








前言
今天浅谈一下js的解释器的尾调用优化机制,顺便提一下with 和 eval对其性能的影响。
eval和with语句都会对词法阶段的作用域产生影响。JavaScript引擎会在编译阶段进行数项的性能优化。其中有些优化依赖于能够根据代码的词法进行静态分析,并预先确定所有变量和函数的定义位置,才能在执行过程中快速找到标识符。—-《你不知道的javascript》
js 的 解释器的解释过程
要想知道eval和with是如何影响浏览器的性能。我们首先要大概的了解一下浏览器解析JavaScript语句的过程。
- 分词/词法分析
在这个过程中,会将一句一句的代码,分成一块一块有意义的代码块。这些代码块称为词法单元。例如:一句简单的赋值语句会被分成。var , 变量名, =, 变量值。四个部分。
- 语法分析
语法分析是编译过程的一个逻辑阶段。语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等。
- 代码生成
将代码转成可以执行的代码的过程称为代码生成。这个过程不同语言会不相同。
js解释器会在词法分析阶段确定作用域,以及变量定义的位置,以便在以后调用中迅速的找到。
js中的with 和 eval
1.with
with可谓是一股清流,在冗长的代码开发中,with能够让我们轻松许多,比如有一个这样的JSON对象
let person = {
zhangsan:{
name:'zhangsan',
age:19
},
lisi:{
name:'lisi',
age:20
}
};现在我们想要获取person的张三的name和age值。用with我们可以这样做
with(person.zhangsan){
console.log(name);
console.log(age);
}假如zhangsan有多个属性的话,可想而知with能减少我们多少的工作量。
然而这样却会带来一个矛盾,因为with会创造它自己的作用域,在词法分析阶段,js的解释器根本知道这里的name 和 age到底是属于全局变量还是person.zhangsan的属性,换一种说法而言,with会动态的创造作用域,这样解释器的静态分析就显得很无力了,这时,如果遇到with关键字,js解释器就会放弃优化,因为这样的优化都是无意义的。
比如我们再测试一个例子,可能就已经GG了。
let obj = {
zhangsan:{
name:'zhangsan',
age:19
}
}
let n = 1e6;
let nam;
console.time("with");
with(obj.zhangsan){
for(let i = 0;i < n;i++){
nam = name;
}
}
console.timeEnd("with");
console.time("no with");
for(let i = 0;i < n;i++){
nam = obj.zhangsan.name;
}
console.timeEnd("no with");下面是打印的结果:
with: 446.287ms
no with: 10.845ms可以看出,用了with的执行时间比没用with的执行时间多了整整几十倍。
2.eval
eval 是可以计算参数内的值的一个函数,也可以将string变为可执行代码。
eval("name='lisi'");
console.log(name);我们给eval传递了一个字符串,但是它却执行了,我们可以清楚的看到控制台打印了lisi
output:
lisi但糟糕的是,eval仍然会创造自己的私有作用域。
因此从js的性能来讲,在实际的开发过程中,我们尽量不要使用eval或者with。
js的尾调用优化
首先我们必须明白,在js的函数中有两个属性为arguments 和 func.caller
我们现在来尝试一下打印这两个属性,在箭头函数中,this始终指向自己,因此,我们尝试打印这个func的arguments
let func = () => {
console.log(arguments);
}
func();可以在控制台看到,我们打印出了func所具有的参数。
{ '0': {},
'1':
{ [Function: require]
resolve: [Function: resolve],
main:
Module {
id: '.',
exports: {},
parent: null,
filename: 'E:\\NodeJSTest\\test3.js',
loaded: false,
children: [],
paths: [Object] },
extensions: { '.js': [Function], '.json': [Function], '.node': [Function] },
cache: { 'E:\NodeJSTest\test3.js': [Object] } },
'2':
Module {
id: '.',
exports: {},
