







前言
本篇承袭之前的系列文章,开始动真格。以赶集网招聘类信息爬取为例,详细解说爬虫程序构建过程。
准备工作:
OK,let’s go!
构建URL库
每个网站的URL都会有一定规律,或强或弱。赶集网的URL规律就非常明显。
郑重说明:对于目标站点,必须熟悉。这一步对于不同的网站有不同的方法。而赶集的话,是我通过仔细观察得到url规律。以赶集招聘类目举例,如下:
- http://www.ganji.com/index.htm 页面包含了所有的城市,每个城市有固定的简称,如:上海是sh,北京是bj
- 每个城市的招聘类目网址均带有zhaoping,如:上海是http://sh.ganji.com/zhaopin/,北京是http://bj.ganji.com/zhaopin/
- 每个城市的职业分类均是相同的,具体的职业分类标识均是相同的,如:电话销售是zpdianhuaxiaoshou,售前工程师是zpsqgongchengshi。相应的该类目下的链接是(已北京为例):http://bj.ganji.com/zpdianhuaxiaoshou/,http://bj.ganji.com/zpsqgongchengshi/
- 有了city+category的URL以后,可以在URL后追加页数,如北京的电话销售第一页:http://bj.ganji.com/zpdianhuaxiaoshou/o1/ ,第二页:http://bj.ganji.com/zpdianhuaxiaoshou/o2/
URL规律就说到这里。顺便一提,赶集网的3G手机版的也是相似的规律。
说说几个误区:
-
担心漏爬。因为分类信息网站的分类还有很多,刚才我分析的太简单了?
负责的告诉大家,以上的分类完全不用管,不必去构造区域(海淀、朝阳、东城等)、月薪、福利、其他的URL规律。例如只要选了电话销售,这些信息均包含在此链接下。更多的筛选条件只是决定了哪些信息可以优先显示罢了,对于全部需要(如果你不需要全部,当我没说)爬取的爬虫是没有意义的。 -
所有的数据都应该遵循自动获取(除了第一个url是手动输入),而非人工录入。比如,城市类目。虽然,城市类目一般不会变,但是如果赶集增加和放弃某个/些城市了,爬虫就完了。
-
没有固定的和绝对的规则/规律,一定要保持爬虫的灵活。不要以为总结了很多赶集的规律,就算结束了。实时盯着自己的爬虫。比如,城市类目里:
最后一行,居然有钓鱼岛!我只能告诉你,这个城市链接下的数据和其他所有城市都不一样。你的爬虫里的正则、xpath、爬取方式在钓鱼岛下均不适用。但是,你一定要知道:钓鱼岛是中国的!

去重模块
去重去的好,可以节省很多的时间。但是在不同的应用场景里是有很多差异之处。切记套模板,必须自己去思考。
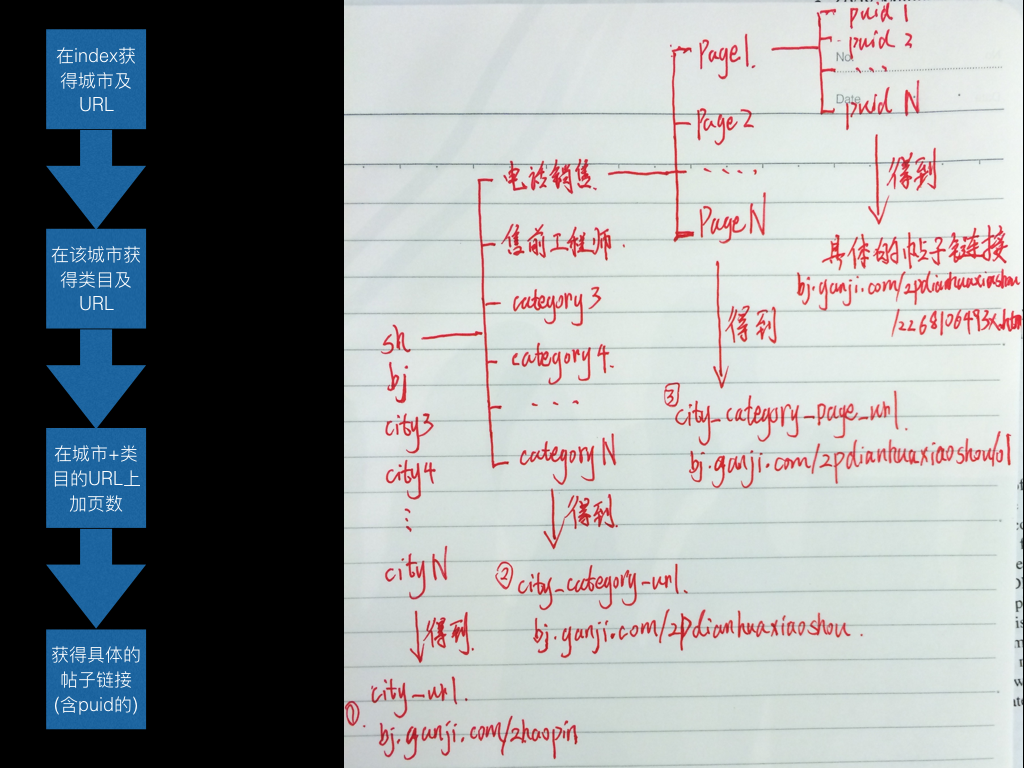
在赶集网的爬取过程中,因为需求是:爬到更多的新数据。而这样必然产生大量的数据。所以,我没有采用每个具体页面的id去重(去重速度慢。一般的应用场景应当考虑利用id),而是判断listing页面(一般包含30个具体页面的摘要信息)是否已爬过。
所以,构建了一个去重的数据库。表结构:

