







我是一个python小白,借着学习掌握机器学习算法的心情,学习应用下python,记录下来,分享一下,更好意见欢迎交流。
- kmeans算法的基本思路
- kmeans是把D中的对象分配到k个簇C1,C2,...,Ck 中,用一个目标函数来评估划分的质量,使得簇内对象相互相似,而与其他簇中对象互异。如何度量事物的相似性有距离度量的算法,比如欧式距离,编辑距离等,相似度的算法有余弦相似度,皮尔逊系数等等。
- kmeans算法描述
- 质心的个数就是要聚类的类数目,因为所有的样本最后都会聚集在这几个质心周围)
计算每个样本距离质心的距离
样本距离哪个质心近,就将每个对象分配到最相似的簇
统计一个质心下样本的平均值
用每个质心下样本的平均值更新质心
- 终止条件:
- 当样本的分类所属质心不在发生变化时,迭代结束。
- 或者指定一定的迭代次数,重复以上过程。
- 最小平方误差
import numpy as np
import random
import matplotlib.pyplot as plt
#涉及python知识点
#随机数的生成,生成矩阵
#数组的按行,按列操作 取,加,减
#数组的按布尔读取
#数组的按列按行赋值
#欧氏距离、平均数的计算
def distance(sub1,sub2):
result=sub1-sub2 #numpy的数组可以对一个向量做减法,得到的还是一个向量
return np.sqrt(np.sum(np.square(result))) #对向量做平方,求和,开方,得到sub1和sub2的欧式距离
K=4
d=np.random.randint(1,100,120) #从1~100之间选择生成120个随机数
x=d.reshape(60,2) #把这120个随机数转换成60行2列的矩阵
tempclass=np.zeros(x.shape[0]) #获得x的第0列的维度
center = random.sample(range(x.shape[0]),K)#从x的第0列数中随机挑选k个数
centerArray = x[center,:] #从x中 获得以center的序列内容为行的向量,列数是从第0列到最后一列
# 至此完成了对 kmeans 中心点的生成,质心
def kmeans(centerArray):
for i in range(60): #因为是60行数据,这里要准备逐条遍历x的60行数据
mindis=10000;
sub1=x[i,:] #获取矩阵x的第i行数据
for j in range(K):
sub2=centerArray[j,:] # 按行读取质心列表中的行向量
temp = distance(sub1,sub2) # 逐个元素计算与质心的距离
#print ("the disctent %d"%(temp))
if (temp<mindis): # 在k个质心里面选择距离最小的
mindis=temp
tempclass[i]=j #得到样本i 距离最近 质心
print (tempclass)
#更新质心
for j in range(K): #按照质心个数,统计每个质心下面的样本
tempclassResult = x[tempclass==j] #从分类结果里面分别拿到每个类的样本
x1=np.mean(tempclassResult[:,0]) #取出tempclassResult里面第0列的值序列,并对这个序列计算均值
x2=np.mean(tempclassResult[:,1])
centerArray[j,:]=[int(x1),int(x2)] #更新质心数组里面的质心坐标
#迭代100次
for i in range(100):
print("i=%d"%i)
kmeans(centerArray)
#绘图 显示
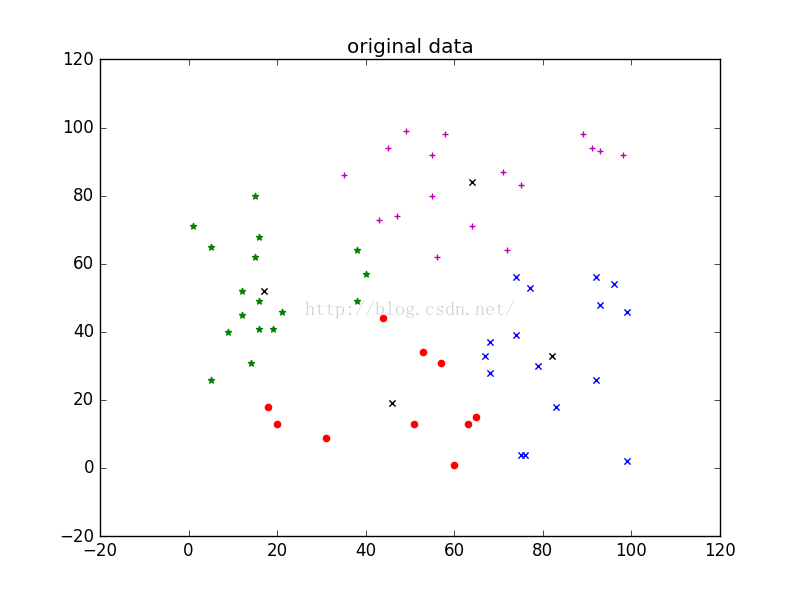
for i,c in zip(range(K),['r','m','b','g','y']):
cla=x[tempclass==i]
p1=plt.scatter(cla[:,0],cla[:,1],marker='o',color=c,label='x')
p2=plt.scatter(centerArray[:,0],centerArray[:,1],marker='x',color='black',label='x')
plt.title('original data')
plt.legend(loc='upper right')
plt.show()
附上一张 迭代100次的结果图片














 1189
1189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









