







LevelDB源码阅读(1)
时间就是杀猪刀,不抓紧学习不行呀。2017年新年第一天,我们就来学习一下LevelDB吧。之所以选它,是因为代码还不算多(1.19版本):
...
51./util/testutil.cc
63./util/testutil.h
15805 total
[root@localhost src]#
我们先看看目录结构:
| # | Path | Description |
| 1 | db | 库相关的代码 |
| 2 | include | 头文件 |
| 3 | port | 移植相关的代码 |
| 4 | table | 表相关的代码 |
| 5 | util | 工具函数等 |
我们先看看最主要的DB类,其实就是一个接口,真正的实现实在DBImpl中。DB类定义的主要方法是:Open,Put, Delete, Write, Get, NewIterator, GetSnapshot, ReleaseSnapshot等。我们找一个Open来看看:
Status Open(const Options& options, conststring& dbname, DB** dbptr);
输入参数是打开的选项,数据库的名字以及要传出的数据库指针,而返回的是结果状态。我们来逐个分析一下这几个参数:
Options类主要成员:
| # | Name | Description |
| 1 | Comparator | 用于Key的比较,提供不同的key比较方法还是有必要的。它的主要实现方法就是Compare,比较两个Slice(带长度字符数组) |
| 2 | create_if_missing | 例如这个标记就是说,如果数据库不存在时候怎么办,是创建一个新的还是报错。 |
| 3 | … … | 一些其他标记,在出问题的时候,确定怎么做的。 |
| 4 | Env | 封装了和环境的交互,环境就是运行时和外界的交互。一般和操作系统的交互,例如: 文件操作 目录操作 线程操作 时间操作 等等,这些操作在不同的操作系统间可能是不同的。 |
| 5 | Logger | 写日志的 |
| 6 | Cache | 数据块的缓存,当然这个Cache可以存储任何的对象指针。 |
| 7 | CompressionType | 压缩类型 |
| 8 | FilterPolicy | 过滤文件用的过滤器,用于判断Key是否在一个文件中。未来可以有更高效的实现,例如布隆过滤器。 |
Status是封装了状态和描述,用于函数一次性返回错误代码以及相关的描述。居然Status也是使用一个字符数组来容纳code和msg的,难道是为了将来序列化方便?还是作者习惯了。
| 0-3 | 4 | 5-… |
| 长度(uint32) | Code(难道代码只有256种?) | 代码的描述字符串 |
接着我们看一下DB的实现类DBImpl的情况(关键信息):
| # | Name | Description |
| 1 | TableCache |
|
| 2 | Memtable *mem |
|
| 3 | Memtable *imm |
|
| 4 | WritableFile *logfile |
|
| 5 | Logfile number |
|
| 6 | Writer * writers |
|
| 7 | VersionSet *versions |
|
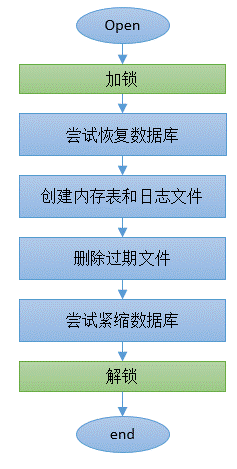
打开数据库Open:
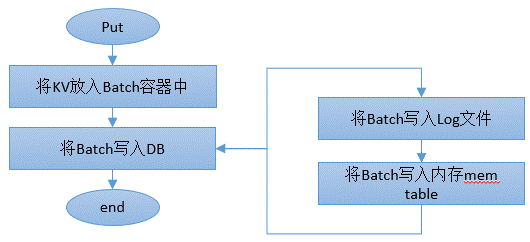
写入一个KV(Put):
很显然,所有的写都是通过批量方式写入到库中的(单一的KV也是放入Batch中然后再写),估计Batch是一个类似事务的概念,应该是确保一次性的写入吧,并且保证性能比较好。那我们看看WriteBatch是个什么容器:
| # | Name | Description |
| 1 | Put() | 放入一个KV |
| 2 | Delete() | 删除一个KV |
| 3 | Clear() | 清除所有的KV |
| 4 | string rep_ | 注意,这里就是所有的容器存储了。难道为了提高内存利用率?居然使用了紧缩的内存实现。所有的KV都按照一定的编码格式放入一个字符数组中了。这个数组的结构如下: { “sequence” : “int64”, “count” : “int32”, “records” : [ { “TypeKeyValue” : “int8”, “KeyLength” : “vint”, “KeyData” : “char[]”, “ValueLength” : “vint”, “ValueData” : “char[]” }, { “TypeDeletion” : “int8”, “KeyLength” : “vint”, “KeyData” : “char[]” }, ] } 注意,上述的vint,实际上是变长的数字,小于127的,占用1byte,大于127的,占用2byte(第一个字节的高位为1),一次类推。这样大部分都是小于127的key,就不用占用太多长度字节了。
这么做的好处是,避免了大量的内存分配操作。而且紧密。缺点是引入了编解码的性能损耗。 |
这个WriteBatch的数据组装是由一个WriteBatchInternal类的静态方法来实现的,这样WriteBatch就不会混杂有具体的格式实现代码了。未来如果想修改一下数据组织格式,直接写一个WriteBatch就可以了。写入KV的整体流程如下:
查询一个KV(Get):

今天先简单浏览一下整个工程,后面我们仔细的检查一下每一个具体的方面。














 7810
7810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









