









前言
紧急添加:有人反馈看不懂。那是因为没有看姐妹篇,《你有没有想到,这样的观点挖掘引擎?》。请先阅读本文,再继续看下去!
做了一段时间的OCR,把大量的图片、PDF处理成了文本。请注意:这些文本在互联网上属于稀有资源。这些文本以前都放在一个盒子里,如今,用OCR做钥匙打开盒子。取出东西,是好是坏也没人知道。但是,总得取出来看看。
所以,Text Mining就有了用处。我们把这些稀缺数据拿来挖一挖。万一挖到宝了,可就发了。。。
数据可视化后,你将得到这样的结果:
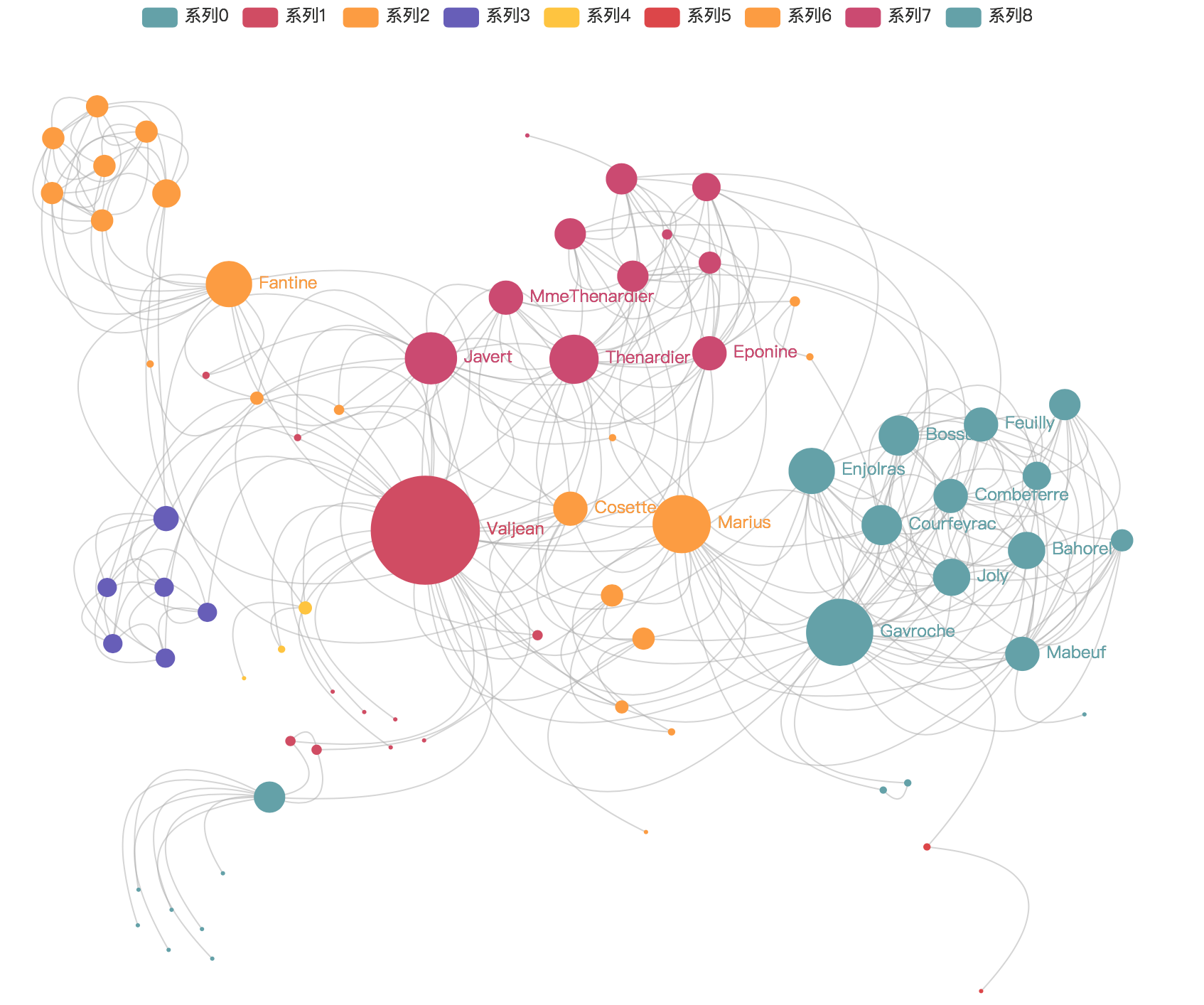
别高兴,我将给你列出一堆坑。。。。
在自己的微信公众号上,写过一篇文章—-《你有没有想到,这样的观点挖掘引擎?》。这篇文章主要是对观点挖掘引擎做了简单的概述,给出了每个步骤大致需要实现怎样的功能。但是,没有涉及到技术和框架的东西。所以特地在CSDN上讲讲技术层面的东西。
OCR处理图片
这是一个很重要的过程—-数据预处理,直接影响最后的挖掘结果。难点有两个:
- 图片的布局、PDF文件的版面识别
- OCR识别的精度,一般都会有错误字符出现
不要妄想自己能解决这两个问题,请交给专业人士去搞,因为比较头疼。但是对于一般的开发者而言,或者精度要求不那么高的同学而言,直接用OCR的成熟东西就好,比如Tesseract。
给出一篇文章:《OCR—-Python调用Tesseract引擎(Ubuntu下)》。参照来做,没有问题的。
文本挖掘工具
自己写算法去挖掘处理好的文本,简直可笑。。。因为水很深很深。主要的难点:
- 文本挖掘常用算法自己手写,耗时
- 语料库(特别是中文)
- 句法分析、语义分析
所以,对于一般的开发者而言,或者公司快速生成而言,用框架吧。推荐两款:(1)结巴分词,(2)清华大学的中文分词THUTag。
我使用的是jieba,感觉API讲解的好。
操作指南就不秀了,也没什么可写的。当你装完环境,可能只是这样:
# abstract word extract
tags_output = jieba.analyse.extract_tags(text,topK=20,withWeight = True)对,我并没有开玩笑。。。only one code !
数据可视化
数据可视化,这是个可深可浅的活。有时候,谁都能干;有时候,需要深知业务逻辑的人才。吓得我都不敢多说一句了。。。
这块也是现在比较火的BI工程师的职业范畴。BI Engineers用什么,我不知道。但是,我用的可视化工具是Echart,百度开源的(PS:支持国产的好处就是API都是中文的哎。。。)。
Echart3和Echart2整体的功能没有多少改变,但是样式和风格变了很多。抛开版本不说,EChart框架貌似不太适合含有逻辑关系数据的展现 。做分类结果展示还可以,但是关系图,我只能呵呵。
最近,在尝试D3的技术,有空再码。
结语
关键词提取也好,观点挖掘也好,都没有本质的区别。我做的这个东东,主要是在数据结构上用创新。毕竟是图片、PDF,不是纯文本。
更多技术交流,欢迎评论。毕竟在技术方面还是个渣渣,所以有不对的地方,欢迎批评指正。感谢!
下面是公众号的二维码,扫一扫关注更多精彩原创内容:















 2353
2353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









