







 本文深入探讨了ReLU在深度学习中的重要性,解释了它如何克服sigmoid的梯度消失问题。作者介绍了Leaky ReLU及其改进版Parametric ReLU (PReLU),并强调了PReLU在神经网络初始化方法上的贡献,该方法使得更深的网络能够有效训练。实验结果显示,PReLU在深层网络中的优化性能优于传统方法。
本文深入探讨了ReLU在深度学习中的重要性,解释了它如何克服sigmoid的梯度消失问题。作者介绍了Leaky ReLU及其改进版Parametric ReLU (PReLU),并强调了PReLU在神经网络初始化方法上的贡献,该方法使得更深的网络能够有效训练。实验结果显示,PReLU在深层网络中的优化性能优于传统方法。
本期要讲的是来自MSRA的何恺明的论文《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》,这篇论文是首次公开宣布图像的识别率超越人类水平的文章,其象征性意义确实巨大,论文出炉时也有很多报道,但我们今天不谈这些,只关注其技术细节。
一、Sigmoid,ReLU与Leaky ReLU
1、ReLU的引入
这几年的神经网络,尤其是卷积神经网络取得如此巨大的成功,受到很多人的不解:我看现在这些网络结构跟90年代的LeNet没有什么不同,为什么现在“突然”就引来了一轮革命?纵然有计算机性能上的巨大提升,GPU的应用使得我们可以在短时间内得到一个庞大的模型,难道在算法上就没有本质变化吗?
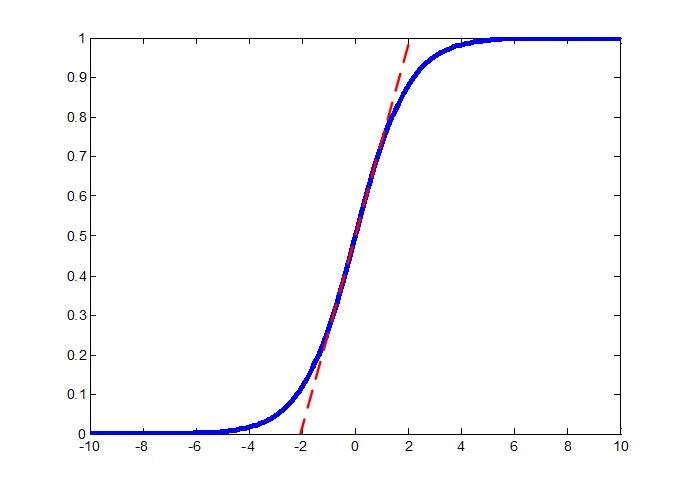
答案是有的,有一些虽然不起眼,但其实是质变的技术引领了这次变革,其中首推的就是ReLU(Rectified Linear Units)。传统的神经元模型使用的激活函数是sigmoid,它是从神经科学上边仿生过来的,用它来模拟神经元从受到刺激,接收到的电信号超过一定的阈值就产生兴奋这个特性确实是很恰当的,在神经网络的第二波浪潮中也确实解决了很多问题,然而它有一个严重的问题就是其容易产生饱和效应,也称梯度弥散效应,就是在sigmoid函数的两侧是平的(下图所示,抱歉我把上期的图拿来了),即梯度非常小,在一个深层的神经网络模型中,有很多神经元的都是在这个函数的两边,这就使得梯度累加起来的和在反向传播的过程中会越来越小,在上一期我们也做过实验,梯度确实会越来越小,导致前边几层根本无法得到有效地训练,之前大牛们也想过一些办法,例如只使用梯度的符号进行迭代,但这是个治标不治本的办法。
ICCV2009上Lecun组发表了一篇文章《What is the Best Multi-Stage Architecture for Object Recognition?》,窃以为应当列为深度学习奠基性文章之一,这篇文章使用的激活函数 y=abs(x) 已经非常接近ReLU了,而且在介绍其激活函数的时候有这么一句:Several rectifying non-linearities weretried, including the positive part, and produced similar results. 这实际上就是现在使用最多的ReLU了,只是他们在Cifar这种小数据集上做的实验发现二者性能相当。实际上,深层神经网络的数学本质是“使用多层的非线性函数逼近任意非线性函数”,我们需要的实际上只是一个非线性函数而已,为何要使用sigmoid、tanh这类还需要计算指数、三角函数的复杂函数呢?因此, abs(x) 、 max(x,0) 这类函数进入了研究人员的视线,对于计算机来说,计算它们只需要动动符号位,而且它们的梯度很简单,就是1或者-1或者0,不论传播多少层,其梯度和都会维持在一个相对稳定的数量级上,这样就解决了纠结了10余年的梯度弥散问题。
2、ReLU的几何意义
说了这么半天ReLU对神经网络产生的深远影响,实际上ReLU神经元的数学表达式非常简单:
画成图就是(左图,右图为Leaky ReLU):
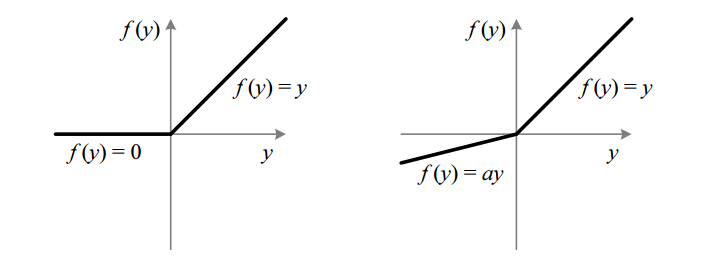
这样的一个激活函数对数据会产生什么样的影响呢?注意到, Wx+b=0 是一个超平面,在这个超平面的两侧, x 受到了不同的对待:

下方的数据点被推向横轴,左侧的数据点被推向了纵轴,形成了两条数据非常密集的直线(高维上就是超平面)。注意上图中,两个 Wx+b 被画成了正交的,通常在一个训练好的神经网络模型中,它们并不是正交的。非正交的情况、高维的情况需要读者自行想象。
上图说明,只有一个象限(抱歉我不知道高维空间里面这个词叫什么,还是就叫象限吧)的信息被保留了,而其他象限的信息被不同程度地压缩了,而且压缩幅度非常大,使其完全无法恢复。这其实是非常不合理的,也许这里仍旧有一些可以加以区分的信息被压缩没了,当然,这些信息在其他卷积核中也许会有所体现,但这样断绝一切可能性的做法并不可取,因此便有了Leaky ReLU的想法。
3、Leaky ReLU
Leaky ReLU的数学表达式如下:
在负半轴加了一个斜率 α ,不再是直接压缩至0了,而是将负数部分压缩 α 倍,表现在图形上就是:

这样,既起到了修正数据分布的作用,又不一棍打死,在后面几层需要负轴这边信息的时候不至于完全无法恢复。
二、Parametric ReLU
1、计算过程
在这篇论文出现之前,已经有人对Leaky ReLU进行了探索,CAFFE上也早已有了相关的实现,但一般都是指定 α 的值,例如0.1或者0.2,之前Kaggle上的CIFAR-10竞赛,冠军就用了类似的黑科技(链接)。然而可以观察到,损失函数对 α 的导数我们是可以求得的,可不可以将它作为一个参数进行训练呢?这篇论文指出,不仅可以训练,而且效果更好。
公式非常简单,反向传播至未激活前的神经元的公式就不写了,很容易就能得到。对 α 的导数如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









