







首先要用到的软件有jdk跟hadoop包
jdk下载:http://pan.baidu.com/s/1sjt36yx
hadoop包下载:http://pan.baidu.com/s/1c0nOxYo
1、先把这2个文件下载好放到linux系统下
(ps:虚拟机不会传文件的看这里http://blog.csdn.net/hawkoyates/article/details/44277467)
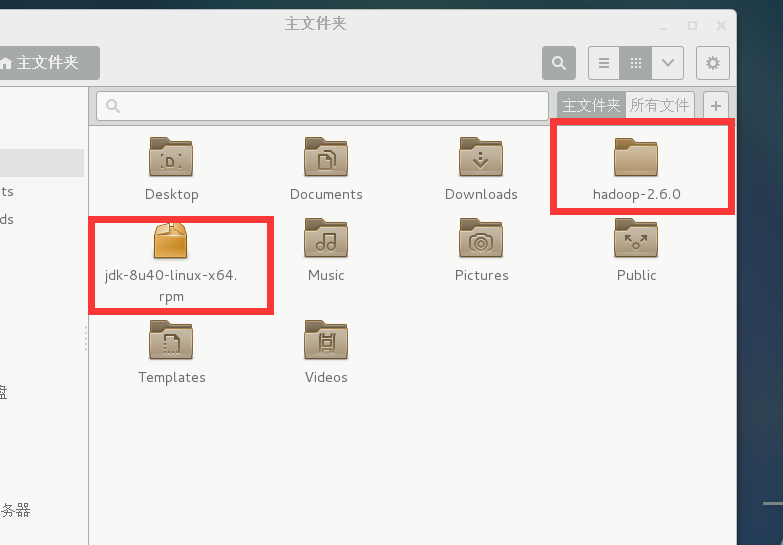
2、安装jdk
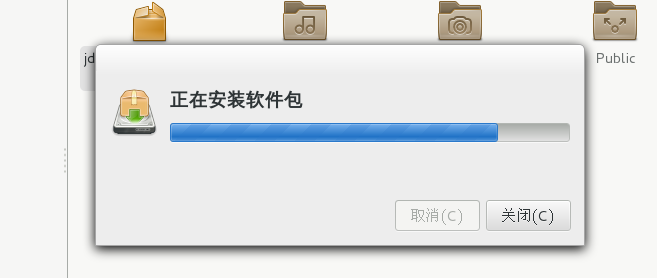
直接打开安装,这里如果不是超管登录的话要输入超管密码安装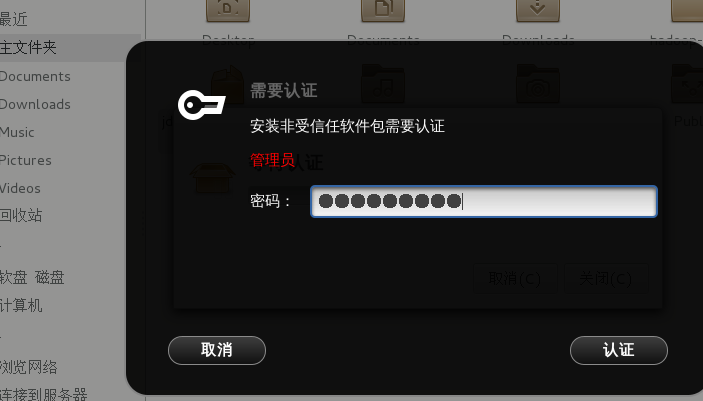
3、配置hadoop下的环境变量(包括jdk)
这里jdk默认安装的位置是/usr/java/
现在配置hadoop环境 首先找到hadoop-2.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6243
6243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









