









例如:
在实际的项目中,需要分析网站服务器的日志文件数据
需求:
统计每日六项指标
浏览量PV、访客数UV、IP数、跳出率、平均访问时长、转化次数
分析:
-1,原日志文件数据 job-mr
清洗:MapReduce
hdfs-files
-2,HiveQL job-hive
将数据加载到Hive表中:Shell Script
HQL
Hive-RESULT-TABLE
六个字段
-3,将分析结果导出到RDBMS表中(MySQL数据库) job-sqoop
SQOOP
涉及概念:
-1,依赖调度
job-sqoop <- job-hive <- job-mr
-2,定时调度
三个框架:
Azkaban、Oozie、Zeus(宙斯)
在企业中的离线分析,进行任务的调度,通常情况都是调度SHELL脚本。
SHELL脚本代码:
#!/bin/sh
### HADOOP_HOME
HADOOP_HOME=/opt/cdh-5.3.6/hadoop-2.5.0-cdh5.3.6
### HIVE_HOME
HIVE_HOME=/opt/cdh-5.3.6/hive-0.13.1-cdh5.3.6
### SQOOP_HOME
SQOOP_HOME=/opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6
##Step 1:job-mr
${HADOOP_HOME}/bin/yarn jar /opt/analyze/jars/webTrendDataFilter.jar TrendDataFilter /user/analyze/input /user/analyze/output
##Step 2:job-hive
${HIVE_HOME}/bin/hive -f /opt/analyze/scripts/webTrend.sql
##Step 3:job-sqoop
