







转自: http://blog.csdn.net/PinkRobin/article/details/5456094
今天在学习《程序员使用算法》时,看到了单链表快排序这一节。初看时感觉程序有很大的问题,但是细细品味之后却发现程序设计的极为巧妙,同时又深感自己C语言指针知识之不牢固,特别是指针的指针方面的知识。
单链表的快排序和数组的快排序基本思想相同,同样是基于划分,但是又有很大的不同:单链表不支持基于下标的访问。故书中把待排序的链表拆分为2个子链表。为了简单起见,选择链表的第一个节点作为基准,然后进行比较,比基准大节点的放入左面的子链表,比基准大的放入右边的子链表。在对待排序链表扫描一遍之后,左面子链表的节点值都小于基准的值,右边子链表的值都大于基准的值,然后把基准插入到链表中,并作为连接两个子链表的桥梁。然后根据左右子链表中节点数,选择较小的进行递归快速排序,而对数目较多的则进行跌等待排序,以提高性能。
排序函数中使用的变量如下:
struct node *right; //右边子链表的第一个节点
struct node **left_walk, **right_walk; //作为指针,把其指向的节点加入到相应的子链表中
struct node *pivot, *old; //pivot为基准, old为循环整个待排序链表的指针
核心代码如下:
for (old = (*head)->next; old != end; old = old->next) {
if (old->data < pivot->data) { //小于基准,加入到左面的子链表,继续比较
++left_count;
*left_walk = old; //把该节点加入到左边的链表中,
left_walk = &(old->next);
} else { //大于基准,加入到右边的子链表,继续比较
++right_count;
*right_walk = old;
right_walk = &(old->next);
}
}
head为struct node **类型,指向链表头部,end指向链表尾部,可为NULL,这段程序的重点在于指针的指针的用法,*left_walk为一个指向node节点的指针,说的明白点*left_walk的值就是node节点的内存地址,其实还有一个地方也有node的地址,那就是指向node的节点的next域,故我们可以简单的认为*left_walk = old就是把指向node节点的节点的next域改为节点old的地址,这样可能造成两种情况:一种就是*left_walk本来就指向old节点,这样就没有改变任何改变,另一种则是改变了*right_walk指向节点的前一个节点的next域,使其指向后部的节点,中间跳过了若干个节点,不过在这里这样做并不会造成任何问题,因为链表中的节点要么加入到左面的子链表中,要么加入到右面的子链表中,不会出现节点丢失的情况。
下面用图示说明下上面的问题:
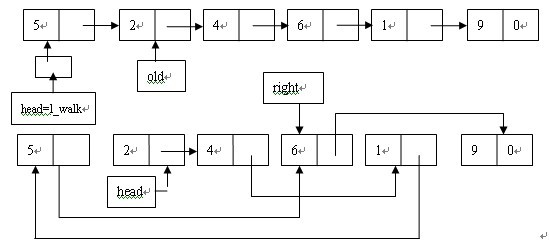
这里假设链表的值一次是5、2、4、6、1。根据程序首先head = left_walk指向值为5的节点,old指向值为2的节点,2小于5,所以加入2到左面的子链表中,*left_walk=old,我们知道,*left_walk指向的是第一个节点,这样做改变了head指针值,使其指向第二个节点,然后left_walk后移,old后移,4同样小于5,故继续上述操作,但是这是*left_walk和old指向的是同一个节点,没有引起任何变化,left_walk和old后移,6大于5,这时不同就出现了,要把其加入到右边的子链表中,故是*right_walk = old,其实right_walk初试化为&right,这句话相当于right = old,即令old当前指向的节点作为右边子链表的第一个节点,以后大于基准的节点都要加入到这个节点中,且总是加入到尾部。此时right_walk,和old后移,1小于5应该加入到左边的子链表中,*left_walk = old,此时*left_walk指向6,故此语句的作用是更改节点4的next值,把其改为1的地址,这样6就从原来的链表中脱钩了,继续left_walk和old后移到9节点,应加入到右边的子链表中,此时*right_walk指向1,故把9节点加入到6节点的后面。
这就是基本的排序过程,然而有一个问题需要搞明白,比如有节点依次为struct node *a, *b, *c,node **p , p = &b,如果此时令*p = c,即实际效果是a->next = c;我们知道这相当于该a的next域的值。而p仅仅是一个指针的指针,它是指向b所指向的节点的地址的指针,那么当我们更改*p的值的时候怎么会改到了a的next呢(这个可以写程序验证下,确实如此)?其实并非如此,我们自习的看看程序,left_walk初始化为head,那么第一次执行*left_walk是把head指向了左边链表的起始节点,然后left_walk被赋值为&(old->next),这句话就有意思了,我们看以看看下面在执行*left_walk=old时的情况,可以简单的来个等价替换,*left_walk = old也就相当于*&(old->next) = old,即old->nex = old,不过这里的old可不一定是old->next所指向的节点,应为left_walk和right_walk都指向它们的old节点,但是却是不同的。
算法到这里并没有完,这只是执行了一次划分,把基准放入了正确的位置,还要继续,不过下面的就比较简单了,就是递归排序个数比较小的子链表,迭代处理节点数目比较大的子链表。
整体代码如下:
- /**
- * 单链表的快排序
- * author :blue
- * data :2010-4-6
- */
- #include <stdio.h>
- #include <stdlib.h>
- #include <time.h>
- //链表节点
- struct node {
- int data;
- struct node *next;
- };
- //链表快排序函数
- void QListSort(struct node **head, struct node *head);
- //打印链表
- void print_list(struct node *head) {
- struct node *p;
- for (p = head; p != NULL; p = p->next) {
- printf("%d ", p->data);
- }
- printf("/n");
- }
- int main(void) {
- struct node *head;
- struct node *p;
- int i = 0;
- /**
- * 初始化链表
- */
- head = (struct node*)malloc(sizeof(struct node));
- head->next = NULL;
- head->data = 0;
- srand((unsigned)time(NULL));
- for (i = 1; i < 11; ++i) {
- p = (struct node*)malloc(sizeof(struct node));
- p->data = rand() % 100 + 1;
- p->next = head->next;
- head->next = p;
- }
- print_list(head);
- printf("---------------------------------/n");
- QListSort(&head, NULL);
- print_list(head);
- return 0;
- }
- void QListSort(struct node **head, struct node *end) {
- struct node *right;
- struct node **left_walk, **right_walk;
- struct node *pivot, *old;
- int count, left_count, right_count;
- if (*head == end)
- return;
- do {
- pivot = *head;
- left_walk = head;
- right_walk = &right;
- left_count = right_count = 0;
- //取第一个节点作为比较的基准,小于基准的在左面的子链表中,
- //大于基准的在右边的子链表中
- for (old = (*head)->next; old != end; old = old->next) {
- if (old->data < pivot->data) { //小于基准,加入到左面的子链表,继续比较
- ++left_count;
- *left_walk = old; //把该节点加入到左边的链表中,
- left_walk = &(old->next);
- } else { //大于基准,加入到右边的子链表,继续比较
- ++right_count;
- *right_walk = old;
- right_walk = &(old->next);
- }
- }
- //合并链表
- *right_walk = end; //结束右链表
- *left_walk = pivot; //把基准置于正确的位置上
- pivot->next = right; //把链表合并
- //对较小的子链表进行快排序,较大的子链表进行迭代排序。
- if(left_walk > right_walk) {
- QListSort(&(pivot->next), end);
- end = pivot;
- count = left_count;
- } else {
- QListSort(head, pivot);
- head = &(pivot->next);
- count = right_count;
- }
- } while (count > 1);
- }














 4914
4914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









