









本文主要内容:
通过简单的示例说明决策树,以及决策树的定义
信息熵概念,以及决策树,树生成节点划分的依据。三种计算方法方法:
1.信息增益(由ID3算法作为特征选取标准)
2.信息增益比/率(由C4.5算法作为特征选取标准)
3.基尼指数(由CART作为特征选取标准)
树的生成ID3算法,C4.5算法
算法python实现以及示例
决策树示例,以及决策树的定义
下图决策树预测贷款用户是否具有偿还贷款的能力,其中贷款用户主要具备三个属性:是否拥有房产,是否结婚,平均月收入。
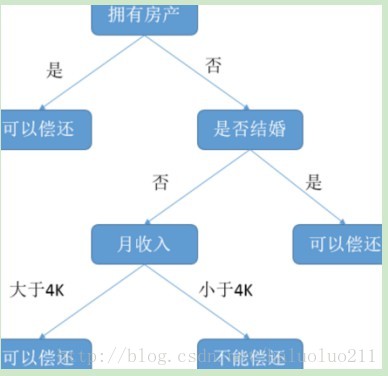
每一个内部节点都表示一个属性条件判断,叶子节点表示贷款用户是否具有偿还能力(即类别)。
例如:用户甲没有房产,没有结婚,月收入5K。通过决策树的根节点判断,用户甲符合右边分支 (拥有房产为“否”);再判断是否结婚,用户甲符合左边分支(是否结婚为否);然后判断月收入是否大于 4k,用户甲符合左边分支 (月收入大于4K),该用户落在“可以偿还”的叶子节点上。所以预测用户甲具备偿还贷款能力。
定义(决策树)
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node )和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
分类过程
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
信息熵,决策树,树生成节点划分的依据
在信息论里面,熵(entropy)是信息不确定性的一个测度,熵越大则表示信息的不确定程度越高。这么说好像的确有点抽象,还是用公式解释吧:
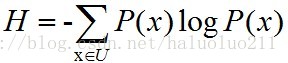
这里H是熵,U可以理解为所有可能事件的集合,P(x)则是某一具体事件x发生的概率,对数的底一般取2。举个例子,预测明天的天气,如果能100%确定明天一定是晴天,那么熵就是-1*log1=0,也就是说不确定性为零。如果说明天有50%概率晴天,50%概率下雨,那么熵就是2*(-0.5)log0.5=2*(-0.5)(-1)=1,可以说不确定性为1。而如果明天有25%概率晴天,25%概率下雨,25%概率阴天,25%概率下雪,那么熵就是4*(-0.25)(log0.25)=2, 也就是说随着不确定程度的增加,熵也在不断地增大。
多少信息用信息量来衡量,我们接受到的信息量跟具体发生的事件有关。信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如四川发生地震了;越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了(肯定发生嘛,没什么信息量)。这很好理解!
当随机变量只能取两个值,例如1,0即X的分布为:
P(X=1)=p, P(X=0)=1-p, 0<=p<=1
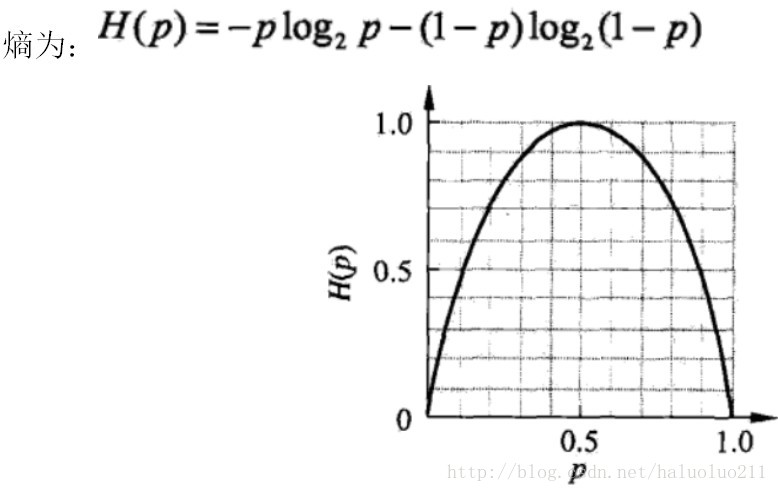
当p=0.5时,熵取值最大,随机变量不确定性最大(这个概率对我们”分类基本没什么用”)
计算增益,有三种方法:
信息增益(由ID3算法作为特征选取标准)
信息增益比/率(由C4.5算法作为特征选取标准)
基尼指数(由CART作为特征选取标准)
信息增益
首先说明下条件熵:

定义(信息增益(information gain))
信息增益表示的是:得知特征X的信息而使得类Y的信息的不确定性减少的程度。
具体定义如下:
特征A对训练数据集D的信息增益g(D,A)定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即g(D,A)=H(D)-H(D|A)根据信息增益准则进行特征选择的方法是:对训练数据集D,计算其每个特征的信息增益,选择信息增益最大的特征。

信息增益算法:
输入:训练数据集D和特征A;
输出:特征A对训练数据集D的信息增益g(D,A)
(1)计算数据集D的经验熵H(D).
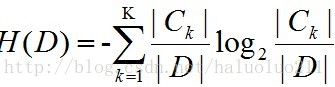
(2)计算特征A对数据集D的经验条件熵H(D|A).
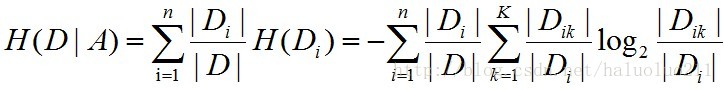
(3)计算信息增益: g(D, A) = H(D) - H(D|A)
下面给出李航书中贷款申请判断的数据,以及计算示例。四个属性:
年龄: 0 -> 青年, 1 -> 中年, 2 -> 老年
有工作: 0 -> 否, 1 -> 是
有房子: 0 -> 否, 1 -> 是
信贷情况: 0 -> 一般, 1 -> 好, 2 -> 非常好
对应的Y类别0 -> 不能提供贷款, 1 -> 能提供贷款,
def get_loan_data_lh():
x = np.array([
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2],
[0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0],
[0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0],
[0, 1, 1, 0, 0, 0, 1, 1, 2, 2, 2, 1, 1, 2, 0]
])
x = x.T
y = np.array([0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0])
return x, y首先计算类别的经验熵:
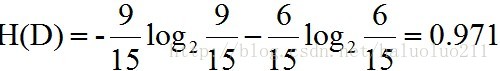
对应的代码如下:
def _cal_class_entropy(self, y):
num = len(y)
print num # 15
unique_class, counter = np.unique(y, return_counts=True)
print unique_class, counter
# [0 1] [6 9]
# calculate each class probability
class_prob = [c * 1.0 / num for c in counter]
print class_prob
# [0.40000000000000002, 0.59999999999999998]
print self._cal_entropy(class_prob)
# 0.970950594455
def _cal_entropy(self, arr_prob):
"""
for example arr_prob like [0.5, 0.5]
return -1 * 0.5 *log0.5 + -1 * 0.5 * log0.5 = 1
"""
# -1 * sum(Pi * logPi)
return np.sum(-1 * np.log2(arr_prob) * arr_prob)
def test_cal_class_entropy():
from create_data import get_loan_data_lh
X, Y = get_loan_data_lh()
dt = DTree()
dt._cal_class_entropy(Y)














 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