${SQOOP_HOME}bin/sqoop --options-file /opt/analyze/scripts/export-web.sh
案例分析
HIVE设置:
-1,FETCH TASK
set hive.fetch.task.conversion = more ;
-2,LOCAL MODE
hive.exec.mode.local.auto=true;
要处理的数据量小于HDFS BLOCK的大小(默认128MB) 此时使用本地模式
实质:
将MapReduce运行在本地。先将HDFS上的数据GET到本地,然后在本地运行一个JVM PROCESS运行MapReduce中的所有TASK。
-3,STRICT MODE
hive.mapred.mode=nonstrict;
1,创建数据库和表
create database
CREATE DATABASE IF NOT EXISTS db_track ; USE db_track ;create table
原数据表,创建为外部表 CREATE EXTERNAL TABLE yhd_logDROP TABLE IF EXISTS yhd_log ; CREATE TABLE yhd_log( id string, url string, referer string, keyword string, type string, guid string, pageId string, moduleId string, linkId string, attachedInfo string, sessionId string, trackerU string, trackerType string, ip string, trackerSrc string, cookie string, orderCode string, trackTime string, endUserId string, firstLink string, sessionViewNo string, productId string, curMerchantId string, provinceId string, cityId string, fee string, edmActivity string, edmEmail string, edmJobId string, ieVersion string, platform string, internalKeyword string, resultSum string, currentPage string, linkPosition string, buttonPosition string ) PARTITIONED BY (date string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ;describ table
desc yhd_log;
注意:分区表中的分区字段也属于表的字段(列)load data
load data local inpath '/opt/datas/2015082818' into table yhd_log partition (date = '20150828') ; load data local inpath '/opt/datas/2015082819' into table yhd_log partition (date = '20150828') ;



2,依据业务分析创建表
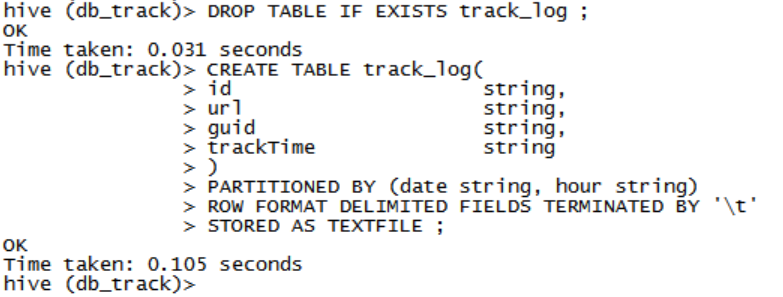
创建业务数据表track_log
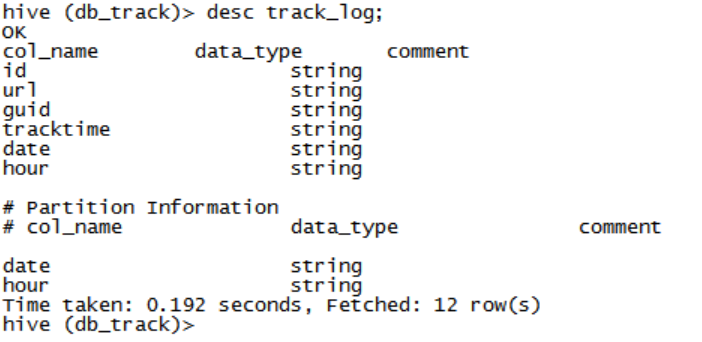
DROP TABLE IF EXISTS track_log ; CREATE TABLE track_log( id string, url string, guid string, trackTime string ) PARTITIONED BY (date string, hour string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ;描述表
