






设想今天是个愉快的周末,天气很好,你带着孩子在公园闲逛,这时候,一条短信来了:
瞬间整个人都不好了,到底怎么回事,上面的业务有没有预警,赶紧把相关人召集一下,最好赶紧去下公司吧!也许这时候你会想:能不能有些智能监控手段,给我看到我最想要的信息,这种模棱两可的信息,只会让人心情变差。
回到主题,现在只要说微服务,必须先说单块应用了,那单块应用架构下,监控都怎么做呢?这是一个非0即1的问题,如果宿主服务器指标一切正常,那就是单块应用出问题了。对于宿主服务器的监控技术也算蛮成熟,比如Nagios、Zabbix;而对于应用的监控,主要通过应用服务器的管理平台,或者直接上去拿应用日志就可以了。
随着微服务越来越多的被采用,以前是单个服务器+单个服务,现在转变成是多个服务器+多个服务的模式了,出现一个异常,如何快速找出问题根源,显然对监控能力的要求更高了:
- 分散在各处的日志怎么办?
- 是某个宿主服务器的问题?还是某个服务的问题?
- 无论是服务还是服务器问题,影响链有哪些?
- ......
当然,前面一直在拿故障定位举例,但监控可不是只为了故障定位,一般监控目标无非下面几种:
- 事故预警:比如基于阀值对比的实时的事件告警等
- 故障定位:比如静态点的异常日志收集等
- 优化决策:比如用户行为数据分析,发现瓶颈等
无论是上述的哪个目标,又或是微服务带来的诸多难点,有一样东西是一直没有变的,那就是来源,要么是落地日志、要么硬件设备或系统信息、要么就是一堆自定义的程序埋点(当然也可以把日志作为埋点的一种实现方式)。只是在微服务架构下,信息收集后你需要的处理动作(关联、合并、过滤、去重等等)更多更复杂了,我们可以想想一些实际的应用场景:
1. 微服务的日志收集场景,假设现在我是一个平台的运维人员,我肯定不希望登到每台宿主服务器上去看各种日志,最好是把日志都收集到一起展现,然后做后续的分析挖掘,基本流程如下图所示:
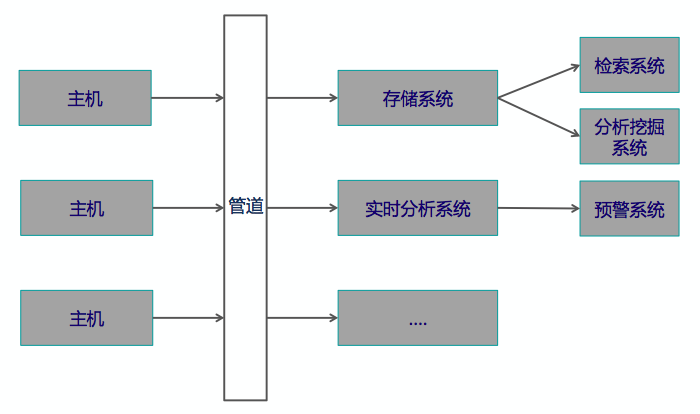
从左至右,先是从宿主服务器上去收日志,紧接着是一个管道,负责数据传输,接着数据被分流,部分进了存储系统,比如ElasticSearch、Hadoop,部分进了实时系统,比如storm、esper,再往右就很明了了。这个架构已经被很多的互联网公司应用,我所知道的淘宝、当当、美团等都是这个基础架构。但这个架构设计中有几个点值得大家关注:
- 管道除了传输,还有很多能力,最常用的是简单预处理和数据缓冲(比如很多架构里用到了kafka)
- 传输可以是多级,一般来说规模大到一定程度,数据往一个点的海量汇聚很容易出问题,分级处理是个很好的方式
- 日志收集方式尽量统一,很多设计里对于业务日志、容器日志(如docker)、宿主机日志等采用不同agent,这是一个不好的设计方式,agent也要管理,引入太多agent只会给自己增加不必要的麻烦
2. 行为数据分析场景,很多创业公司都在关注这块,一个常用的方式就是基于埋点,一般埋点可分为前端(终端)和服务端两种,两者各有利弊:比如前端的好处在于可获取更丰富的界面操作信息,从而指导界面UI(如布局)的演进,而其最大的问题在于采集数据的传输对网络要求较高(一般采用批量方式)。微服务架构下,基于埋点的被统计进程变得越来越多,比如服务健康检查这类,既要有点,又要有链。埋点的设计里有几点经验供大家参考:
- 都可以做到的前提下,后端采集是首选
- 前端采集尽量采用框架进行埋点,不要到处插入自定义代码(框架的做法其实不复杂,比如web端,用过类似selenium这些框架自然就清楚原理了)
- 埋点很难做到语言无关性,尤其后端埋点,微服务架构下,尽量结合各微服务语言特征来实现
