对应关系是如何实现的呢?如果是我设计,我就会列一张表,通过数值,能查到它对应的字符,反之亦然,这张表就叫做code page,中文叫“代码页”,不同的编码使用不同的代码页,用于数值和字符间的转换。选用不同的参数,告诉MultiByteToWideChar和WideCharToMultiByte使用什么代码页来理解窄字符。代码页都有个ID,比如GBK代码页ID是936。
OK,那ANSI代码页是什么?前面也提到过了,ANSI是个组织,制定了ASCII,然后世界各国各自制定了自己的扩展ASCII,和ASCII兼容,虽然相互间不能正常显示,显示ASCII却没问题,因此,可以把这种跟ASCII相兼容的编码方式归纳叫ANSI编码,而它们的代码页也就称作ANSI代码页了,Windows就这么叫的;那OEM代码页又是什么?搞IT的人对OEM都不会陌生,OEM就是原始设备供应商呗,但这里的OEM代码页指的是硬件上使用的编码,那它跟ASCII有什么不同呢?答案是:可以相同,也可以不同,这取决于硬件商了。事实上,由于ASCII的影响力巨大,绝大多OEM编码跟ASCII是兼容的。如果你还是不太清楚,那就这样说吧:
ANSI是Windows使用的编码,而OEM是硬件及DOS使用的编码。
厄……那么,我们现在Windows上看到的都是ANSI字符,不会看到OEM字符了吧?未必,但通常Windows环境下是不需要显示OEM字符的,你知道OEM字符是怎么样的么?你是不是想回DOS看看原汁原味的OEM字符啊?遗憾的是Windows 2000开始就取消了DOS,你没办法进入DOS了,用虚拟机装个DOS看看如何?可以啊,但你现在找不到DOS或者Windows 98的安装盘了。没关系,其实不用那么麻烦,看看下面这个图。
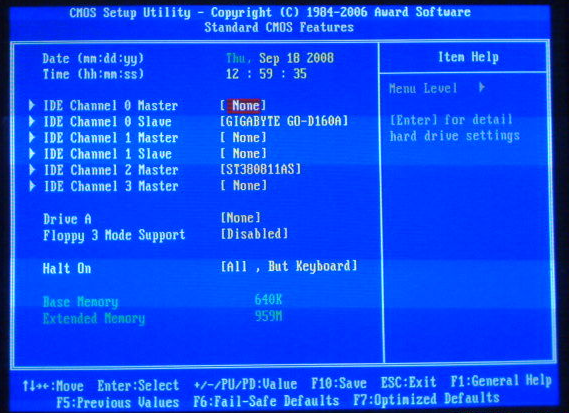
相信大家都很熟悉了,CMOS设置的界面,你能看到的这些字符,就是OEM字符了。注意看啊,上面不是有些线条啊,框框啊什么的么?这些线条框框其实也都是些字符,这些字符在ASCII中是没有的,它们属于扩展ASCII的字符,这么说来,OEM是不是也可以看作ASCII的扩展?通常是可以这样看的,因为那些硬件商通常会考虑跟ASCII兼容。呵呵,我想你大概已经了解了。
那CMOS中显示的是哪一种OEM字符啊?先直接告诉你吧,是美国IBM PC的OEM编码,代码页ID为437,这也是我们见得最多的编码之一。那能不能把这种编码的所有字符都显示出来看看啥样子的?能,而且不需要DOS,Windows就可以了,follow me。
六、在Windows中显示OEM及ANSI字符
要在Windows中正确显示出一个字符,得有两个条件,第一,Windows认识这个字符,知道准备显示什么,第二,要有这个字符的显示字体,只有匹配了正确的显示字体,才会有正确的显示。
尽管大多情况下Windows不需要显示OEM字符,但Windows还是保留了对OEM字符的支持,包括用于显示OEM字符的字体。
最简单的办法就是使用控制台,如下图所示:
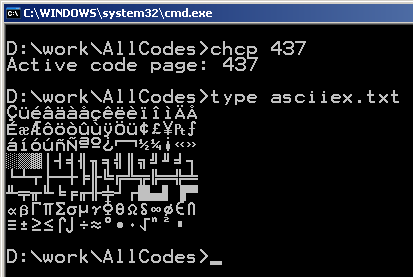
asciiex.txt是前面我们用程序生成的文件,chcp命令是改变当前使用的代码页,如果不先改变代码页,那看到的结果可能就跟我们直接用记事本打开那个程序差不多,一些乱七八糟的“中文”。当然如果你用的是英文系统,那有可能默认的代码页就是437,不需要再改变。
由于Windows是图形操作系统,这些OEM字符虽然可以正常显示,效果跟你在CMOS看到的却不太相同,这取决于你选择的控制台字体,你可以通过调整控制台的字体,观察观察。
顺便,你还可以做些实验,看看使用别的代码页显示这些字符,会有什么不同。比如俄语,代码页是866,或者希腊语737,或者葡萄牙语860……如果你看不出有什么不同,那可能是因为字体的缘故,你可以把控制台的字体先设置为“Lucida Console”。
控制台就有这个好处,可以随意切换代码页,可在非控制台中我就不知道怎么做,查API没查到,如果你知道你就告诉我吧。那没法随意切换代码页,是不是我们的这个asciiex.txt就没法在非控制台程序中正常按照437代码页方式显示了呢?也不是,比较麻烦而已。代码页不能随意换,但还是可以换的,打开控制面板,双击“区域和语言选项”,点到“高级”标签页,然后选择“英语(美国)”,如下图所示。