parent: null,
filename: 'E:\\NodeJSTest\\test3.js',
loaded: false,
children: [],
paths: [ 'E:\\NodeJSTest\\node_modules', 'E:\\node_modules' ] },
'3': 'E:\\NodeJSTest\\test3.js',
'4': 'E:\\NodeJSTest' }由于我这里是node.js环境下进行测试,因此除开索引为0的函数参数以外,还有一些额外的参数。
现在我来试着打印一下它的caller属性。
let func = () => {
console.log(func.caller);
}
func();我们发现并不能被执行成功,并且报了一个错误。
TypeError: 'caller' and 'arguments' are restricted function properties and cannot be accessed in this context.从报错的角度看来我们被告知不能在此上下文中访问到caller,下面我们换作构造函数来尝试一下。
let Func = function(){
this.print = function(){
console.log(this.print.caller)
}
}
let func = new Func();
func.print();下面打印出来的是一个函数对象
[Function]实际这里指代的是整个模块对象。我们把整个函数对象toString()试试,再次打印
function (exports, require, module, __filename, __dirname) { let Func = function(){
this.print = function(){
console.log(this.print.caller.toString())
}
}
let func = new Func();
func.print();
}
接下来我们试着通过另一个函数来调用func
let func = function(){
console.log(func.caller);
}
let func2 = () => {
func();
}
func2();你会发现控制台打印的caller是func2
[Function: func2]
这样我们可以知道,在js里可以通过caller和arguments 来追踪函数的调用栈。
实际上我们知道,当一个函数调用的时候,会在内存里形成一个调用记录,我们称之为调用帧(call frame),call frame用来记录函数的调用位置以及其它的信息,在js里,调用帧被储存到解释器所分配的堆里的年轻代里,因为调用帧是经常变化并且生命周期短暂的一个对象。
如果多个函数互相调用就会形成一个调用栈。比如我这里func2 调用 func ,func3 调用func2
let func = () => {
console.log("hello");
}
let func2 = () => {
func();
}
let func3 = () => {
func2();
}
func3();调用栈如图所示:
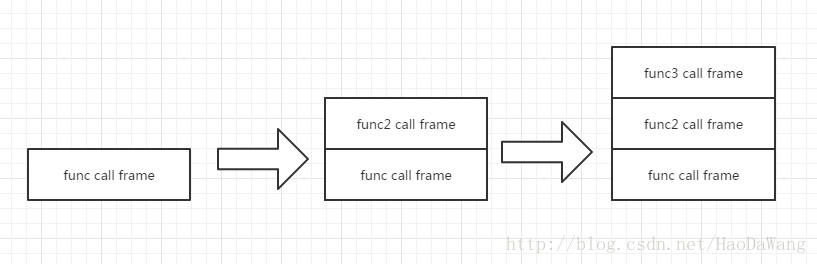
由于函数中的caller属性,它会追踪函数的调用情况,arguments会追踪函数的参数传递,因此,如果很多个函数调用,调用栈就会庞大起来,幸运的是,ECMA5 中新添加的严格模式 “use strict”,会禁用这两个属性,这样我们就能实现一种优化,叫作尾调用优化。
尾调用优化主要在于,函数可以不处于最后的位置,但是必须处于最后一步调用,这样上一个调用的函数帧就不必保存了,我们也不需要再去保存,因为已经用不到了,在此情况下,caller也不用自作多情的再去追踪函数的调用情况。
js 递归尾调用优化
在平常的递归中,js解释器如果不发起尾调用优化的话,那么很有可能抛出一个内存溢出的Error(OOM),在chrome V8解释器中,在64位系统下,分配给js的有1.4个G的内存,32位下只有0.7个G的内存,虽然说这些内存在浏览器客户端开发中绰绰有余,但是如果滥用递归的话还是会带来意想不到的后果,比如说OOM。
事实上,我们只用让我们的代码处于严格模式之下,然后用尾调用优化的话,这样的函数调用栈里只会保存一个函数的调用帧。这样也就有效的避免了内存溢出的问题。
"use strict"
let func = n => {
if(n == 1){
return 1;
}
return n * func(n - 1);
}
console.log(func(5));上述代码有效的避免了内存溢出,这里我们用了js解释器的尾调用优化,使得函数调用栈里永远只有一个调用帧。














 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