3. 系统性能跟踪场景,这个其实倒和传统架构下的方案类似,比如通过协议采集系统的CPU、内存、磁盘IO等,进而分主题入指标库。不过像我们采用容器来承载微服务的做法,比起传统架构来说,需要采的系统信息更多了,比如容器的性能信息,同时在创建性能相关的主题时,数据的关联性也显然更复杂了。同样有些经验大家可参考:
- 指标库的选型一般会采用一些内存计算框架,对于主题的设计和优化要充分考虑内存容量
- 无论容器、虚机、物理机,性能数据采集都面临着窗口的问题,一般是两个窗口(多长时间采集一次和采集的数据是多长时间的数据平均值),需结合业务设置合理值
- 还有一点,包括上述的两个场景也都要注意,就是采集器本身对宿主机的性能影响,需尽量降到最低
前面从技术或业务架构上谈监控,除此之外,微服务架构下,在做监控设计时,还有一项重要因素:人(PS:我不是要说康威定律),前面有一句话,不知道大家有没有在意,“给我看到我最想要的信息”,“我”很重要,我可以是很多角色,即使是同一个微服务,不同的角色对于想看到的信息都可能是不一样的,结合角色考虑,往往在微服务架构中可以给我们的设计留有很大优化空间,举个例子:
我们曾经在一个项目中采集性能信息,后端的指标库用了influxDB,存储虚拟机的各性能数据,每次采集信息作为某时间点的一条完整记录(默认是1分钟采集一次),中间架了缓冲(kafka),然后由处理器订阅,并对一批数据向InfluxDB做批量插入,示意图如下:
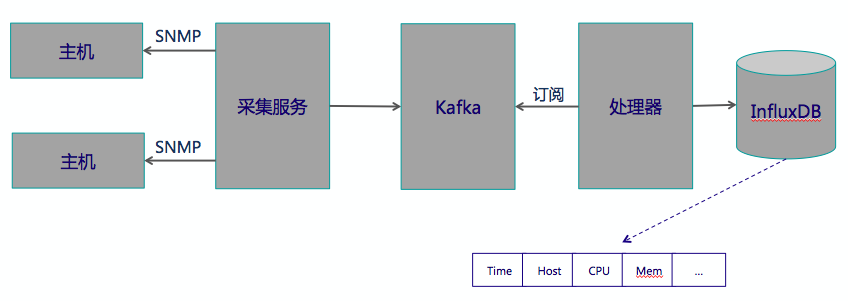
我们一开始认为这就可以了,后面基于类sql语句和内置函数完全就可以得到想要的信息了。比如每天的性能曲线,可以将一天的数据通过mean计算出24个点,而每个月的时间曲线,可以将一个月的数据计算出30个点。我们就这么傻呵呵的把数据持续积累着(要求半年),直到一段时间后,发现撑不住了,怎么办呢?我们回过头来,看看实际上不同的角色要什么信息?他们是怎么消费数据的?
- 决策者:最关注的是这周或这个月比前段周期负载增加或降低了多少,给他的只需是个数字对比结果,明细数据根本不重要,最多他希望能对比到半年前即可
- 运维人员:运维人员其实对数据实时性要求很高,他们根本不在乎几个月前的数据,只要能看到最近时间的数据有没有问题即可
这么一考虑,那优化方式其实就很多,详细数据虽然需要存档,但完全可不放在时序库中,针对决策者,数据按每周或每月汇总再存入线性指标库即可(influxdb continuous queries);而针对运维人员,数据驻留内存周期可大幅缩短。
总的来说,在微服务架构下,监控确实变得越来越复杂,但无论怎么复杂,我们都时刻需要结合业务需要和角色识别,来进行监控方案的设计与优化。
最后给大家分享下我们目前平台中使用的一些技术栈:
- 日志收集的需求,因为我们是基于容器技术的,使用的CoreOS系统,最终我们采用了Journald+Fluentd+ElasticSearch的技术(业务日志亦是如此),简单场景下,ELK、Flume等其实就足够了,我们在一些小项目中实践过。而实时分析系统部分,大家可选择akka、或者esper、或者storm作为实现框架,akka通过actor模型实现信息流转,esper我们是用来做CEP产品的,storm就不用多说了。
- 对于埋点的一些需求,大家可参考java的Metrics项目,或者Netflix的Suro项目,都是java实现,前者简单,后者则考虑更周全。
- 对于性能指标的一些需求,influxdb可作为后端存储(不过influxdb的版本间兼容性做的很一般),大家尽可能使用最新版本,还有opentsdb,有朋友推荐过,不过毕竟是基于HBase的,比较重,大家有兴趣可尝试。














 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