表中的字段,data与hour为分区
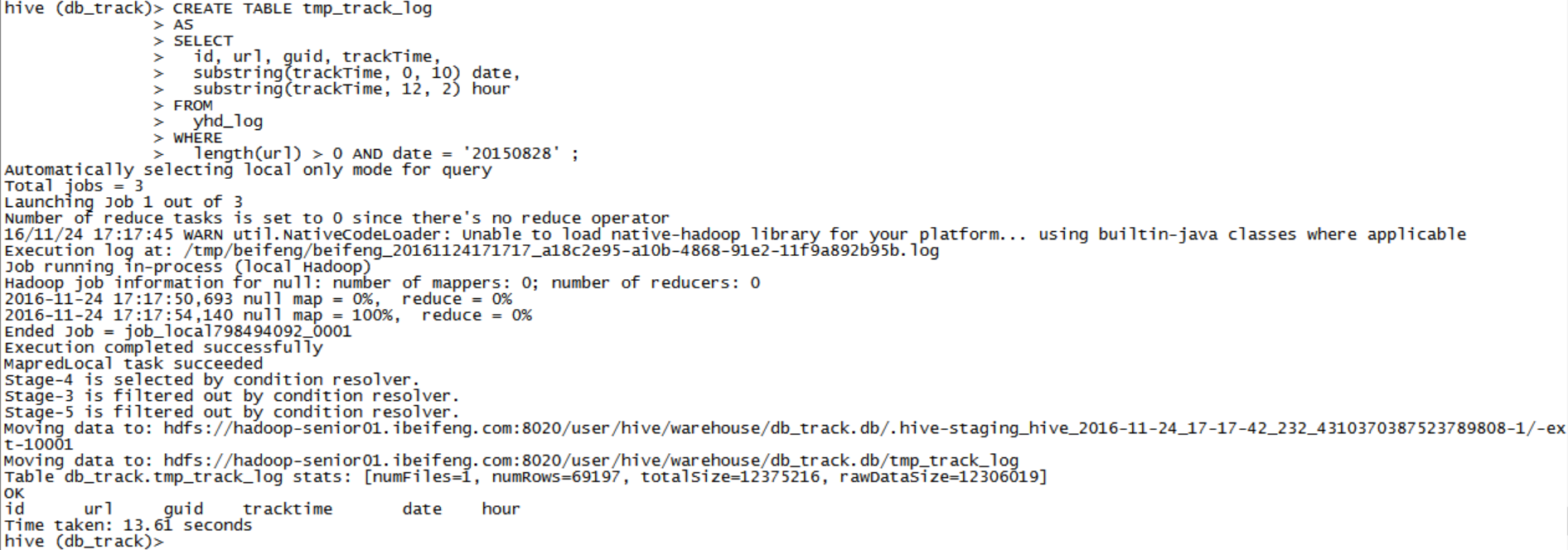
创建临时表tmp_track_log
-- 接下来: -- 要从yhd_log中获取数据,插入到track_log表中 -- 分析: -- 对于track_log中的分区字段的值,应该从trackTime中获取 -- 值的类型:2015-08-28 18:10:00,此时应该使用substring函数 -- 抽出临时表,CTASDROP TABLE IF EXISTS tmp_track_log ; CREATE TABLE tmp_track_log AS SELECT id, url, guid, trackTime, substring(trackTime, 0, 10) date, substring(trackTime, 12, 2) hour FROM yhd_log WHERE length(url) > 0 AND date = '20150828' ;采用的手动指定分区,静态分区,插入数据
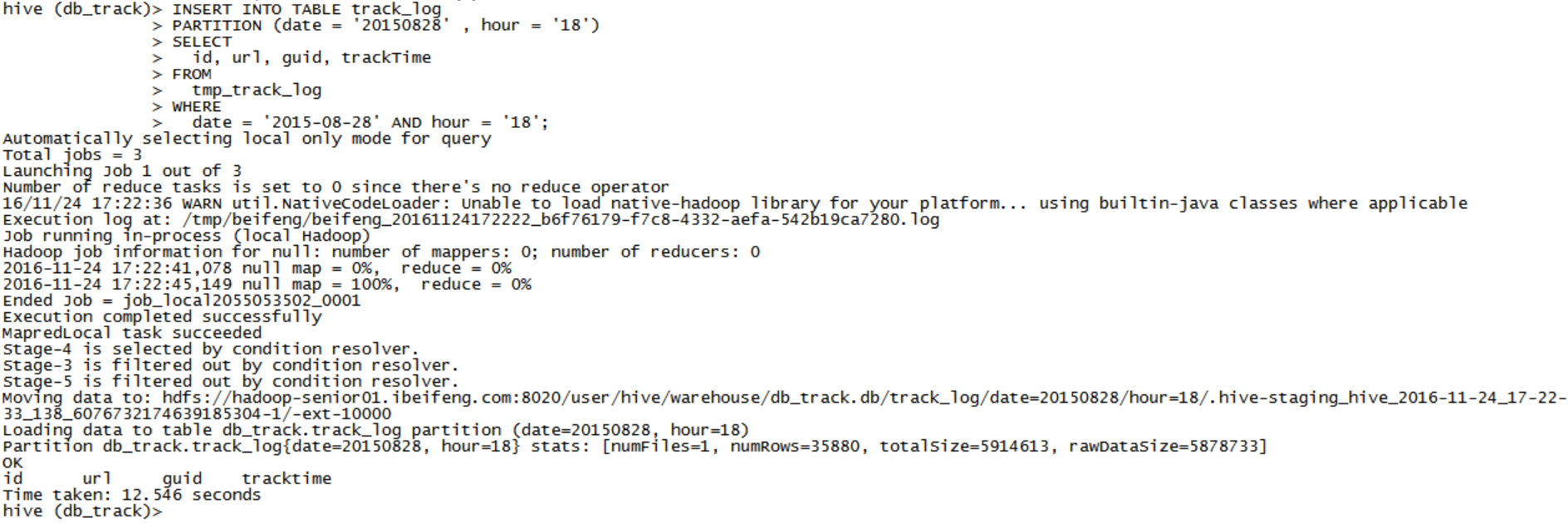
hour= 18
INSERT INTO TABLE track_log PARTITION (date = '20150828' , hour = '18') SELECT id, url, guid, trackTime FROM tmp_track_log WHERE date = '2015-08-28' AND hour = '18';- hour= 19
INSERT INTO TABLE track_log PARTITION (date = '20150828' , hour = '19') SELECT id, url, guid, trackTime FROM tmp_track_log WHERE date = '2015-08-28' AND hour = '19';
