







To All Of You:
一个人在接受科技教育时能得到的最珍贵的收获是能够终身受用的通用智能工具。
在讨论算法的书籍中,一般会采用两种方案中的一种:
1.第一种方案是按照问题的类型对算法进行分类。这类教材安排了不同的章节分别讨论排序,查找,图等算法。这种做法的优点是,对于解决同一问题的不同算法,它能够立即比较这些算法的效率。其缺点在于,由于过于强调问题的类型,它忽略了对算法设计技术的讨论。
2.第二种方案围绕着算法设计技术来组织章节。在这种结构中,即使算法来自于不同的计算领域,如果它们采用相同的设计技术,就会被编成一组。
第一章:绪论
1.1什么是算法
为了阐明算法的概念,本节将以三种方法为例来解决同一个问题,即计算两个整数的最大公约数。这些例子会帮助我们阐明以下要点:
1.算法的每一个步骤都必须没有歧义,不能有半点儿含糊
2.必须认真确定算法所处理的输入的值域
3.同一算法可以用几种不同的形式来描述
4.同一问题,可能存在几种不同的算法
5.针对同一问题的算法可能基于完全不同的解题思路,而且解题速度也会有显著不同
用于计算gcd(m,n)的欧几里得算法:
1.如果n=0,返回m的值作为结果,同时过程结束;否则进入第二步
2.m除以n,将余数赋给r
3.将n的值赋给m,将r的值赋给n,返回第一步
1.2算法问题求解基础
对于一些算法,证明正确是非常简单的,对于一些复杂的算法,一般采用的正确方法是数学归纳法。
我们希望算法具有一些好的特性:
1.正确性
2.时间效率
3.空间效率
4.简单性
5.一般性
一般性包含两层意思:1.算法所解决问题的一般性2.算法所接受输入的一般性。
第四章:减治法
减治(decrease-and-conquer)技术利用了一个问题给定实例的解和同样问题较小实例的解之间的某种关系。一旦建立了这种关系,我们既可以从顶到下(递归),也可以从底向上(迭代)来运用这种关系。
减治法有三种主要的变化形式:
1.减去一个常量
2.减去一个常量因子
3.减去的规模是可变的
在减常量(decrease-by-a-constant)变化形式中,每次迭代总是从实例中减去一个相同的常量。一般来说,这个常量等于1(T(n)变为T(n-1)),但减其他的常量也偶尔出现。
减常因子(decrease-by-a-constant-factor)意味着在算法的每次迭代中,总是从实例的规模中减去一个相同的常数因子。在大多数情况下,常数因子等于2(T(n)变为T(N/2))。
减可变规模(variable-size-decrease)变化形式中,每次迭代时,规模减小的模式是不同的。例如:gcd(m,n) = gcd(n,m mod n)。
4.1插入排序
如何利用减一技术对一个数组排序?假设前面n-1个数已经有序,然后构造出n个有序的数。插入排序啊!
4.2拓扑排序
复习图:邻接矩阵和邻接链表仍然是两种表示图的主要手段。
用这两种方法表示时,无向图和有向图只有两个显著的差异:
1.有向图的邻接矩阵不一定表现出对称性
2.有向图的一条边在图的邻接表中只有一个相应的节点(不是两个)
一个五门必修课的集合{c1,c2,c3,c4,c5},学生必须在某个阶段修完这几门课程。可以按照任何次序学习这些课程,只要满足下面的条件:c1,c2没有任何条件,修完c1和c2才能修c3,修改c3才能修c4,而修完c3和c4才能修c5.应该按照什么顺序来学习这些课程呢?
这种状况可以用一个图来建模,它的节点代表课程,有向边表示先决条件。如图:
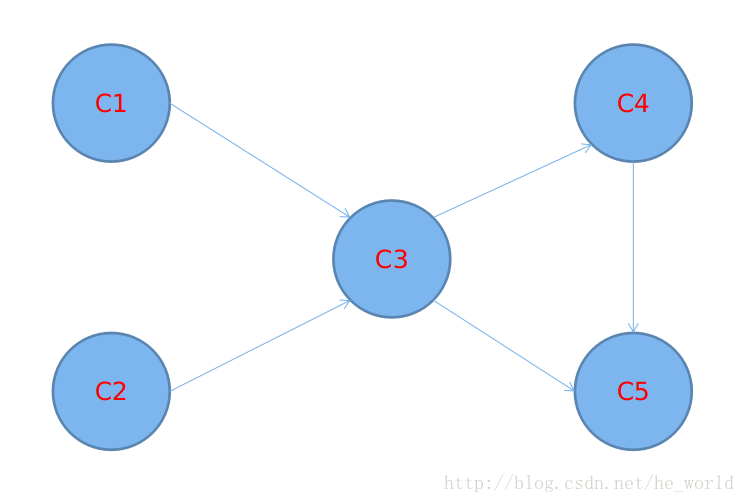
问题转换:就上面的问题,其实是说,是否可以按照一种序列列出它的顶点,使得对于图中每一条边来说,边的初始起点总是排在边的结束顶点之前。这个问题叫拓扑排序!