把每次爬到的URL都放在mongo里,设置如下几个字段:
- _id:等同于cityCategoryPageUrl字段
- cityCategoryPageUrl: 城市+类目+页数的URL
- cityCategoryUrl: 城市+类目的URL
- status: 该cityCategoryPageUrl是否已爬过。0:未爬过,1:已爬
- endPage: 该cityCategoryUrl是否已爬完。0:为爬完,1:已爬
- crawlTime:插入数据库的时间
- crawlDay: 插入数据库的日期
OK,写到这里,声明下:我是按cityCategoryPageUrl这个字段的值来爬数据的。这个字段的状态是0就去爬取该页面,否则放弃。
那endPage是干什么用的?
因为每次中断后,就不知道该是从那个页面开始了。不想每个页面都检查一遍是否是已爬过(status == 1)状态。所以先检查cityCategoryUrl是否是已爬过。
梳理一下:
最后,再次强调:去重模块的数据表中,没有具体帖子的URL状态。因为,数据太多了,每次都检查不过来。而且帖子都在新增和删除(用户行为),是变动的数据。
爬取模块
既然URL已经构建好了,爬取就变得简单了。利用requests模块库发送HTTP请求,得到网站源码,利用lxml模块库进行DOM化,结合xpath爬取即可。中间的个别技术问题,一样网络均有答案,不再赘述。
给出一份Python版伪代码,仅供参考:
def proxy():
"""购买代理IP"""
proxies = 购买代理IP
return proxies
def check_fanpa(response):
"""检测反爬虫页面"""
title = 检测网页内容,如判断title内容
if "404" in title:
check_result = False
elif "502" in title:
check_result = False
elif "反爬取" in title:
check_result = False
else:
check_result = True
return check_result
def request(url):
"""发送HTTP请求,获得源码"""
hea={常用的http头}
proxies = proxy() # 调用,获取代理IP
response = requests.get(url,proxies=proxies,headers=hea,timeout=1)
check_fanpa_result = check_fanpa(response) # 调用,获取反爬虫检测结果
if check_fanpa_result is False:
再次尝试http请求,这里可以有一个请求限制,最多/少10次
else:
return response # 返回正常结果
return None # 超出了请求限制的特殊情况
def check_quchong(url):
"""url去重"""
quchong_result = 在已爬过的数据中寻找是否有相同的url
if quchong_result is not None:
return False # 重复的URL
else:
return True # 没有该URL
def parse(response):
xpath_map = {
"title_xpath": "//html/header/title/text()" ,
"...": "...",
"...": "...",
}
tree = lxml.etree.HTML(response.text)
title_data = tree.xpath(xpath_map['title_xpath'])
data = {}
data['title'] = title_data[0]
return data # 返回所用数据
def storage(data):
"""数据存储,细节过程就不说了"""
将data放在mongo中
return True
def crawl():
"""爬取模块"""
url = 从构建的url库中获取
check_quchong_result = check_quchong(url) # 调用,检测是否已经爬过
if check_quchong_result is True:
return None
else:
response = request(url) # 调用,获得源码/None
if response is None:
return None # 因为是异常,返回None,当然也可用pass让程序忽略继续向下走
parse_data = parse(response) # 调用,获得解析好的data
storage_res = storage(parse_data) # 调用,存储数据
实际上,以上代码只是展示了基本的爬虫逻辑。实际应用中,完全不能这么写。上面的伪代码连最基本的异步都没有做的,所以就看看逻辑就好。一般的爬虫,和上面的爬取逻辑并无二致。
代理模块
在上述爬取过程中,大量快速的访问,将触犯赶集的反爬取机制,HTTP请求后的response都是不包含可用信息的源码。这些页面的种类有很多,如:反爬页面,404页面,403页面,502页面等等。我在自己的github上共享过相关的资料,仅供参考,请戳传送门----赶集反爬。后期,会有一篇文章展开讲反爬的故事。
面对众多的不可用页面的情况,最好的办法就是使用代理IP。在使用代理的过程中,也必须验证返回的源码是否是自己真正需要的,不是,就必须换一个代理IP,重新去请求。有些场景,需要不断换代理IP,直到获得真正的页面源码;有些场景,设置请求次数,如10次,换10个不同的代理IP之后,如果拿到的还不是自己需要的源码,就放弃该页面。
存储模块
要存的数据大致有两种:
- 临时存储的数据
- 永久存储的数据
临时存储的数据,放在redis中;永久存储的数据,放在mongo中。根据应用场景,灵活的配合使用。
redis可以存放http请求后的源码。将网页源码序列化后,存放在redis队列中,再利用其它进程,如解析进程,进行解析。得到的数据如果是永久数据,可以直接存放到mongo中。如果还有需求方需要,可以再次放在redis中,让该需求方去拿即可。
构建异步程序过程中,使用redis有两种基本的方法:
- 生产者–消费者模式
- 发布者–订阅者模式
两者区别较大,设计redis队列需要考虑。相关资料参考博文:【Redis----异步程序之消息队列的应用与实践】。
mongo用于存放永久数据,比较简单方便。保证插入时不出错,是爬虫程序中最常见的需求。可以在插入数据出错后,检测一下是否有相同的key。视情况,放弃该数据,或者更新该数据。
结语
写的越多,发现想说的越多。其中细节,怎么说也说不完。所以,任何问题,欢迎留言交流。_
文章同步更新在简书、稀土掘金、知乎、CSDN博客、微信公众号上,个人原创,尊重版权,转载请声明!
更多精彩内容,可以关注微信公众账号【谷震平的专栏】获取。
欢迎加入星球~
















 5631
5631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