3,每日各时段PV和UV
分析一,PV
SELECT date, hour, COUNT(url) pv FROM track_log WHERE date = '20150828' GROUP BY date, hour ;- 分析二,UV
SELECT
date, hour, COUNT(DISTINCT guid) uv
FROM
track_log
WHERE
date = '20150828'
GROUP BY
date, hour ;
一条语句执行:pv, uv
SELECT date, hour, COUNT(url) pv, COUNT(DISTINCT guid) uv FROM track_log WHERE date = '20150828' GROUP BY date, hour ;
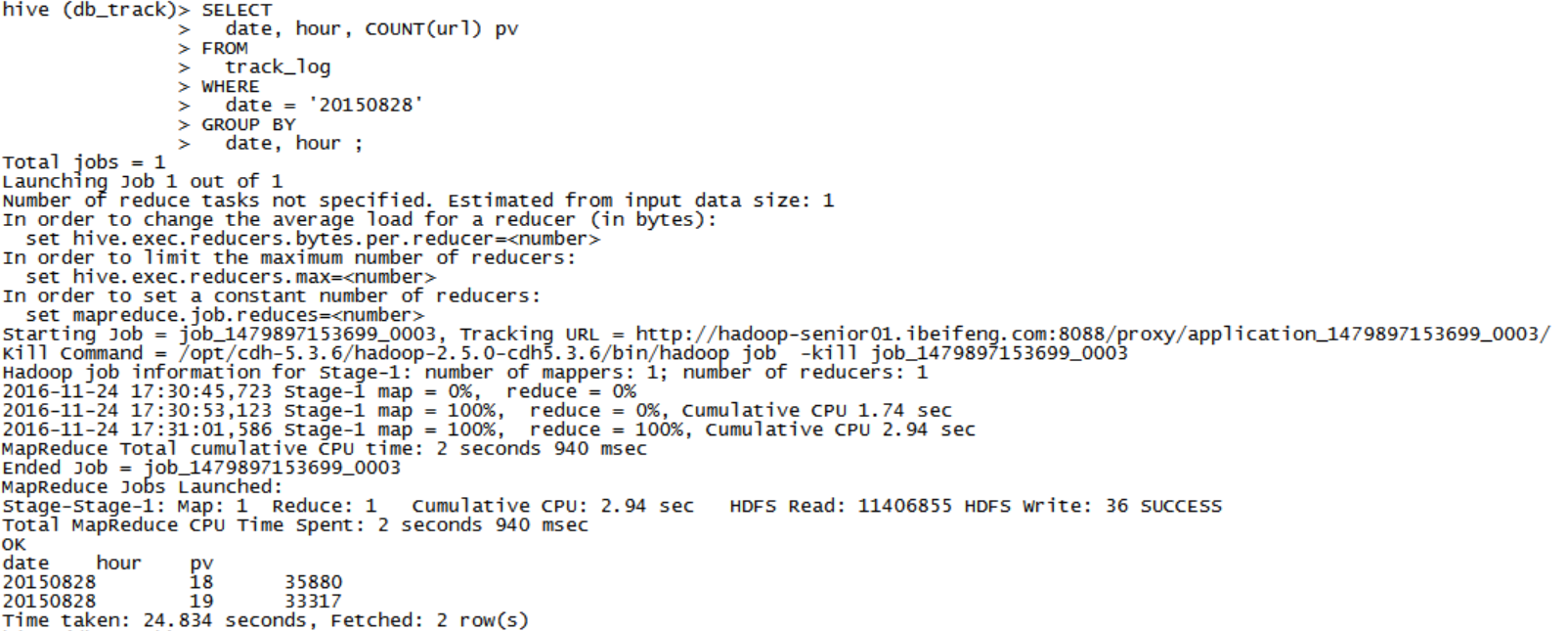
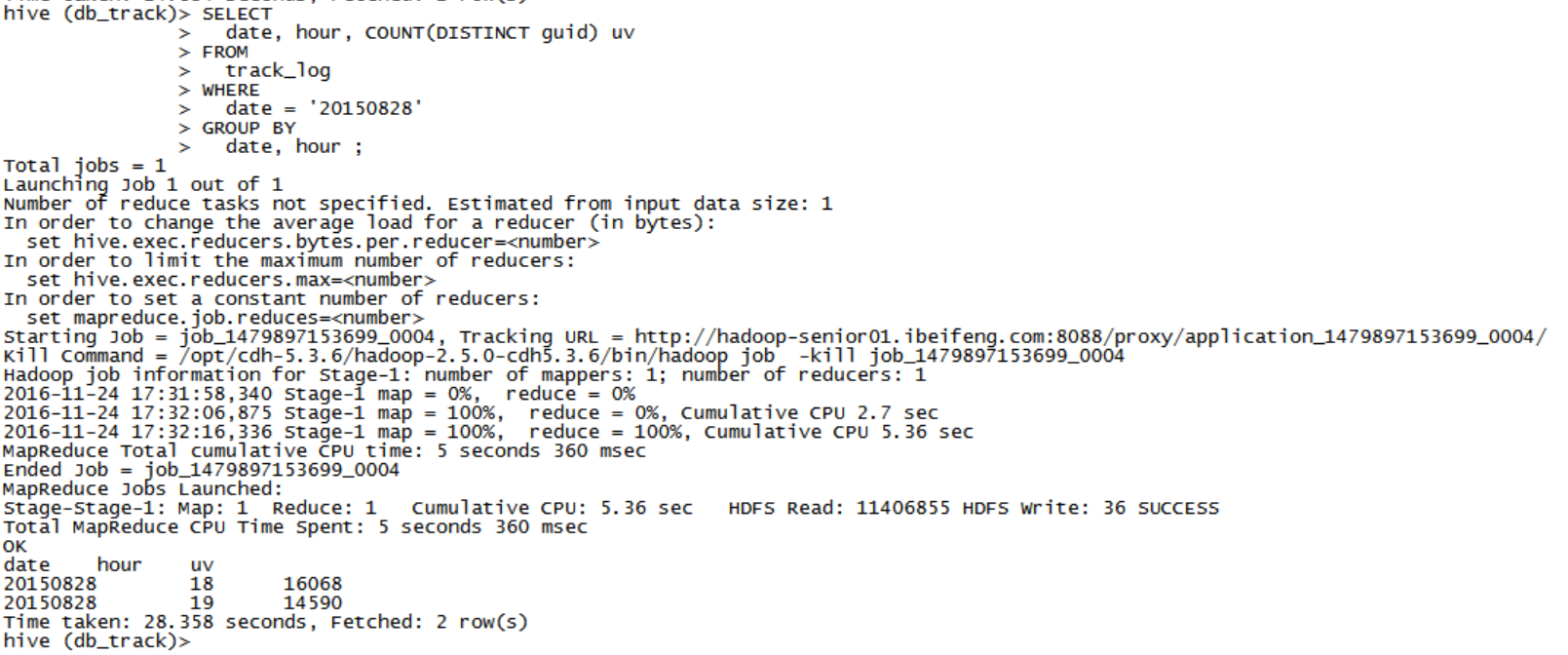
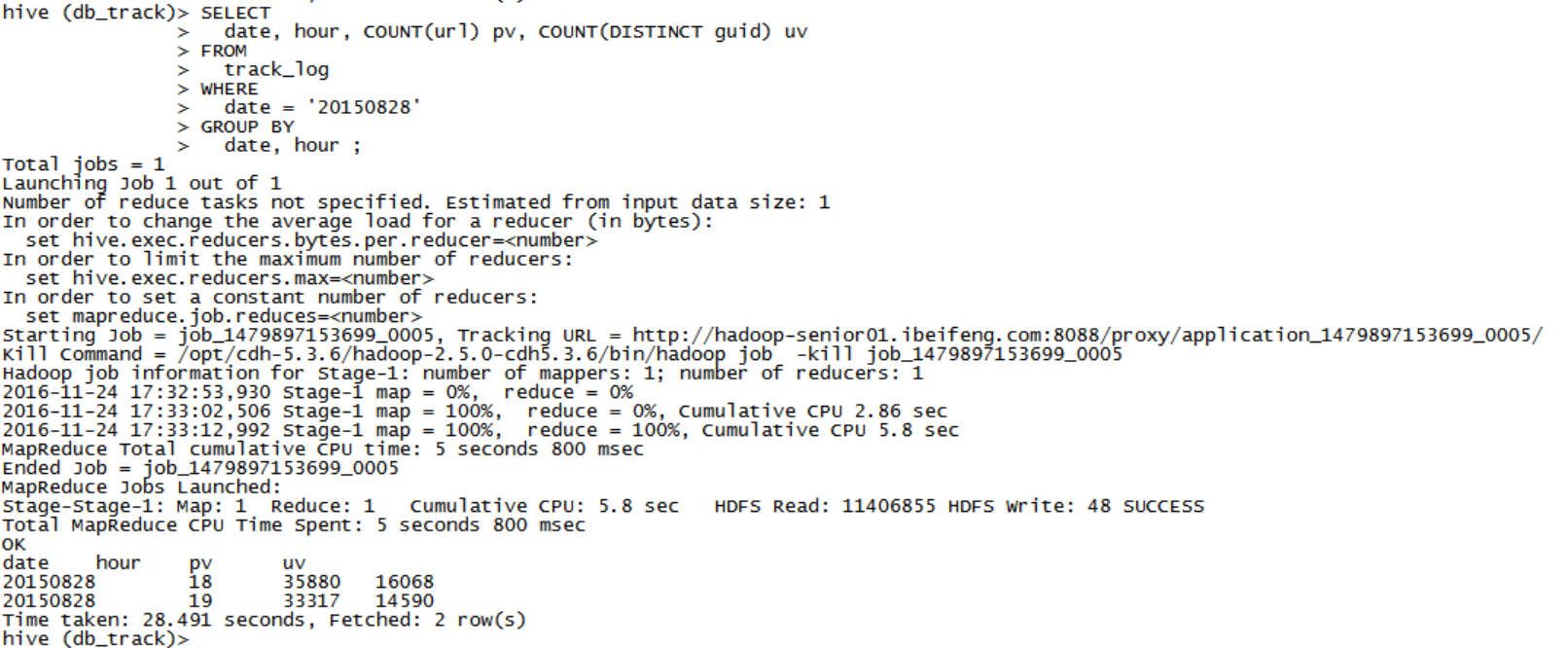
4,将数据存储到结果表
方式一:如果结果表仅仅用于暂时缓存结果的话,建议使用CTAS(CREATE TABLE AS)方式
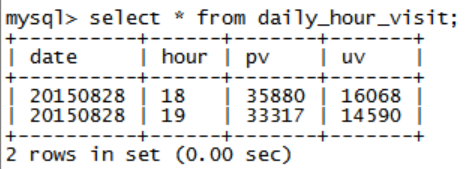
DROP TABLE IF EXISTS daily_hour_visit ; CREATE TABLE daily_hour_visit AS SELECT date, hour, COUNT(url) pv, COUNT(DISTINCT guid) uv FROM track_log WHERE date = '20150828' GROUP BY date, hour ;方式二:如果结果表存储所有的分析结果的话,先创建表,再插入
