










3月份的时候,由于工作需要使用python+scrapy框架做了一个新闻舆情的爬虫系统,当时任务比较紧自己也没有搞过爬虫,但最终还是较好的完成了任务,现在把做的大致思路记录分享一下。
首先,展示一下部分截图吧:

本文主要内容如下:
- 开发背景
- 开发的大致思路
- 代码框架的介绍
开发背景
近两年国家对网络的内容监管十分的严格,前一两年被称为“网络直播年”因此出现了有很多直播公司。我们需要第一时间知道有关直播的新闻(直播新闻的特点是新闻会根据标题(包含“直播”,“女直播”)吸引网络用户阅读)。因此我的大致思路是获取各大新闻网站所有的含有相关关键词的新闻,爬取其url以及标题。
开发大致的思路
由于前面也没有做过爬虫相关的内容,于是google搜索了一下“python common scrape website framework”最终确定使用scrapy框架。
首先找到了一个scrapy 完成了一个爬取stack overflow的的示例大致知道了scrapy的用法。
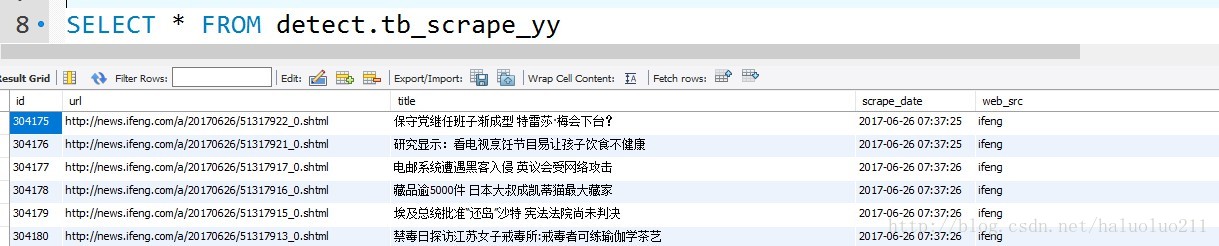
会使用了基本的爬取之后,于是将爬取的结果存储到数据库
