







声明:
1)该博文是Google专家所无私奉献的论文资料整理的。具体引用的资料请看参考文献。具体的版本声明也参考原文献
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应,更有些部分本来就是直接从其他博客复制过来的。如果某部分不小心侵犯了大家的利益,还望海涵,并联系老衲删除或修改,直到相关人士满意为止。
3)本人才疏学浅,整理总结的时候难免出错,还望各位前辈不吝指正,谢谢。
4)阅读本文需要机器学习、优化算法等等基础(如果没有也没关系了,没有就看看,当做跟同学们吹牛的本钱)。
5)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。请直接回帖,本人来想办法处理。
6)本人手上有word版的和pdf版的,有必要的话可以上传到csdn供各位下载,地址:http://download.csdn.net/detail/mytestmy/7973463
优化算法中的LBFGS解法以及GD等解法,是对一批样本进行一次求解,得到一个全局最优解。
实际的互联网广告应用需要的是快速地进行model的更新。为了保证快速的更新,训练样本是一条一条地过来的,每来一个样本,model的参数对这个样本进行一次迭代,从而保证了model的及时更新,这种方法叫做OGD(Online gradient descent)。
当然这会有误差,所以为了避免这种误差,又为了增加稀疏性,有人又想到了多个版本的算法,Google有人总结了其中几种比较优秀的,如FOBOS,AOGD和微软的RDA,同时提出了Google自己的算法FTRL-Proximal。FTRL-Proximal在各个方面如稀疏性,ctr等方面表现都比较好。
在应用的时候,线上来的每一个广告请求,都提取出相应的特征,再根据model的参数,计算一个点击某广告的概率。在线学习的任务就是学习model的参数。
所谓的model的参数,其实可以认为是下面的(1)作为目标的函数的解。跟之前说的根据批量的样本计算一个全局最优解的方法的不同是,解这个问题只能扫描一次样本,而且样本是一条一条地过来的。
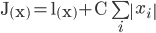
其中的l(x)是逻辑回归的似然函数的负对数,右边第二项是L1正则项,具体情况可以参看博文《从广义线性模型到逻辑回归》。
对于上面的优化问题,可以在已有L1正则的基础上,再加L2正则来防止过拟合。
1.1 FTRL-Proximal算法
下面介绍这个算法。令给定model参数x,和第t个样本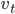
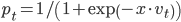
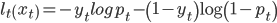
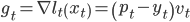
其中model参数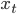
原始的OGD使用下面的迭代公式
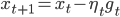
其中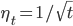
这种迭代方式够简单,但不够好,也不产生稀疏解。
FTRL-Proximal算法把OGD的迭代方式变成一个优化问题。
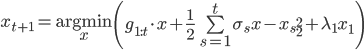
其中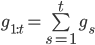
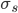
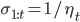
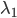
上面的右边括号里面的几项都有各自的意义,第一项是对损失函数的贡献的一个估计,第二项是控制x(也就是model)在每次迭代中变化不要太大,第三项代表L1正则。
这个优化问题看起来比较难解,因为看起来要存储迭代过程产生过的所有model参数。实际上,经过巧妙的处理,只要为model参数x的每个系数存一个数就可以了。
上面的问题的最小化的部分可以重写为下面的形式
所以,只要存储一个向量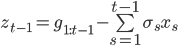
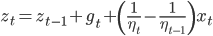
就能得到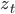
只要让上面的优化问题(5)的次梯度为0,就能得到问题的解。从而可以得到上述问题的每一个维度(每一个特征的权重)的一个闭式的迭代公式。
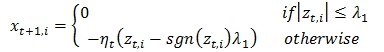
对于上面的迭代式,如果
对于步长学习率方面,FTRL-Proximal算法还做了改进,让每一个特征的学习率都不一样。每次每个特征的学习率也用下面的公式计算。
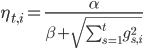
其中α根据数据和特征自适应调整,β一般取值为1。
同时,优化问题(5)还可以加上惩罚系数为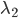
经过上面的讨论,可以得到FTRL-Proximal算法的流程。

致谢
Google的多位科学家,无私地公布他们的成果。
参考文献
[1] Follow-the-regularized-leader and mirror descent: Equivalence theorems and L1 regularization. In AISTATS, 2011.H. B. McMahan.
[2] Ad Click Prediction: a View from the Trenches.H. Brendan McMahan, Gary Holt, D. Sculley et al.














 2359
2359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