CREATE TABLE IF NOT EXISTS daily_hour_visit( date string, hour string, pv string, uv string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ;INSERT INTO TABLE daily_hour_visit SELECT date, hour, COUNT(url) pv, COUNT(DISTINCT guid) uv FROM track_log WHERE date = '20150828' GROUP BY date, hour ;

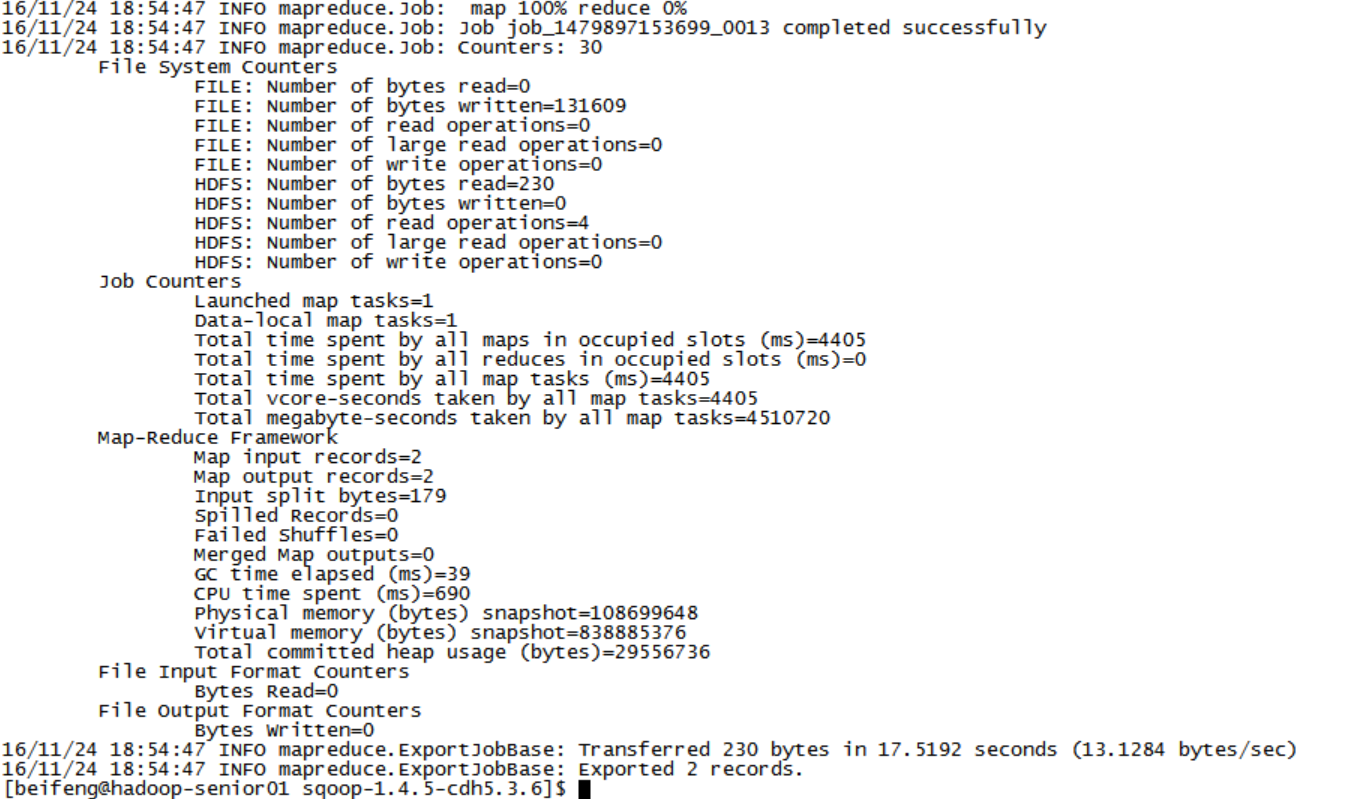
5,使用SQOOP导出分析结果到rdbms数据库
rdbms使用Mysql数据库
DROP DATABASE IF EXISTS db_track ; CREATE DATABASE db_track ; USE db_track ;CREATE TABLE daily_hour_visit( date varchar(255) NOT NULL, hour varchar(255) DEFAULT NULL, pv varchar(255) DEFAULT NULL, uv varchar(255) DEFAULT NULL, PRIMARY KEY(date, hour) ) ;SQOOP EXPORT
bin/sqoop export \ --connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/db_track \ --username root \ --password 123456 \ --table daily_hour_visit \ --num-mappers 1 \ --export-dir /user/hive/warehouse/db_track.db/daily_hour_visit \ --input-fields-terminated-by ‘\t’– Hive中默认的分隔符: \001