为了使拓扑排序成为可能,无环有向图不仅是必要条件,而且是充分条件。也就是说,如果一个图没有回路,对它来说,拓扑排序是有解的。
1.第一种算法是深度优先查找的一个简单应用:执行一次DFS遍历,并记住顶点变成死端(即退出)的顺序。将该次序反过来就得到拓扑排序的一个解,当然,在拓扑排序时不能遇到回边。
这个算法为什么有效呢?当一个顶点v退出DFS栈时,在比v更早出栈的顶点中,不可能存在顶点u拥有一条从u到v的边(否则,(u,v)是一条回边)。所以,在退栈的队列中,任何这样的顶点u都会排在v的后面,并且在逆序队列中会排在v的前面。
2.第二种算法基于减一技术的一个直接实现:不断地做这样一件事,在余下的有向图中求出一个源(source),它是一个没有输入边的顶点,然后把它和所有从它出发的边都删除。(如果有多个源,可以任意选择一个。如果这样的源不存在。算法停止,因为该问题无解)。顶点被删除的次序就是拓扑排序问题的一个解。
4.3生成组合对象的算法
组合对象中最重要的类型就是排列,组合和给定集合的子集。
1.生成排列:
通过使用移动元素(务必了解这个概念)这个概念,我们可以给出所谓的Johnson-Trotter算法的描述,它算是用来生成排列最有效的方法了。伪代码如下:
算法 Johnson-Trotter(n)
//实现用来生成排列的Johnson-Trotter算法
//输入:一个正整数
//输出:{
1,2,...,n}的所有排列的列表
将第一个排列初始化为1,2,...,n(头部箭头都向左)
while 存在一个移动元素 do
求最大的移动元素k
把k和它箭头指向的相邻元素互换
调转所有大于k的元素的方向
将新排列添加到列表中有人说Johnson-Trotter算法生成的排列的次序不是非常自然。例如排列n,n-1,…1的自然位置应该是列表的最后一个。将排列按照升序排列,这样被称为字典序。下面是实现字典序的伪代码:
算法 LexicographicPermute(n)
//以字典序生成排列
//输入:一个正整数n
//输出:{
1,2,...,n}的所有排列的列表
初始化第一个排列为1,2,...,n
while 最后一个排列有两个连续升序的元素 do
找出使得a(i)<a(i+1)的最大的i //a(i+1)>a(i+2)>...>a(n)
找到使得a(i)<a(j)的最大索引j //j>=i+1,因为a(i)<a(i+1)
交换a(i)和a(j) //a(i+1)到a(n)仍保持降序
将a(i+1)到a(n)的元素反序
将这个新排列添加到列表中2.生成子集:
有一个直接解决该问题的简洁方法,它是基于这样一种关系:n个元素集合A={a1,a2,…,an}的所有2的n次方个子集和长度为n的所有2的n次方个位串之间的一一对应关系。
下面是递归生成二进制反射格雷码的伪代码:
算法 BRGC(n)
//递归生成n位的二进制反射格雷码
//输入:一个正整数n
//输出:所有长度为n的格雷码位串列表
if n=1 ,表L包含位串0和1
else 调用BRGC(n-1)生成长度为n-1的位串列表L1
把表L1倒序后复制给表L2
把0加到L1中每个位串的前面
把1加到L2中每个位串的前面
把表L2添加到表L1后面得到表L
return L要注意的是,二进制反射格雷码是循环的:它的最后一个位串与第一个位串只相差一位;对于中间的生成码,之间也只相差一位。
4.4减常因子算法
1.折半查找
2.假币问题
3.俄式乘法
该乘法的思想:
//n为偶数
n*m = (n/2)*2m
//n为奇数
n*m = (n-1)/ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1730
1730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









