









一.所需技能
1.搭建环境请参考http://blog.csdn.net/hadoop_83425744/article/details/49254741里面环境搭建
2.必须掌握protocol buffer
3.了解hbase的流程
二.环境搭建
1.推荐环境搭建使用linux,通过hadoop在windows的二次开发的教训决定直接使用linux环境开发,win环境错误可以留言帮其他人参考
2.通过之前的hadoop的搭建文章我们照搬过来,下载hbase源码并打开,下载地址http://archive.apache.org/dist/hbase/ 请务必下载 hbase-version-src.tar.gz 的文件
3.下载好了之后导入全部的文件,修改pom文件,使用pom.xml.hadoop2 的文件作为项目的pom文件,参考hadoop文章,至此我们就搭建好了一个hbase开发环境,如果有错误且自己有强迫症,请在错误的项目下面导入hbase程序的lib下面所有的包
三.大概思路
1.开发自定义的filter我们需要首先开发他的通讯协议,因为hbase是通过protocol buffer序列化,我们首先进行filter protocol的开发
2.协议导入之后我们可以直接开发filter,在开发中切记加入tobytes和parsen(稍后会讲解)
四.开始开发filter
本案例演示如何开发一个过滤key的filter
1.开发filter需要了解的2个文件结构
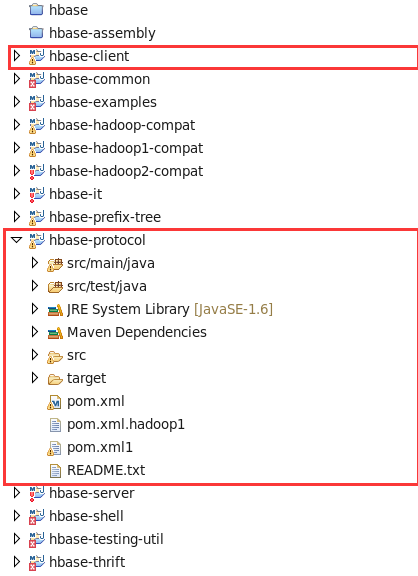
a.hbase-client是我们需要写filter的项目
b.hbase-protocol是我们开发所有的通讯协议的项目,我们的protocol就在这里加工
1.开发protocol buffer
a.找到hbase-protocol项目,
1.org.apache.hadoop.hbase.protobuf.generated是protocol文件生成代码的地方
2.src.main.protobuf文件夹下面是存放所有proto文件的地方
b.接下来找到我们需要添加的Filter.proto文件并打开

1. 根据上面的内容我们模仿添加一个myfilter的对像,无属性,(可以填写属性,但是如果有属性必须在序列化的时候添加参数,否则程序卡死也不会出现报错,深坑)
2. 因为尝试使用mvn命令generated无法自动生成java,所以使用命令行直接生成并覆盖原来的FilterProtos.hava文件
a.跳转到src.main.protobuf,运行命令 protoc --java_out=./ Filter.proto 一定要跳到这个目录下面,否则容易粗大事
b.生成好了我们点进去...发现现在目录下面又生成了org.apache.hadoop.hbase.protobuf.generated文件目录..我们进去找到我们生成的代码,然后覆盖之前在src.main.org.apache.hadoop.hbase.protobuf.generated
c.成功完成了protocol的开发,我们打包. 在项目下面输入mvn package 后在target找到生成的jar文件,
d.把生成的jar文件放到我们的集群的{{hbasehome}}/lib/下面,替换原来的
e.如果在windows 开发使用mvn管理的也需要替换maven仓库中的hbase-protocol,替换好了就OK了
f.最后一步在client中关联现在的包此时,我们的client也可以使用我们的protocol buffer啦

2.开发filter
a.在org.apache.hadoop.hbase.filter下面创建一个类 myFilter(为什么一定要在这里开发,因为basefilter 类里面的序列化是个私有方法,在其他地方无法调用,所以也就无法完成单独jar开发的任务)
package org.apache.hadoop.hbase.filter;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.KeyValueUtil;
import org.apache.hadoop.hbase.exceptions.DeserializationException;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterBase;
import org.apache.hadoop.hbase.protobuf.generated.FilterProtos;
import org.junit.Test;
import com.google.protobuf.InvalidProtocolBufferException;
@InterfaceAudience.Public
@InterfaceStability.Stable
public class MyFilter extends FilterBase {
/**
* true的时候就表示该行被过滤
*/
private boolean filterRow = false;
public MyFilter() {
}
/**
* 如果scan 已经指定列族里面的列标示符,cell就是标示符的这一列,如果没有指定列标示符,他会循环调用每一列,
所以我这里可以判断只有screen这一列的时候才进行判断,遇到其他列就直接跳过
*/
@Override
public ReturnCode filterKeyValue(Cell cell) throws IOException {
if (new String(CellUtil.cloneQualifier(cell)).equals("screen")) {
if (new String(CellUtil.cloneValue(cell)).equals("1440x900")) {
return ReturnCode.INCLUDE;
} else {
this.filterRow = true;
return ReturnCode.SKIP;
}
} else {
return ReturnCode.NEXT_COL;
}
}
/**
* 返回该行是否被过滤
*/
@Override
public boolean filterRow() throws IOException {
return this.filterRow;
}
/**
* 每行完成之后重置
*/
@Override
public void reset() throws IOException {
this.filterRow = false;
}
/**
* 通过参数创建一个filter 参照其他过滤器使用
* @param filterArguments
* @return
*/
public static Filter createFilterFromArguments(
ArrayList<byte[]> filterArguments) {
return new MyFilter();
}
/**
* 使用PB序列化对象
*/
public byte[] toByteArray() {
FilterProtos.MyFilter.Builder builder = FilterProtos.MyFilter
.newBuilder();
byte[] byteArray = builder.build().toByteArray();
return byteArray;
}
/**
*
* @param pbBytes
* @return 这里本来是解析参数的,因为我这里没有参数 所以不用填写 如需要参数可以参照其他过滤器
* @throws DeserializationException
*/
public static MyFilter parseFrom(final byte[] pbBytes)
throws DeserializationException {
try {
FilterProtos.MyFilter.parseFrom(pbBytes);
} catch (InvalidProtocolBufferException e) {
throw new DeserializationException(e);
}
return new MyFilter();
}
/**
* 标记是否进行序列化 我们这里选择是 参照keyvaluefilter
*/
boolean areSerializedFieldsEqual(Filter o) {
if (o == this)
return true;
if (!(o instanceof MyFilter))
return false;
return true;
}
// @Test
// public void testPB(){
// FilterProtos.MyFilter.Builder builder =
// FilterProtos.MyFilter.newBuilder();
// byte[] byteArray = builder.build().toByteArray();
// }
}
b.写完之后可以参照protocol中的c d e步骤
3.把两个包都分别放入了我们生成集群的lib下面和我们开发所需的maven仓库之后,便可以直接调用啦, 经过改造我们不需指定列标示符就能得到1440*900的分辨率的信息
@Test
public void testMyFilter(){
// scan.addColumn(INFO, SCREEN);
Filter myFilter = new org.apache.hadoop.hbase.filter.MyFilter();
scan.setFilter(myFilter);
getres();
}
五,如需开发其他类型的filter,请参照其他filter开发,returnCode类里面的参数在开发前务必看一遍,了解参数类型














 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









