







和过去写的《 融入了外部Linguistically信息的情感分析模型》博客提到的基本原理一样,今天要介绍的模型在进行情感分析的时候同样不仅仅只考虑单条的文本信息,也引入了外部的信息,只不过这个信息不再是Linguistically,而是context的。这篇博客参考了论文《Modeling Rich Contexts for Sentiment Classification with LSTM》。
首先,论文里提出了一个“tweets thread”的概念,那么什么叫做“tweets thread”呢?这个“tweets thread”由三个部分组成:1 原创的微博 2 评论微博 3 转发微博。论文里的观点认为,在分析一个单条微博的情感的时候,参考和其在同一个“tweets thread”中的其他微博是有意义的,因为在同一个“tweets thread”中的微博会更加趋向于拥有相同的情感倾向。(PS:我感觉这个假设有点靠不住,转发的话可能还会代表认同;是评论的话,很多人都是批判的,情感极性是完全相反的,这里可能还需要甄别一下才行)。基于此,论文中提出了一个具有双层次结构的LSTM,如下所示:
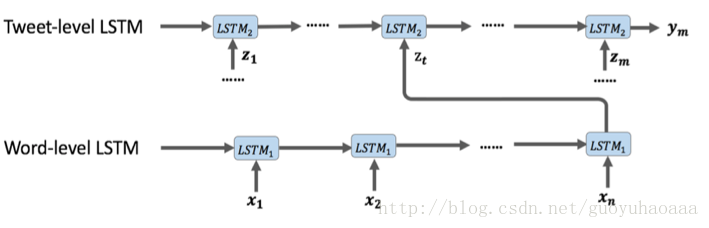
图中“word-level”LSTM就是负责把一句话encode成一个句向量(取LSTM最后的输出向量作为整个句子代表),至于上面那个所谓“Tweets-level LSTM”就是在分析一个句子的时候,只有最后一个时刻的输入即图中的
Zm
是当前要分析的句子,而其他前面的所有输入向量都是和要分析的句子在同一个”tweet thread”中的句子。其实这里要说明的是,一个“tweets thread”其实就对应了一个树结构,树的跟节点就是原创的微博,而它的第一层孩子就是直接转发或者评论其的微博,而下面层次的孙子节点分别是转发或者评论了他们对应的parent节点的微博内容。故针对树中的任意一个节点,都有一条唯一的从根节点到其的通路,这条路径上的微博就对应了图中的
Z1
到
Zt
。
同时为了进一步考虑额外的信息,作者在输入中增加了一些别的的因素,这些因素以二进制编码向量的形式和之前的每一个
Zi
进行拼接,然后作为”Tweets-level LSTM”的每一时刻的输入,这些因素如下:
(注:每一种因素都对应着2位二进制的编码,即编码了当前要分析微博和其root节点及parent节点对应微博信息是否匹配)
SameAuthor
判断当前微博用户和其parent及root节点对应微博的用户是否为同一个人(是的话就是1,不是的话就是0)
Conversation
判断当前用户是否被其parent及root节点对应微博的用户@过
SameEmoji
判断当前微博和其parent及root节点对应微博是否使用过同样的表情符号
SameHashtag
判断当前微博和其parent及root节点对应微博是否使用拥有相同的主题
这篇论文的很多观点其实都有问题,比如他假设属于同一”tweet thread”中的微博拥有相似的感情倾向(这显然就是不合理的)。但是他给我带来最大的启发就是他分析问题时候的角度:从真正的应用场景出发,结合实际的应用,提出一个针对该场景的解决方案。不再是纯粹的搞脱离实际场景的算法研究。主要是单条文本的分析模型基本已经被研究的差不多了,而我最近看的最新的论文在基础的模型之上已经没有什么改进了,他们无非就是结合了一个特定的场景而T提出针对该场景的创新方案。也许我们以后的科研计划要向这个方向转移了。














 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