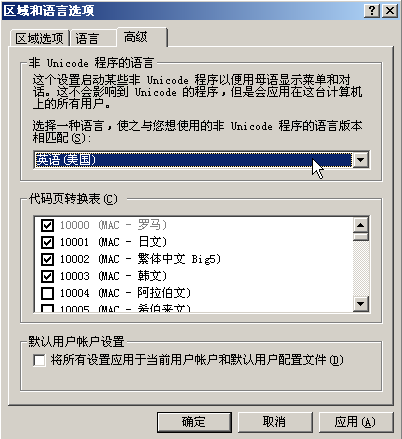
当你点“确定”之后,系统提示你放入Windows安装盘,完后还要重启才能生效,这就是我所说的麻烦。当然了,这个改动是需要管理员权限的。
重启后,你会发现系统字体看起来有些怪,反正就是跟本来的中文字体不太一样,因为系统默认字体发生了些变化,很多窗口的文字不是我们所熟悉的宋体字了。用记事本打开asciiex.txt这个文件,嗯?好像显示不太正常?不是预想的那样。没关系,这是字体的问题,我经过测试,发现把字体设置为Terminal就能有比较好的显示了。
再问个莫名其妙的问题哦:刚刚你也发现了,换不同的字体,asciiex.txt就有截然不同的显示,到底它应该显示什么呢?呵呵,这个问题有点扯了,像脑筋急转弯,其实答案前面已经给出,这个asciiex.txt是我们编程序按数值大小顺序写出来的一组数字,我也不知道它应该怎么显示,你认为它是英文它就是英文,认为它是中文它就是中文。看过王爽写的《汇编语言》这本书么?作者怎么说的?哪里算是程序,哪里算是数据?这是你说了算的,你让指令指针指向它,它就是程序,你把它当作数据访问,它就是数据。当然如果你让指令指针乱指,那程序也是乱套的,就好像你看到的那些“中文”乱码一样。
那asciiex.txt按照OEM代码页437显示的效果大家也都看到了,那能不能让它按照ANSI代码页1252(这个代码页名称是Latin-1,许多西欧语言都采用它,包括美国英语)来显示?由于是直接显示,中间没有转换过程,其实就是更换下字体,通过实验,我发现Fixedsys字体正好合适,你把记事本的字体设置为Fixedsys即可。这个时候你会发现很多小黑框,这是找不到合适的字符来显示所采用的“代字符”,小黑框是默认的代字符,但代字符不一定都是小黑框,你也可以改的,之后我会讲。这时候你要问了:你怎么知道使用Fixedsys字体显示的就是ANSI代码页1252的字符?这个……我当然是有根据的,但得麻烦你自己写写程序验证了。
程序不难,一个MFC Dialog程序足够,在上面摆两个Edit,绑定两个CEdit对象,就叫m_edit1和m_edit2吧,然后在OnInitDialog中,加入以下代码:
完之后把asciiex.txt的内容load进来,然后用SetWindowTextA把这些内容作为这个两Edit的内容。
关于GetStockObject(OEM_FIXED_FONT)和GetStockObject(SYSTEM_FIXED_FONT),查一下MSDN,就大概知道意思了,选中我们要使用的字体,一种等宽OEM字体,一种等宽系统默认字体,这样显示出来的字符就正好是OEM-437字符和ANSI-1252字符,当然了,如果控制面板中选择的非Unicode编码类型(就是前面提到的那个需要放入光盘重启电脑的设置)不是“英语(美国)”,而是别的的话,就有可能不这么显示,因为用的code page不同。哦?Unicode编码?我暂时不说。
如何知道code page?有两个API可用,一个是GetACP,另一个是GetOEMCP,要知道当前用的是什么code page,用这个代码就可以了:
每种语言都有自己对应的ANSI编码和OEM编码,有了这段代码,你就可以到不同的环境下验证一下,系统到底用的是什么code page,你到简体中文Windows下看看,你会发现ANSI code page和OEM code page都是936,即GBK,而日文的话则都是932(Shift-JIS),俄文则不同,ANSI code page和OEM code page分别是1251(西里尔文)和866(OEM俄文)。别的嘛,自己多试试看。
嗯?这里还有个LCID,这是什么玩意儿?请听下回分解,嘿嘿。(BTW:文章远远没结束啊,要知道“国际化”就是国际难题)最后奉上一张本人精心整理的ASCIIEX全图。















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