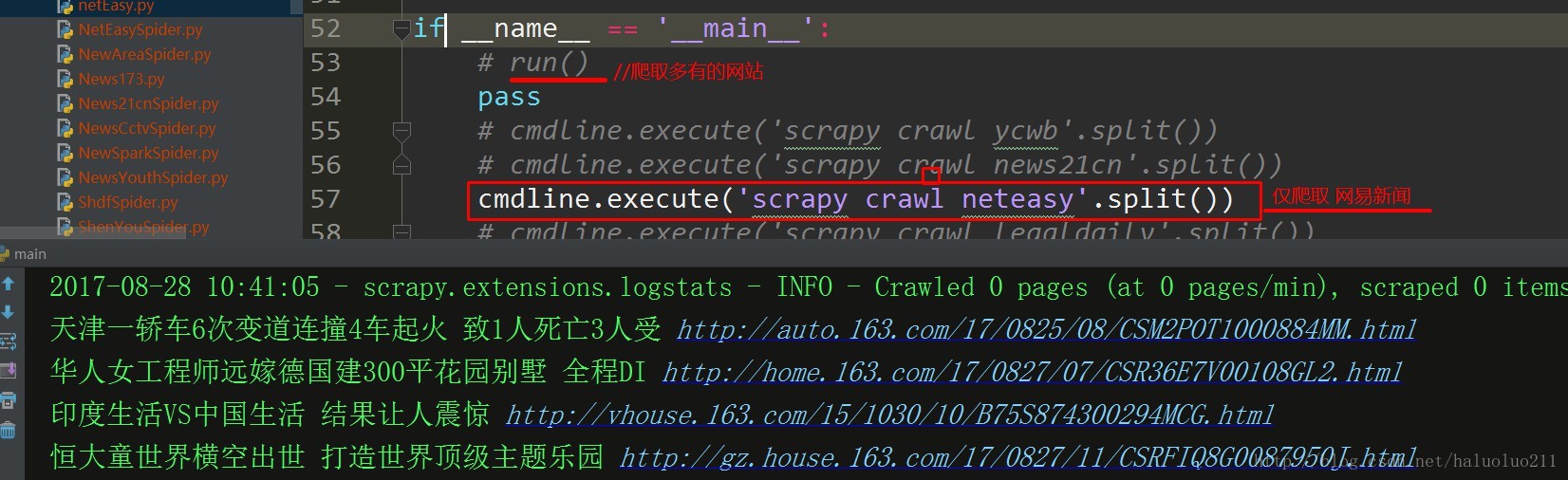
由于要爬取很多网站,结合scrapy框架的特点设计了一个公共的爬虫模板类,当需要爬取其他网站的时候只需要,写配置文件,以及网站的XPath结构即可
当网站爬取出现问题(网站结构发生改变的时候)会给自己的邮箱发一封邮件提醒自己修改
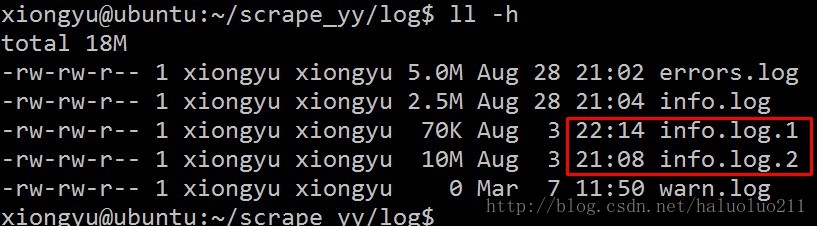
爬虫系统上线大概五个多月,挂了2~2次,最终写了个shell脚本,当系统挂了,会自动重新启动爬虫程序
代码框架大致介绍
首先上个代码框架的截图吧
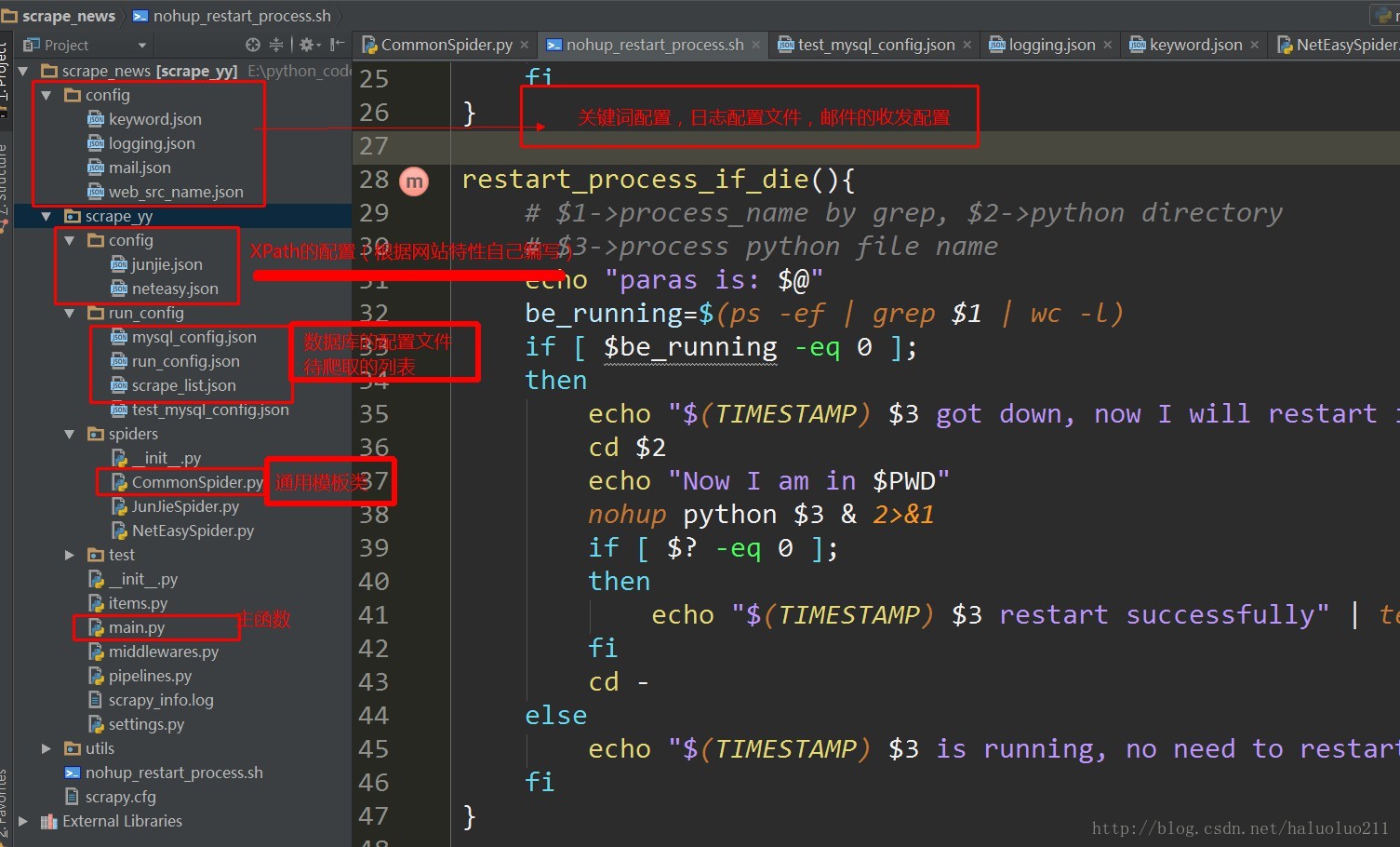
代码在个人github上面
注意:
- 实际使用中我大概爬取了30多个网站,但是不太方便上传多有的待爬取网站的结构,这里只上传了2个
- 运行代码的时候需要注释掉有关数据库以及发送邮件的模块,或者你自己看代码创建数据库以及表,应该还是很简单的
代码的注释还是挺多的,相信大致看一下跑一下应该没什么问题。














 1681
1681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









