







虚拟机搭建hadoop的全分布式集群-in detail(1)
虚拟机搭建hadoop的全分布式集群-in detail (2)
虚拟机搭建hadoop的全分布式集群-in detail (3)
在以上三篇博客中,在VirtualBox上创建了三个CentOS6.5的虚拟机,作为全分布式Hadoop集群的master节点和slave1节点以及slave2节点, 并设置三个虚拟机之间的SSH无密码登录,在三个虚拟机上安装JDK并设置环境变量。这样Hadoop全分布式集群搭建的准备工作就全部完成了~三个虚拟机的情况如下
| 虚拟机名称 | 主机名 | IP地址 | |
| master节点 | CentOS6.5-Master | Master | 192.168.1.110 |
| slave1节点 | CentOS6.5-Slave1 | Slave1 | 192.168.1.111 |
| slave2节点 | CentOS6.5-Slave2 | Slave2 | 192.168.1.112 |
下面在三个虚拟机上部署Hadoop的master和slave节点。之前已经在三个虚拟机上创建了名为sunnie的普通用户。部署和配置过程参考http://www.linuxidc.com/Linux/2014-05/101687.htm
Hadoop下载地址hadoop-1.2.1.tar.gz
以用户sunnie的身份登录主机Master.
将下载下来的hadoop-1.2.1.tar.gz拷贝到/home/sunnie/Documents/目录下并解压
在/home/sunnie/Documents/hadoop-1.2.1/下创建一个新的目录tmp
接下来分别配置hadoop-env.sh, core-site.xml, hdfs-site.xml, mapred-site.xml, masters, slaves文件。
vim /home/sunnie/Documents/hadoop-1.2.1/conf/hadoop-env.sh
在最后追加export JAVA_HOME=/usr/java/jdk1.8.0_05
vim /home/sunnie/Documents/hadoop-1.2.1/conf/core-site.xml
在core-site.xml中配置Name Node的IP和端口,设置fs.default.name的值,改为如下内容
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/sunnie/Documents/hadoop-1.2.1/tmp</value>
</property>
</configuration>
接下来修改 hdfs-site.xml
vim /home/sunnie/Documents/hadoop-1.2.1/conf/hdfs-site.xml
改为如下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
下面修改mapred-site.xml
vim /home/sunnie/Documents/hadoop-1.2.1/conf/mapred-site.xml
在mapred-site.xml中配置Job Tracker的IP和端口,设置mapred.job.tracker的值,改为如下内容
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>
</property>
</configuration>
下面分别配置masters和slaves
vim /home/sunnie/Documents/hadoop-1.2.1/conf/masters
将文件中localhost去掉,换成
Master
vim /home/sunnie/Documents/hadoop-1.2.1/conf/slaves
将文件中的localhost去掉,换成
Slave1
Slave2
这样,主机Master上的Hadoop就配置完成了,下面要做的是将Master上的hadoop-1.2.1分别拷贝到Slave1和Slave2
首先在主机Slave1和主机Slave2上以用户sunnie的身份登录
在主机Master上执行
scp -r /home/sunnie/Documents/hadoop-1.2.1 sunnie@Slave1:/home/sunnie/Documents
scp -r /home/sunnie/Documents/hadoop-1.2.1 sunnie@Slave2:/home/sunnie/Documents
至此,Hadoop全分布式集群在三台虚拟机上的部署就完成了,下面来测试下~
首先分别在三个主机上以root用户的身份关闭防火墙
chkconfig iptables off
然后在三个主机上都切换回用户sunnie
在Master主机上执行
/home/sunnie/Documents/hadoop-1.2.1/ bin/hadoop namenode -format
/home/sunnie/Documents/hadoop-1.2.1/ bin/start-all.sh
然后在主机Master上执行jps命令,可以看到
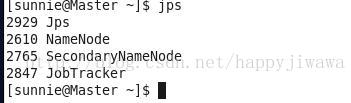
然后在Slave1上执行jps命令,可以看到

在Slave2上执行jps, 可以看到

最后在Master上执行
/home/sunnie/Documents/hadoop-1.2.1/ bin/stop-all.sh
可以看到
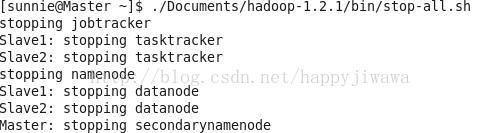
至此,用三个CentOS6.5虚拟电脑部署Hadoop1.2.1全分布式集群就大功告成了~














 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









