









1、集群环境
hadoop2.5+hbase1.1.2
集群现在有37台slave节点,一个master节点。
2、数据源
每一天的数据压缩成了一个tar.gz包,大概4G,其中大概有6000个zip包,每个zip包中有几个txt文件。
现在采用shell脚本将每天的数据合并成一个txt,大概有几十G。
3、插入要求
现在要将txt文件中的每一行作为一条记录插入hbase。
4、建表
create ‘terminal_data_file’,’cf’,{NUMREGIONS=>37,SPLITALGO=>’HexStringSplit’}
这里在建表时就采用了散列化,在集群上建了37个regions,防止插入时产生热点效应。表建好之后,用浏览器打开hbase的管理页面,可以看到我们新建的表是有37个online regions的。但是,一旦你在shell中使用truncate ‘tablename’之后,这个表的online regions就变成一个了,也就不具备散列化的特性了。这一点要注意。
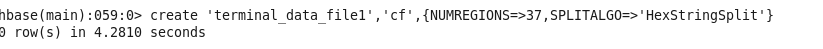
5、代码
代码类似于wordcount,输入目录是hdfs上一个含有多个txt文件的文件夹。直接再map中将数据插入hbase,所以我们不需要reduce。
启动函数:
public class TextInsert4 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = HBaseConfiguration.create();
conf.addResource(new Path("/usr/local/cluster/hadoop/etc/hadoop/core-site.xml"));
conf.addResource(new Path("/usr/local/cluster/hadoop/etc/hadoop/hdfs-site.xml"));
conf.addResource(new Path("/usr/local/cluster/hadoop/etc/hadoop/mapred-site.xml"));
if(args.length !=1){
System.out.println("1 args");
System.exit(2);
}
// Job job = new Job(conf,"wordcount");
Job job = Job.getInstance(conf);
job.setJobName("insert_hbase");
job.setJarByClass(TextInsert4.class);
job.setMapperClass(TokenizerMapper.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
job.setOutputFormatClass(MultiTableOutputFormat.class);
TableMapReduceUtil.addDependencyJars(job);
TableMapReduceUtil.addDependencyJars(job.getConfiguration());
// job.setReducerClass(IntSumReducer.class);
// job.setOutputKeyClass(Text.class);
// job.setOutputValueClass(IntWritable.class);
// FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setNumReduceTasks(0);
System.exit(job.waitForCompletion(true)?0:1);
}
}map函数
public class TokenizerMapper extends Mapper<LongWritable,Text,ImmutableBytesWritable,Put>{
// private final static IntWritable one = new IntWritable(1);
// private Text word = new Text();
// public static Configuration cfg = HBaseConfiguration.create();
// public static Table table2= null;
// public static final Connection conn=null;
public void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
// Connection conn = ConnectionFactory.createConnection();
// table2 = conn.getTable(TableName.valueOf("play_record_file5"));
String item = value.toString();
String[] detail = item.split("\\|"); //
// the 16bit md5 values of userId and current timestmap as the rowkey
String collectTime = detail[0];
byte[] bytes = Bytes.toBytes(collectTime); //collect time
String hashPrefix = MD5Hash.getMD5AsHex(bytes).substring(0,8); //time hash
byte[] time = Bytes.toBytes(System.currentTimeMillis()); //system time
byte[] bytes2 = Bytes.toBytes(hashPrefix);
byte[] rowKey =Bytes.add(bytes2, bytes, time);
// byte[] timestamp = DigestUtils.md5(Long.toString(System.currentTimeMillis()));
// byte[] userIdHash = DigestUtils.md5(detail[5]);
// byte[] rowKey = new byte[timestamp.length+userIdHash.length];
// int offset = 0;
// offset = Bytes.putBytes(rowKey, offset, userIdHash, 0, userIdHash.length);
// Bytes.putBytes(rowKey,offset,timestamp,0,timestamp.length);
Put p1 = new Put(rowKey);
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("collect_time"), Bytes.toBytes(detail[0]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("stb_id"), Bytes.toBytes(detail[1]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("stb_ip"), Bytes.toBytes(detail[2]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("region1"), Bytes.toBytes(detail[3]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("region2"), Bytes.toBytes(detail[4]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("user_id"), Bytes.toBytes(detail[5]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("pppoe_id"), Bytes.toBytes(detail[6]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("auth_id"), Bytes.toBytes(detail[7]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("cpu_use_rate"), Bytes.toBytes(detail[8]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("memory_use_rate"), Bytes.toBytes(detail[9]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("harddisk_use_rate"), Bytes.toBytes(detail[10]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("play_error_numbers"), Bytes.toBytes(detail[11]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("multi_req_numbers"), Bytes.toBytes(detail[12]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("multi_fail_numbers"), Bytes.toBytes(detail[13]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("multi_abend_numbers"), Bytes.toBytes(detail[14]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("vod_req_numbers"), Bytes.toBytes(detail[15]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("vod_fail_numbers"), Bytes.toBytes(detail[16]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("vod_abend_numbers"), Bytes.toBytes(detail[17]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("uni_avg_packet_lost_rate"), Bytes.toBytes(detail[18]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("uni_avg_bit_rate"), Bytes.toBytes(detail[19]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("auth_numbers"), Bytes.toBytes(detail[20]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("auth_fail_numbers"), Bytes.toBytes(detail[21]));
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("http_req_num"), Bytes.toBytes(detail[22]));
try {
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("http_req_fail_num"), Bytes.toBytes(detail[23]));
} catch (Exception e) {
// TODO Auto-generated catch block
p1.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("http_req_fail_num"), Bytes.toBytes(""));
}
if(!p1.isEmpty()){
ImmutableBytesWritable ib = new ImmutableBytesWritable();
ib.set(Bytes.toBytes("terminal_data_file1"));
context.write(ib, p1);
}
//
// StringTokenizer itr = new StringTokenizer(value.toString());
// while(itr.hasMoreElements()){
// word.set(itr.nextToken());
// context.write(word, one);
// }
}
}














 962
962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