这里使用001的时候导入会报错,网上查了一下:这个错误的原因是指定Hive中表字段之间使用的分隔符错误,供Sqoop读取解析不正确,由于此处hive中的数据是由hdfs中导入的,其分隔符是’\t’, 故修改\001为\t的导出语句即可
http://blog.csdn.net/wangmuming/article/details/25296697
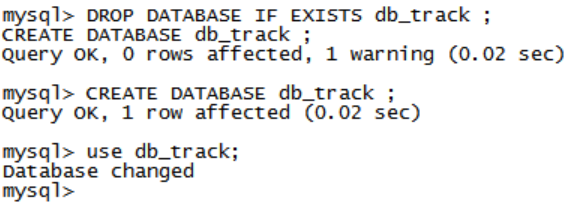
6,动态分区使用
创建业务数据表
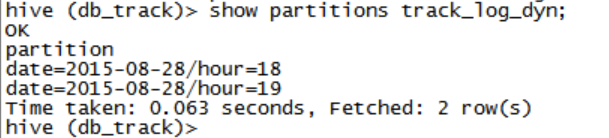
DROP TABLE IF EXISTS track_log_dyn ; CREATE TABLE track_log_dyn( id string, url string, guid string, trackTime string ) PARTITIONED BY (date string, hour string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ;分区表,动态加载
INSERT INTO TABLE track_log_dyn PARTITION (date, hour) SELECT id, url, guid, trackTime, date, hour FROM tmp_track_log ;
-- 配置
-- 1,启动动态分区
-- set hive.exec.dynamic.partition = true ;
-- 2,非严格模式
-- set hive.exec.dynamic.partition.mode = nonstrict ;















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









